Command Palette
Search for a command to run...
PipeTransformer : Pipeline Élastique Automatisé Pour La Formation De Modèles Distribués À Grande Échelle

Titre de l'article :
PipeTransformer : Pipelining élastique automatisé pour la formation distribuée de modèles à grande échelle
Pipeptransformer utilise des pipelines élastiques automatisés pour effectuer une formation distribuée efficace des modèles Transformer. Dans PipeTransformer, nous concevons un algorithme de gel dynamique adaptatif qui peut identifier et geler progressivement certaines couches pendant la formation, et un système de pipeline flexible qui peut allouer dynamiquement des ressources pour former les couches actives restantes.
Plus précisément, PipeTransformer exclut automatiquement les couches gelées du pipeline, regroupe les couches actives dans moins de GPU et se ramifie avec plus de répliques pour augmenter la largeur parallèle des données.
Les évaluations sur ViT (en utilisant l'ensemble de données ImageNet) et BERT (en utilisant les ensembles de données SQuAD et GLUE) montrent que PipeTransformer atteint une accélération jusqu'à 2,83 fois supérieure par rapport aux lignes de base de pointe sans aucune perte de précision.
Le document comprend également une variété d’analyses de performances pour aider les utilisateurs à acquérir une compréhension plus complète de l’algorithme et de la conception du système.
Ensuite, cet article présentera en détail le contexte de la recherche, la motivation, les idées de conception, les solutions de conception du système et comment implémenter l'algorithme et le système à l'aide de l'API distribuée PyTorch.
Introduction

Les modèles de grands transformateurs ont réalisé des avancées en matière de précision, tant dans le traitement du langage naturel que dans la vision par ordinateur. GPT-3 établit de nouveaux records de haute précision pour la plupart des tâches PNL. Dans ImageNet, Vision Transformer (ViT en abrégé) a également atteint une précision de premier ordre de 89%, surpassant les réseaux convolutifs les plus avancés ResNet-152 et EfficientNet.
Pour résoudre le problème de l'augmentation constante de la taille des modèles, les chercheurs ont proposé diverses techniques de formation distribuées, notamment les serveurs de paramètres, le parallélisme des pipelines, le parallélisme intra-couche et le parallélisme des données à redondance zéro.
Cependant, les solutions de formation distribuées existantes ne sont que des scénarios de recherche, et tous les poids du modèle doivent être optimisés pendant le processus de formation (c'est-à-dire que les frais de calcul et de communication doivent rester relativement stables pendant les différentes itérations). Des recherches récentes sur l’entraînement progressif montrent que les paramètres d’un réseau neuronal peuvent être entraînés de manière dynamique :
- Analyse de corrélation canonique à vecteur singulier pour la dynamique et l'interprétabilité de l'apprentissage en profondeur. NeurIPS 2017
- Formation efficace de BERT par empilement progressif. ICML 2019
- Accélération de la formation des modèles de langage basés sur des transformateurs avec suppression progressive des couches. NeurIPS 2020
- Sur la croissance du transformateur pour la formation progressive BERT. NACCL 2021

Figure 2 : Formation gelée interprétable : convergence ascendante DNN (en utilisant ResNet pour tester les résultats sur CIFAR10) Chaque volet montre la similarité de chaque couche via SVCCA
Par exemple, dans l’entraînement gelé, les réseaux neuronaux convergent généralement de bas en haut (c’est-à-dire que toutes les couches n’ont pas besoin d’être entraînées pour obtenir certains résultats).
La figure ci-dessus montre un exemple de la manière dont les poids se stabilisent au cours du processus d’entraînement en utilisant une approche similaire. Sur cette base,Nous exploitons la formation gelée pour effectuer une formation distribuée des modèles Transformer, accélérant la formation en allouant dynamiquement des ressources pour se concentrer sur un ensemble réduit de couches actives.
Cette stratégie de gel des couches est particulièrement adaptée au parallélisme des pipelines, car l'exclusion des couches inférieures consécutives du pipeline peut réduire les frais de calcul, de mémoire et de communication.
Figure 3 : Le processus de pipeline automatisé et flexible de PipeTransformer accélère la formation distribuée des modèles Transformer
PipeTransformer est un framework d'accélération de formation de pipeline flexible qui réagit automatiquement aux couches gelées en transformant dynamiquement la portée des modèles de pipeline et le nombre de répliques de pipeline.
