Command Palette
Search for a command to run...
Après Avoir Lu l'article DALL-E, Nous Avons Constaté Que Les Grands Ensembles De Données Ont Également Des Versions Alternatives

Le nouveau modèle DALL-E de l'équipe OpenAI a fait le tour des écrans. Ce nouveau type de réseau neuronal utilise 12 milliards de paramètres et a été « spécialement formé ». Il peut générer des images correspondantes après toute saisie de texte descriptif. L'équipe a désormais ouvert le document du projet et certains codes de modules, ce qui nous permet de comprendre les principes derrière cet artefact.
Au début de l'année, OpenAI a publié le modèle de génération d'images DALL-E, qui a complètement brisé le mur dimensionnel entre le langage naturel et les images.
Peu importe à quel point la description textuelle est exagérée ou irréaliste, une fois qu'elle est entrée dans DALL-E, elle peut générer une image correspondante, et l'effet a étonné tout le cercle technologique.

Un grand effort produit des miracles : le plafond des coûts de l'industrie de l'alchimie
Puissance de calcul : 1024 blocs V 100
Lorsque le modèle est sorti, les développeurs ont spéculé sur le processus de mise en œuvre derrière le modèle et attendaient avec impatience le document officiel. Récemment, le document de DALL-E et certains codes d’implémentation ont finalement été rendus publics :

Adresse de l'article : https://arxiv.org/abs/2102.12092
Comme prévu, OpenAI a une fois de plus démontré sa forte « puissance financière », comme certains développeurs l'avaient deviné auparavant.L'article a révélé qu'ils ont utilisé un total de 1024 GPU NVIDIA V100 de 16 Go tout au long de la formation.
Quant au code, la version officielle n'ouvre actuellement que le module dVAE pour la reconstruction d'image.Le but de ce module est de réduire l'utilisation de la mémoire du transformateur formé dans la tâche de génération de texte-image. La partie du code du Transformer n'a pas encore été rendue publique, nous ne pouvons donc qu'attendre avec impatience les mises à jour ultérieures. Cependant, même avec le code, tout le monde n’est pas capable de reproduire cette utilisation du GPU.
Ensemble de données : 250 millions de paires image-texte + 12 milliards de paramètres
Dans l’article, l’équipe OpenAI a présenté que la recherche sur l’utilisation de méthodes de synthèse d’apprentissage automatique pour réaliser la conversion de texte en image a commencé en 2015.
Cependant, bien que les modèles proposés dans ces études précédentes aient pu réaliser une génération de texte en image, leurs résultats de génération présentent encore de nombreux problèmes, tels que la déformation des objets, le placement déraisonnable des objets ou le mélange non naturel des éléments de premier plan et d'arrière-plan.

Après des recherches, l’équipe a découvert que les études précédentes étaient généralement évaluées sur des ensembles de données plus petits (tels que MS-COCO et CUB-200). Sur cette base, l’équipe a proposé l’idée suivante :Est-il possible que la taille de l’ensemble de données et la taille du modèle soient des facteurs limitants pour les méthodes actuelles ?
L’équipe a donc utilisé cela comme une avancée décisive., un ensemble de données de 250 millions de paires image-texte a été collecté sur Internet,Un transformateur autorégressif avec 12 milliards de paramètres est formé sur cet ensemble de données.
En outre, l’article présente que la formation du modèle dVAE utilise 64 GPU NVIDIA V100 de 16 Go,Le modèle discriminant CLIP utilise 256 GPU formés pour 14 ciel.
Après une formation intensive, l’équipe a finalement obtenu DALL-E, un modèle de génération d’images flexible et réaliste qui peut être contrôlé par le langage naturel.
L’équipe a comparé et évalué les résultats générés par le modèle DALL-E avec ceux générés par d’autres modèles. Les résultats ont été les suivants :Dans le cas de 90%, les résultats générés par DALL-E sont plus favorables que ceux des études précédentes.

L'ensemble de données image et texte est un substitut plat, vraiment bon
Le succès du modèle DALL-E prouve également l’importance des données d’entraînement à grande échelle pour un modèle.
Il peut être difficile pour les alchimistes ordinaires d'obtenir le même ensemble de données que DALL-E, mais les grandes marques ont toutes des versions de substitution (versions alternatives abordables).
Bien qu'OpenAI ait déclaré que son ensemble de données de formation ne sera pas encore rendu public,Mais ils ont révélé que l'ensemble de données comprend l'ensemble de données Conceptual Captions publié par Google.
Mini-alternative à un ensemble de données image-texte à grande échelle
L'ensemble de données Conceptual Captions a été proposé par Google dans l'article « Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning » publié dans ACL 2018.