À notre connaissance, il s’agit du premier article à étudier le gel des couches dans le contexte de la formation en pipeline et en parallèle des données.
La figure 3 illustre les avantages de cette combinaison.
Tout d’abord, en excluant les couches gelées du pipeline, le même modèle peut être regroupé dans moins de GPU, ce qui entraîne moins de communication entre GPU et des bulles de pipeline plus petites.
Deuxièmement, après avoir regroupé le modèle sur moins de GPU, le même cluster peut accueillir davantage de répliques de pipeline, augmentant ainsi la largeur du parallélisme des données.
Plus important encore, les deux avantages sont multiplicatifs plutôt qu’additifs, accélérant ainsi davantage la progression de la formation.
La conception de PipeTransformer fait face à quatre défis majeurs.
Premièrement, l’algorithme de gel doit prendre des décisions de gel dynamiques et adaptatives ; Cependant, les travaux existants ne fournissent qu'un outil d'analyse post hoc.
Deuxièmement, l’efficacité du repartitionnement du pipeline est affectée par de nombreux facteurs, notamment la granularité des partitions, la taille d’activation inter-partitions et le nombre de mini-lots, ce qui nécessite un raisonnement et une recherche dans un espace de solution plus large.
Ensuite, pour introduire dynamiquement des répliques de pipeline supplémentaires, PipeTransformer doit surmonter la nature statique de la communication collective et éviter les protocoles de messagerie interprocessus potentiellement complexes (un pipeline ne peut être géré que par un seul processus) lorsque de nouveaux processus sont mis en ligne.
Enfin, le cache peut économiser du temps pour la propagation répétée des couches gelées, mais il doit être partagé entre les pipelines existants et les pipelines nouvellement ajoutés car le système ne peut pas créer et réchauffer un cache dédié pour chaque réplique.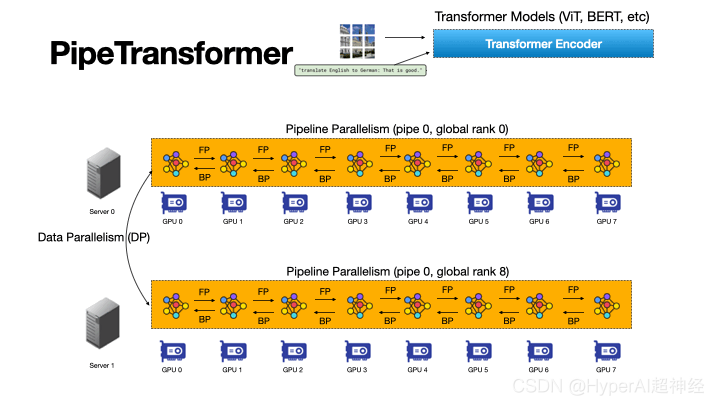
Figure 4 : Schéma de la dynamique de PipeTransformer
Comme le montre la figure 4, afin de relever les défis ci-dessus,La conception de PipeTransformer se compose de quatre blocs de construction principaux.
Le premier est un algorithme adaptatif réglable qui génère des signaux qui guident la sélection des couches gelées à différentes itérations (algorithme de gel). Une fois déclenché par ces signaux, le module de pipeline élastique (AutoPipe) regroupe les couches actives restantes dans moins de GPU en évaluant les changements dans les tailles d'activité et les charges de travail des partitions hétérogènes (couches gelées et actives).
Ensuite, sur la base des résultats d’analyse précédents de différentes longueurs de pipeline, un mini-lot est décomposé en une série de micro-lots de meilleure qualité.
Le module suivant, AutoDP, génère des copies de pipeline supplémentaires pour occuper les GPU libérés et maintient des groupes de processus de communication hiérarchiques pour obtenir une appartenance dynamique pour la communication collective.
Le dernier module, AutoCache, partage efficacement les activations entre les processus parallèles de données existants et nouvellement ajoutés et remplace automatiquement le cache obsolète lors des transformations.
En général, PipeTransformer combine l'algorithme de gel, les modules AutoPipe, AutoDP et AutoCache pour fournir une accélération significative de la formation.
Nous évaluons PipeTransformer avec les modèles ViT (en utilisant l'ensemble de données ImageNet) et BERT (en utilisant les ensembles de données SQuAD et GLUE) et montrons que PipeTransformer atteint une accélération jusqu'à 2,83 fois supérieure par rapport aux lignes de base de pointe sans aucune perte de précision.
Nous fournissons également diverses analyses de performances pour aider les utilisateurs à acquérir une compréhension plus complète des conceptions algorithmiques et systémiques. Enfin, nous avons développé une API flexible open source pour PipeTransformer qui fournit une séparation claire entre les algorithmes de gel, la définition du modèle et l'accélération de la formation, permettant la migration vers des algorithmes qui nécessitent des stratégies de gel similaires.
Conception globale
Supposons que notre objectif soit de former un modèle à grande échelle dans un système de formation distribué. Ce système combine le parallélisme du modèle de pipeline et le parallélisme des données et peut être utilisé pour gérer les scénarios suivants :
Le modèle ne peut pas tenir dans la mémoire d'un seul périphérique GPU, ou la taille du lot est suffisamment petite pour éviter de manquer de mémoire. Plus précisément, les paramètres définis sont les suivants :
- Tâches de formation et définitions de modèles. Modèles de transformateurs de train (tels que Vision Transformer, BERT, etc.) sur des ensembles de données d'images ou de texte à grande échelle. Le modèle Transformer mathcalF comporte un total de L couches, où la i-ème couche est constituée d'une fonction de calcul direct fi et d'un ensemble de paramètres correspondants.
- Infrastructures de formation. Supposons que l’infrastructure de formation se compose d’un cluster GPU avec N serveurs GPU (c’est-à-dire des nœuds). Chaque nœud possède 1 GPU. Le cluster est homogène, ce qui signifie que la configuration matérielle de chaque GPU et serveur est identique. La capacité mémoire de chaque GPU est MGPU. Les serveurs sont connectés les uns aux autres via des interfaces réseau à large bande passante telles qu'InfiniBand.
- Parallélisme des pipelines. Dans chaque machine, nous chargeons un modèle F dans un pipeline avec K partitions (K représente également la longueur du pipeline). La k-ième partition est constituée de Pk couches consécutives. Supposons que chaque partition soit traitée par un périphérique GPU. 1≤K≤I signifie que nous pouvons créer plusieurs pipelines pour plusieurs répliques de modèles sur un seul appareil.
Supposons que tous les périphériques GPU d'un pipeline appartiennent à la même machine, que le pipeline est un pipeline synchrone, qu'aucun gradient expiré n'est impliqué et que le nombre de micro-lots est M. Dans le système d'exploitation Linux, chaque pipeline est géré par un processus. Pour plus de détails, voir GPipe.
- Parallélisme des données. DDP est un groupe de traitement parallèle de données distribuées entre machines à l'intérieur des travailleurs parallèles R. Chaque Worker est une copie du pipeline (un processus unique). L'index (ID) du rème Travailleur est le rang r.
Pour deux pipelines dans DDP, ils peuvent appartenir au même serveur GPU ou à des serveurs GPU différents, et peuvent également échanger des gradients avec l'algorithme AllReduce.
Dans ces cas, notre objectif est d’accélérer la formation en tirant parti de la formation gelée, ce qui élimine le besoin de former toutes les couches pendant tout le processus de formation.
De plus, cela permet d'économiser les calculs, la communication, la perte de mémoire et, dans une certaine mesure, d'éviter le surapprentissage causé par le gel continu des couches.
Cependant, pour profiter de ces avantages, les quatre défis mentionnés ci-dessus doivent être surmontés, à savoir la conception d'un algorithme de gel adaptatif, le repartitionnement dynamique du pipeline, la réallocation efficace des ressources et la mise en cache interprocessus.
Figure 5 : Présentation du système de formation PipeTransformer
PipeTransformer co-conçoit un algorithme de gel instantané et un système de formation automatique de pipeline élastique qui peut transformer dynamiquement la portée des modèles de pipeline et le nombre de répliques de pipeline. L’architecture globale du système est illustrée dans la figure 5.
Pour prendre en charge le pipeline flexible de PipeTransformer, nous maintenons une version personnalisée de PyTorch Pipeline. Pour le parallélisme des données, nous utilisons PyTorch DDP comme base de référence. D'autres bibliothèques sont des mécanismes standards du système d'exploitation (comme le multitraitement), ce qui élimine également le besoin de logiciels ou de matériel personnalisés.
Pour garantir la polyvalence du framework, nous découplons le système de formation en quatre composants principaux : l'algorithme de gel, AutoPipe, AutoDP et AutoCache.
L'algorithme de gel (gris) échantillonne les métriques de la boucle d'entraînement et prend des décisions de gel couche par couche, qui sont partagées avec AutoPipe (vert).