Cet article apporte des contributions à la fois à la classification des données et à la modélisation. d'abord,L'équipe a proposé un nouvel ensemble de données d'annotation de légendes d'images, Conceptual Captions, qui contient un ordre de grandeur d'images en plus que l'ensemble de données MS-COCO, y compris un total d'environ 3,3 millions de paires d'images et de descriptions.
Légendes conceptuelles((Titre conceptuel) Détails du jeu de données
Source des données :Google AI
Heure de sortie :2018
Quantité incluse :3,3 millions de paires image-texte
Format des données :.tsv Taille des données :1,7 Go
Adresse de téléchargement :https://orion.hyper.ai/datasets/14682
Utilisation de ResNet+RNN+Transformer pour construire une DALL-E inversée
En termes de modélisation, sur la base des résultats de recherches antérieures,L'équipe a utilisé Inception-ResNet-v2 pour extraire les caractéristiques de l'image, puis a utilisé un modèle basé sur RNN et Transformer pour générer des légendes d'image (DALL-E génère des images à partir de descriptions de texte et Conceptual Captions génère des annotations de texte à partir d'images).
Pour générer l'ensemble de données, l'équipe a commencé avec un pipeline Flume qui traitait environ un milliard de pages Web Internet en parallèle, en extrayant, filtrant et traitant les paires d'images et de légendes candidates de ces pages, en conservant celles qui passaient plusieurs filtres.
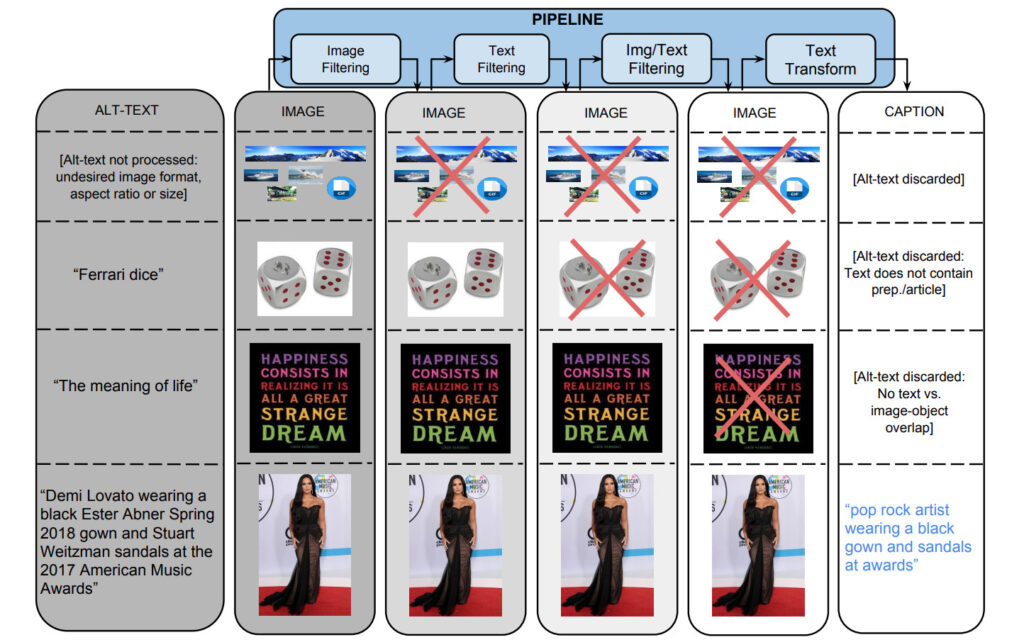
1 : Filtrage basé sur l'image
Les algorithmes filtrent les images en fonction du format d'encodage, de la taille, du rapport hauteur/largeur et du contenu répréhensible. Il enregistre uniquement les images JPEG dont la taille est supérieure à 400 pixels dans les deux dimensions et dont le rapport entre la taille et la dimension ne dépasse pas 2. Il exclut les images qui déclenchent la détection de pornographie ou de blasphème. Au final, ces filtres ont éliminé plus de 651 données candidates TP3T.
2. Filtrage basé sur le texte
L'algorithme obtient le texte descriptif (Alt-text) des pages Web HTML, supprime les titres avec du texte non descriptif (tels que les balises SEO ou les hashtags) et filtre les annotations en fonction d'indicateurs prédéfinis tels que ceux contenant de la pornographie, des gros mots, des blasphèmes, des photos de profil, etc. Finalement, seuls les textes candidats 3% ont réussi le filtrage.
En plus du filtrage séparé basé sur le contenu de l'image et du texte, les données sont également filtrées lorsqu'aucune des balises de texte ne peut être mappée au contenu de l'image.
Attribuez des étiquettes de classe aux images à l’aide de classificateurs fournis via les API Google Cloud Vision.
3. Conversion de texte et hyperlexicalisation
Au cours du processus de collecte de données, plus de 5 milliards d’images provenant d’environ 1 milliard de pages Web en anglais ont été traitées. Selon la norme de filtrage de haute précision, seulement 0,2% de paires image et titre ont passé le contrôle, et les titres restants ont souvent été exclus car ils contenaient des noms propres (personnes, lieux, emplacements, etc.).
Les auteurs ont formé un modèle de sous-titres basé sur RNN sur des données de texte alternatif non hypersynchronisées et donnent un exemple de sortie dans la figure ci-dessous.