AutoPipe est un module de pipeline flexible qui accélère la formation en excluant les couches gelées du pipeline et en regroupant les couches actives sur moins de GPU (rose), réduisant ainsi la communication entre GPU et réduisant les blocages de pipeline.
AutoPipe transmet ensuite les informations de longueur du pipeline à AutoDP (violet), qui génère ensuite davantage de copies de pipeline lorsque cela est possible pour augmenter la largeur du parallélisme des données.
La figure comprend également un exemple où AutoDP introduit une nouvelle réplique (en violet). AutoCache (contour orange) est un module de cache inter-pipelines. Pour des raisons de lisibilité et de généralité, l’architecture du code source reste cohérente avec la figure 5.
Implémentation à l'aide de l'API PyTorch
Comme le montre la figure 5, PipeTransformer se compose de quatre composants : Freeze Algorithm, AutoPipe, AutoDP et AutoCache.
Parmi eux, AutoPipe et AutoDP dépendent respectivement de PyTorch DDP (torch.nn.parallel.DistributedDataParallel) et du pipeline (torch.distributed.pipeline).
Dans ce blog, nous soulignons uniquement les principaux détails d’implémentation d’AutoPipe et d’AutoDP. Pour plus d'informations sur l'algorithme de gel et AutoCache, consultez l'article.
AutoPipe : Pipeline flexible
AutoPipe peut accélérer la formation en excluant les couches gelées du pipeline et en compactant les couches actives sur moins de GPU.Cette section détaille les composants clés d'AutoPipe :
1) Pipeline de partitionnement dynamique ;
2) Réduire le nombre d’équipements de pipeline ;
3) Optimiser la taille des blocs de mini-lots en conséquence
Utilisation de base du pipeline PyTorch
Avant d'entrer dans les détails d'AutoPipe, familiarisons-nous d'abord avec l'utilisation de base de PyTorch Pipeline (torch.distributed.pipeline.sync.Pipe) :
Pour comprendre la conception d'un pipeline en action, considérons l'exemple simple suivant :
# Step 1: build a model including two linear layers
fc1 = nn.Linear(16, 8).cuda(0)
fc2 = nn.Linear(8, 4).cuda(1)
# Step 2: wrap the two layers with nn.Sequential
model = nn.Sequential(fc1, fc2)
# Step 3: build Pipe (torch.distributed.pipeline.sync.Pipe)
model = Pipe(model, chunks=8)
# do training/inference
input = torch.rand(16, 16).cuda(0)
output_rref = model(input)Dans cet exemple simple, vous pouvez voir qu'avant d'initialiser Pipe, vous devez partitionner le modèle nn.Sequential en plusieurs périphériques GPU et définir le nombre optimal de morceaux.
L'équilibrage du calcul entre les partitions est essentiel à la vitesse de formation du pipeline, car une répartition inégale de la charge de travail entre les étapes peut entraîner des retards, obligeant les appareils avec moins de tâches à attendre. Le nombre de morceaux peut également avoir un impact significatif sur le débit du pipeline.
Équilibrage des partitions du pipeline
Dans les systèmes de formation dynamique tels que PipeTransformer, le simple fait d'avoir le même nombre de paramètres dans chaque partition ne garantit pas la vitesse de formation la plus rapide. D’autres facteurs jouent également un rôle clé :
Figure 6 : La limite de la partition est située au milieu de la connexion de saut
1. Surcharge de communication entre partitions. Placer la limite de partition au milieu d'une connexion de saut entraîne une communication supplémentaire car les tenseurs de la connexion de saut doivent ensuite être copiés sur différents GPU.
Par exemple, pour les partitions BERT de la figure 6, la partition k doit obtenir des sorties intermédiaires de la partition k-2 et de la partition k-1. En revanche, si la limite est placée après la couche d’ajout, la surcharge de communication entre la partition k-1 et la partition k devient considérablement plus petite.
Les mesures montrent que la communication entre appareils est plus coûteuse que les partitions légèrement déséquilibrées, nous n'envisageons donc pas de rompre les connexions de saut.
2. Geler l'utilisation de la mémoire de la couche. Pendant la formation, AutoPipe doit recalculer les limites de partition plusieurs fois pour équilibrer deux types de couches différents : les couches gelées et les couches actives.
Étant donné que les couches gelées ne nécessitent pas de cartes d’activation rétroactives, d’états d’optimisation et de gradients, le coût de mémoire des couches gelées n’est qu’une fraction de celui des couches inactives.
Au lieu de lancer un profileur intrusif pour obtenir les métriques sous-jacentes des coûts de mémoire et de calcul, nous définissons un facteur de coût réglable lambdafrozen pour évaluer l'utilisation de la mémoire d'une couche gelée par rapport à la même couche active. Sur la base de mesures empiriques sur du matériel expérimental, nous l'avons fixé à 1/6.
Sur la base des deux points ci-dessus, AutoPipe peut équilibrer les partitions de pipeline en fonction des tailles de paramètres.Plus précisément, AutoPipe utilise un algorithme gourmand pour allouer des couches gelées et des couches actives afin que les sous-couches de la région de notation puissent être réparties uniformément sur les périphériques GPU K.
Le pseudocode est la fonction load_balance() de l'algorithme 1. Les couches gelées sont extraites du modèle d'origine et enregistrées dans une instance de modèle distincte Ffrozen dans le premier périphérique du pipeline.
Notez que l’algorithme de segmentation utilisé dans cet article n’est pas la seule option ;PipeTransformer est modulaire et peut être exécuté en conjonction avec n'importe laquelle des alternatives.
Compression de pipeline
La compression du pipeline permet de libérer le GPU pour accueillir davantage de copies de pipeline et réduit la quantité de communication entre les périphériques entre les partitions. Pour déterminer la durée de compactage, nous pouvons estimer la consommation de mémoire de la plus grande partition après compactage, puis la comparer à la consommation de mémoire de la plus grande partition du pipeline à l'étape T=0.
Pour éviter un profilage de mémoire étendu, l'algorithme de compression utilise la taille du paramètre comme proxy pour l'utilisation de la mémoire d'entraînement. Sur la base de cette simplification, les directives pour la compression du pipeline sont les suivantes :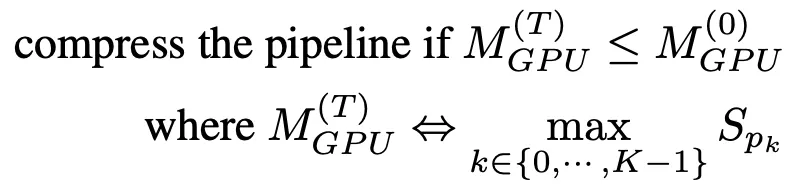
Une fois qu'une notification de gel est reçue, AutoPipe essaiera de diviser la longueur du tuyau K par 2 (par exemple, de 8 à 4, puis 2). En entrant K/2, l'algorithme de compression peut vérifier si le résultat de la compression répond aux critères de la formule (1).
Le pseudo-code est affiché dans les lignes 25 à 33 de l'algorithme 1. Notez que cette compression fait croître l'accélération de manière exponentielle pendant la formation, ce qui signifie que si un serveur GPU contient plus de GPU (par exemple, plus de 8), l'accélération augmentera encore. Figure 7 : Bulle de pipeline
Figure 7 : Bulle de pipeline
Fd, b et Ud représentent respectivement les mises à jour avant, arrière et d'optimisation du micro=batch b sur le périphérique d.
La taille totale des bulles à chaque itération est K-1 fois les coûts directs et indirects par micro-lot.
De plus, cette technique peut également accélérer la formation en réduisant la taille de la bulle du pipeline. Pour expliquer la taille des bulles dans le pipeline, la figure 7 montre comment 4 micro-lots s'exécutent dans 4 pipelines de périphériques avec K = 4.
En général, la taille totale de la bulle est K-1 fois le coût aller-retour de chaque micro-lot. Il est donc évident que les pipelines plus courts ont des tailles de bulles plus petites.
Nombre dynamique de micro-lots
Les systèmes parallèles de pipeline précédents utilisaient un nombre fixe de micro-lots par mini-lot (M). GPipe recommande que M ≥ 4 x K, où K est le nombre de partitions (longueur du pipeline). Cependant, étant donné que PipeTransformer configure K de manière dynamique, nous avons constaté que garder M statique pendant la formation ne fonctionne pas bien.
De plus, lorsqu'il est intégré au DDP, la valeur de M affecte également l'efficacité de la synchronisation du gradient DDP. Étant donné que DDP doit attendre que le dernier micro-lot termine le calcul rétrospectif d'un paramètre avant la synchronisation du gradient, plus le micro-lot est fin, plus le chevauchement du calcul et de la communication est faible.