Description de la sortie du modèle : Le chanteur Justin Bieber se produit aux Billboard Music Awards au MGM
En utilisant l’API Google Cloud Natural Language, l’équipe a obtenu des annotations d’entité nommée et de dépendance grammaticale. Ensuite, l'API de recherche Google Knowledge Graph (KG) est utilisée pour faire correspondre les entités nommées avec les entrées KG et exploiter les termes hyperonymes associés.
Par exemple, « Harrison Ford » et « Calista Flockhart » sont tous deux identifiés comme des entités nommées, ils correspondent donc aux entrées KG correspondantes. Ces entrées KG ont « acteur » comme conjonction, puis remplacent les jetons de surface d'origine par cette conjonction.
Évaluation des résultats
L'équipe a pris l'ensemble de test de l'ensemble de données etUn échantillon de 4 000 exemples a été extrait de manière aléatoire et évalué manuellement. Parmi les 3 annotations, les annotations au-dessus de 90% ont reçu la plupart des bonnes notes.
L’équipe a comparé les différences entre le modèle formé sur COCO et le modèle formé sur Conceptual.
dans,La première différence est que les résultats de la formation basés sur Conceptual sont plus sociaux que les résultats de la formation COCO basés sur des images naturelles.
Par exemple, dans l'image la plus à gauche ci-dessous, le modèle formé par COCO utilise « groupe d'hommes » pour désigner les personnes sur l'image, tandis que le modèle formé par Conceptual utilise le terme plus approprié et plus informatif « diplômés ».

La deuxième différence est que les modèles formés par COCO semblent souvent « associer d’eux-mêmes » et « fabriquer » certaines descriptions à partir de rien.Par exemple, il avait l’hallucination d’être « devant un bâtiment » pour la première image ; l'hallucination d'être « une horloge et deux portes » pour la deuxième image ; et l'hallucination d'être "un gâteau d'anniversaire" pour la troisième photo. En revanche, le modèle de l’équipe n’a pas détecté ce problème.
La troisième différence réside dans les types d’images qui peuvent être utilisées.Étant donné que COCO ne contient que des images naturelles, les images de dessins animés comme la quatrième de la figure ci-dessus provoqueront des interférences « associatives » avec le modèle entraîné par COCO, telles que « jouet en peluche », « poisson », « côté de la voiture » et d'autres choses inexistantes. En revanche, le modèle conceptuel formé peut gérer ces images avec facilité.
Le lancement du modèle DALL-E a également fait soupirer de nombreux chercheurs dans ce domaine : les données sont véritablement la pierre angulaire de l’IA. Voulez-vous également essayer de faire des miracles avec une grande force ? Commençons par l’ensemble de données des légendes conceptuelles !
accéder https://orion.hyper.ai/datasets Ou cliquezLire l'article original, et obtenez plus d'ensembles de données !
Source de l'information :
https://openai.com/blog/dall-e/
Adresse du document DALL-E :
https://arxiv.org/abs/2102.12092
Adresse GitHub du projet DALL-E :
https://github.com/openai/dall-e
Adresse du document sur les légendes conceptuelles :