Par conséquent, au lieu d'utiliser une valeur statique, PipeTransformer recherche dynamiquement la valeur optimale de M dans l'hybride de l'environnement DDP en énumérant les valeurs de M dans la plage de K-6K. Pour un environnement de formation spécifique, le profilage ne doit être effectué qu'une seule fois (voir ligne 35 de l'algorithme 1).
Pour le code source complet, veuillez vous référer à
AUTODP : générer davantage de copies de pipeline
Étant donné qu’AutoPipe peut compresser le même pipeline en moins de GPU, AutoDP peut générer automatiquement de nouvelles copies de pipeline pour augmenter la largeur du parallélisme des données.
Bien que simple dans son concept, le recours à la communication et à l’État est subtil et nécessite une conception minutieuse.Il existe trois principaux défis potentiels :
1. Communication DDP : La communication collective dans PyTorch DDP nécessite une appartenance statique, ce qui empêche les nouveaux pipelines de se connecter aux pipelines existants ;
2. Synchronisation du statut : Le processus nouvellement activé doit être cohérent avec le pipeline existant en termes de procédures de formation (telles que le nombre d'époques et le taux d'apprentissage), de poids et d'états d'optimisation, de limites de couche gelée et de plage GPU du pipeline ;
3. Redistribution des ensembles de données : L'ensemble de données doit être rééquilibré pour correspondre au nombre dynamique de pipelines. Cela permet non seulement d’éviter les retardataires, mais également de garantir que les gradients de tous les processus DDP sont pondérés de manière égale.
Figure 8 : AutoDP : parallélisme dynamique des données avec informations entre deux groupes de processus
Remarque : les processus 0 à 7 appartiennent à la machine 0, les processus 8 à 15 appartiennent à la machine 1
Pour relever ces défis, nous avons créé des groupes de processus de communication doubles pour DDP. Comme le montre la figure 8, le groupe de processus d'information (violet) est responsable des informations de contrôle légères et couvre tous les processus, tandis que le groupe de processus de formation active (jaune) contient uniquement les processus actifs et agit comme un outil de communication de tenseur lourd pendant la formation.
L'ensemble d'informations est statique, tandis que l'ensemble d'apprentissage est divisé et reconstruit pour correspondre au processus d'activité. À T0, seuls les processus 0 et 8 sont actifs. Lors de la transition vers T1, le processus 0 active les processus 1 et 9 (les copies de pipeline nouvellement ajoutées) et synchronise les informations nécessaires mentionnées ci-dessus à l'aide de groupes de messages.
Les quatre processus actifs forment alors un nouveau groupe de formation, adaptant la communication collective statique à l’appartenance dynamique. Pour redistribuer l'ensemble de données, nous avons implémenté une variante DistributedSampler qui ajuste de manière transparente l'échantillonnage des données pour correspondre au nombre de répliques de pipeline actives.
La conception ci-dessus permet de réduire la perte de communication du DDP. Plus précisément, lors de la transition de T0 à T1, les processus 0 et 1 peuvent détruire l'instance DDP existante, et le processus actif construira un nouveau groupe de formation DDP en utilisant le modèle de pipeline mis en cache (AutoPipe stocke le modèle gelé et le modèle mis en cache séparément).
Pour réaliser les opérations ci-dessus, nous avons utilisé les API suivantes :
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# initialize the process group (this must be called in the initialization of PyTorch DDP)
dist.init_process_group(init_method='tcp://' + str(self.config.master_addr) + ':' +
str(self.config.master_port), backend=Backend.GLOO, rank=self.global_rank, world_size=self.world_size)
...
# create active process group (yellow color)
self.active_process_group = dist.new_group(ranks=self.active_ranks, backend=Backend.NCCL, timeout=timedelta(days=365))
...
# create message process group (yellow color)
self.comm_broadcast_group = dist.new_group(ranks=[i for i in range(self.world_size)], backend=Backend.GLOO, timeout=timedelta(days=365))
...
# create DDP-enabled model when the number of data-parallel workers is changed. Note:
# 1. The process group to be used for distributed data all-reduction.
If None, the default process group, which is created by torch.distributed.init_process_group, will be used.
In our case, we set it as self.active_process_group
# 2. device_ids should be set when the pipeline length = 1 (the model resides on a single CUDA device).
self.pipe_len = gpu_num_per_process
if gpu_num_per_process > 1:
model = DDP(model, process_group=self.active_process_group, find_unused_parameters=True)
else:
model = DDP(model, device_ids=[self.local_rank], process_group=self.active_process_group, find_unused_parameters=True)
# to broadcast message among processes, we use dist.broadcast_object_list
def dist_broadcast(object_list, src, group):
"""Broadcasts a given object to all parties."""
dist.broadcast_object_list(object_list, src, group=group)
return object_listPour le code, veuillez vous référer à
Section expérimentale
Cette section résume d’abord la configuration expérimentale, puis évalue les performances de PipeTransformer sur les tâches de vision par ordinateur et de traitement du langage naturel.
matériel. Les expériences ont été menées sur deux machines identiques connectées par InfiniBand CX353A (GB/s), chacune équipée de 8 NVIDIA Quadro RTX 5000 (mémoire GPU 16 Go). La bande passante GPU à GPU au sein de la machine (PCI 3.0, 16 voies) est de 15,754 Go/s.
accomplir. Nous utilisons PyTorch Pipe comme élément de base. La définition, la configuration et les tokeniseurs associés du modèle BERT proviennent tous de HuggingFace 3.5.0. Nous avons implémenté le Vision Transformer en utilisant TensorFlow dans PyTorch.
Modèles et ensembles de données. L'expérience a utilisé deux modèles de transformateurs représentatifs dans les domaines du CV et du PNL : Vision Transformer (ViT) et BERT. ViT est appliqué à la tâche de classification d'images, initialisé avec des poids pré-entraînés sur ImageNet21K et affinés sur ImageNet et CIFAR-100. BERT s'exécute sur deux tâches : la classification de texte sur l'ensemble de données SST-2 du benchmark General Language Understanding Evaluation (GLUE) et la réponse intelligente aux questions sur l'ensemble de données SQuAD v1.1 (Stanford Question Answering). L'ensemble de données SQuAD v1.1 se compose de 100 000 paires questions-réponses issues du crowdsourcing.
Plan de formation. Les grands modèles nécessitent généralement des milliers de jours GPU (par exemple, GPT-3) s'ils sont formés à partir de zéro. Par conséquent, le réglage fin des tâches en aval avec des modèles pré-formés est devenu une tendance dans les domaines CV et NLP. De plus, PipeTransformer est un système de formation complexe impliquant plusieurs composants de base. Par conséquent, pour le développement du système et la recherche d'algorithmes de la première version de PipeTransformer, il n'est pas rentable de le développer et de l'évaluer à partir de zéro en utilisant une pré-formation à grande échelle. Par conséquent, les expériences présentées dans cette section se concentrent sur des modèles pré-entraînés. Notez que puisque l'architecture du modèle en pré-formation et en réglage fin est la même, PipeTransformer peut satisfaire les deux exigences. Nous discutons des résultats de pré-formation dans l’annexe.
Ligne de base. Les expériences de cette section comparent PipeTransformer avec les frameworks de pointe PyTorch Pipeline (l'implémentation de PyTorch GPipe) et PyTorch DDP. Comme il s’agit du premier article à étudier les couches de congélation pour accélérer la formation distribuée, il n’existe pas encore de solution correspondante totalement cohérente.
Hyperparamètres. Pour les ensembles de données ImageNet et CIFAR-100, ViT-B/16 (12 couches de transformateur et taille de patch d'entrée 16x16) a été utilisé dans les expériences. Pour SQuAD 1.1, BERT-large-uncased (24 couches) est utilisé dans les expériences. SST-2 utilise une base BERT non encapsulée (12 couches). Avec la formation PipeTransformer, ViT et BERT, la taille du lot de per=pipeline peut être définie respectivement sur environ 400 et 64. Pour d'autres hyperparamètres (tels que l'époque, le taux d'apprentissage, etc.), voir l'annexe.
Entraînement d'accélération globale
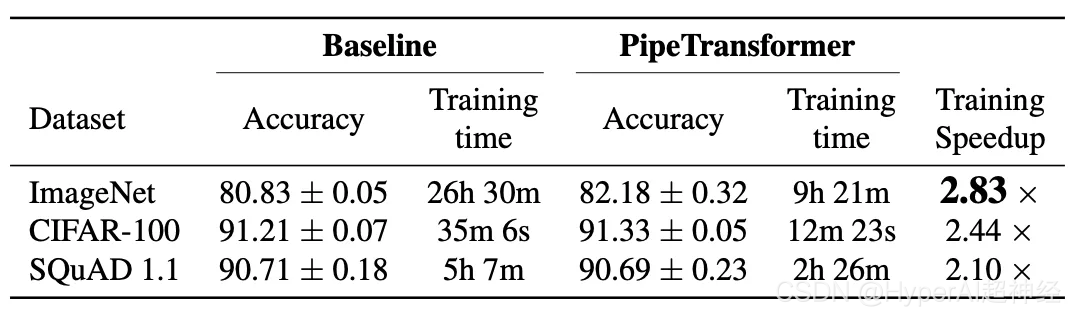
Le tableau ci-dessus résume les résultats expérimentaux globaux. Notez que l'accélération ici est basée sur une valeur conservatrice(1/3), cette valeur peut atteindre une précision similaire, voire supérieure. Si la valeur a(2/5,1/2) peut atteindre une accélération plus élevée, mais avec une légère perte de précision. De plus, BERT (24 couches) est plus grand que ViT-B/16 (12 couches), nécessitant ainsi plus de temps de communication.
Analyse des performances
Répartition de l'accélération
Cette section présente les résultats de l’évaluation et analyse les performances des différents composants dans /AutoPipe.
Pour comprendre l’efficacité de ces quatre composants et leur impact sur la vitesse d’entraînement, nous avons mené des expériences avec différentes combinaisons et utilisé leur débit d’échantillons d’entraînement (échantillons/seconde) et leur accélération comme mesures. Les résultats sont présentés dans la figure 9.Les principaux points à retenir des résultats expérimentaux sont les suivants :
1. L’accélération principale est le résultat du pipeline élastique implémenté par AutoPipe et AutoDP ;
2. L’effet d’AutoCache est amplifié par AutoDP ;
3. L'entraînement au gel est effectué de manière indépendante sans aucun réglage du système ni ralentissement de l'entraînement.
Ajuster un dans l'algorithme de gel

Figure 10 : Réglage de a dans l'algorithme de gel
Nous avons réalisé quelques expériences pour illustrer comment le gel de l’algorithme affecte la vitesse d’entraînement. Les résultats montrent que plus le a (gel excessif) est grand, plus l'accélération sera importante, mais il y aura une légère dégradation des performances. Dans l’exemple illustré à la figure 10, lorsque a=1/5, l’entraînement gelé est plus performant que l’entraînement normal, avec un rapport d’accélération de 2,04.
Nombre optimal de blocs dans un pipeline élastique

Figure 11 : Nombre optimal de segments dans un pipeline élastique
Nous analysons le nombre optimal de micro-lots M pour différentes longueurs de pipeline K. Les résultats sont présentés dans la figure 11. Comme nous pouvons le voir, le nombre optimal M change en conséquence avec différentes valeurs de K. Lorsque M est différent, l'écart de débit devient plus grand (comme indiqué sur la figure lorsque K = 8), ce qui confirme également la nécessité d'utiliser un profileur antérieur dans les pipelines élastiques.
Comprendre la synchronisation du cache

Figure 12 : Synchronisation du cache
Pour évaluer AutoCache, nous avons comparé le débit d'échantillons de tâches de formation à partir de l'époque 0 avec AutoCache (ligne bleue) et sans AutoCache (ligne rouge).
La figure 12 montre que l’activation de la mise en cache trop tôt peut ralentir la formation car elle est plus coûteuse que la propagation vers l’avant sur un plus petit nombre de couches gelées. Après avoir gelé davantage de couches, les performances des activations mises en cache sont nettement meilleures que celles du passage en avant correspondant. Par conséquent, AutoCache utilise un profileur pour déterminer le bon moment pour activer la mise en cache.
Dans notre système, pour ViT (12 couches), la mise en cache démarre à partir de la 3ème couche gelée ; pour BERT (24 couches), la mise en cache démarre à partir de la 5ème couche gelée.
Résumer
Cet article présente PipeTransformer, une solution holistique qui combine le parallélisme de pipeline élastique et le parallélisme de données pour la formation distribuée à l'aide de l'API distribuée PyTorch.
Plus précisément, PipeTransformer peut geler progressivement les couches du pipeline, regrouper les couches actives restantes dans moins de GPU et dupliquer davantage de copies du pipeline pour augmenter la largeur parallèle des données. L'évaluation sur les modèles ViT et BERT montre que PipeTransformer atteint une accélération de 2,83 fois par rapport à la ligne de base de pointe sans perte de précision.








