Command Palette
Search for a command to run...
Ressources De Télédétection (Partie 1) : Utilisation De Code Source Ouvert Pour Former Des Modèles De Classification Des Terres
La classification des terres est l’un des scénarios d’application importants des images de télédétection. Cet article présente plusieurs méthodes courantes de classification des terres et utilise un code de segmentation sémantique open source pour créer un modèle de classification des terres.
Les images de télédétection sont des données importantes pour les travaux d’arpentage et de cartographie de l’information géographique. Ils sont d'une grande importance pour la surveillance des conditions géographiques nationales et la mise à jour des bases de données d'informations géographiques, et jouent un rôle de plus en plus important dans les domaines militaire, commercial et des moyens de subsistance des populations.
Ces dernières années, avec l'amélioration des capacités d'acquisition d'images satellite du pays, l'efficacité de la collecte de données d'images de télédétection a été considérablement améliorée, formant un modèle dans lequel plusieurs capteurs tels que la faible résolution spatiale, la haute résolution spatiale, le grand angle de vision, le multi-angle, le radar, etc. coexistent.

Une gamme complète de capteurs pour répondre aux besoins d'observation de la Terre à différentes fins.Cependant, cela a également entraîné des problèmes tels que des formats de données d’images de télédétection incohérents et une consommation d’une grande quantité d’espace de stockage.Le processus de traitement d’image présente souvent de grands défis.
Prenons l’exemple de la classification des terres : dans le passé, les images de télédétection étaient utilisées pour classer les terres.Ils s'appuient souvent sur une main d'œuvre importante pour l'étiquetage et les statistiques,Cela prend plusieurs mois, voire un an ; couplée à la complexité et à la diversité des types de terres, les erreurs statistiques humaines sont inévitables.
Avec le développement de la technologie de l’intelligence artificielle, l’acquisition, le traitement et l’analyse des images de télédétection sont devenus plus intelligents et plus efficaces.
Méthodes de classification des terres communes
Les méthodes de classification des terres couramment utilisées sont essentiellement divisées en trois catégories :Méthodes de classification traditionnelles basées sur les SIG, méthodes de classification basées sur des algorithmes d'apprentissage automatique et méthodes de classification utilisant la segmentation sémantique des réseaux neuronaux.
Méthode traditionnelle : utilisation de la classification SIG
Le SIG est un outil souvent utilisé lors du traitement des images de télédétection. Son nom complet est Système d'information géographique, également connu sous le nom de système d'information géographique.Il intègre des technologies avancées telles que la gestion de bases de données relationnelles, des algorithmes graphiques efficaces, l'interpolation, le zonage et l'analyse de réseau.Rendre l’analyse spatiale simple et facile.

En utilisant la technologie d'analyse spatiale SIG,Il peut obtenir des informations sur la localisation spatiale, la distribution, la morphologie, la formation et l’évolution du type de terrain correspondant.Identifier les caractéristiques du terrain et porter des jugements.
Apprentissage automatique : utilisation d'algorithmes pour la classification
Les méthodes traditionnelles de classification des terres comprennent la classification supervisée et la classification non supervisée.
La classification supervisée est également appelée classification de formation.Il s’agit de comparer et d’identifier des pixels de catégories inconnues avec des pixels d’échantillons d’entraînement de catégories confirmées.Complétez ensuite la classification de l’ensemble du type de terrain.
Dans la classification supervisée, lorsque les échantillons d'entraînement ne sont pas suffisamment précis, la zone d'entraînement est généralement resélectionnée ou modifiée manuellement visuellement pour garantir la précision des pixels de l'échantillon d'entraînement.

La classification non supervisée signifie qu'il n'est pas nécessaire d'obtenir à l'avance des normes de catégorie a priori, mais la classification statistique est effectuée entièrement en fonction des caractéristiques spectrales des pixels de l'image de télédétection.Cette méthode présente un degré élevé d’automatisation et nécessite peu d’intervention humaine.
Grâce à des algorithmes d’apprentissage automatique tels que les machines à vecteurs de support et les méthodes de vraisemblance maximale, l’efficacité et la précision de la classification supervisée et non supervisée peuvent être considérablement améliorées.
Réseaux neuronaux : utilisation de la segmentation sémantique pour la classification
La segmentation sémantique est une méthode de classification de bout en bout au niveau des pixels qui peut améliorer la compréhension des scènes environnementales par la machine et est largement utilisée dans des domaines tels que la conduite autonome et l'aménagement du territoire.
La technologie de segmentation sémantique basée sur des réseaux neuronaux profonds est plus performante que les méthodes d’apprentissage automatique traditionnelles lorsqu’il s’agit de tâches de classification au niveau des pixels.

Les images de télédétection à haute résolution présentent des scènes complexes et des détails riches, et les différences spectrales entre les objets sont incertaines, ce qui peut facilement conduire à une faible précision de segmentation ou même à une segmentation invalide.
Utilisation de la segmentation sémantique pour traiter des images de télédétection à haute et ultra-haute résolution,Les caractéristiques des pixels de l'image peuvent être extraites avec plus de précision et les types de terrains spécifiques peuvent être identifiés rapidement et avec précision, améliorant ainsi la vitesse de traitement des images de télédétection.
Modèles open source de segmentation sémantique couramment utilisés
Les modèles open source de segmentation sémantique au niveau des pixels couramment utilisés incluent FCN, SegNet et DeepLab.
1. Réseau entièrement convolutif (FCN)
caractéristiques:Segmentation sémantique de bout en bout
avantage:Aucune restriction sur la taille de l'image, universelle et efficace
défaut:Incapables d'effectuer rapidement un raisonnement en temps réel, les résultats du traitement ne sont pas assez fins et ne sont pas sensibles aux détails de l'image
2. SegNet
caractéristiques:Déplacez l'index de pooling maximal vers le décodeur, améliorant ainsi la résolution de segmentation
avantage:Vitesse d'entraînement rapide, haute efficacité et faible utilisation de la mémoire
défaut:Le test n'est pas un feed-forward et doit être optimisé pour déterminer l'étiquette MAP
3. DeepLab
DeepLab a été publié par Google AI.Préconiser l'utilisation du DCNN pour résoudre les tâches de segmentation sémantique,Il existe quatre versions au total : v1, v2, v3 et v3+.
DeepLab-v1 résout le problème de perte d'informations causé par la mise en commun.La méthode de convolution dilatée est proposée.Le champ réceptif est élargi sans augmenter le nombre de paramètres, tout en garantissant que l'information n'est pas perdue.

DeepLab-v2 est basé sur la v1.Ajout du parallélisme multi-échelles,Le problème de la segmentation simultanée d’objets de différentes tailles est résolu.
DeepLab-v3 La convolution de trou est appliquée au module en cascade.Et le module ASPP a été amélioré.
DeepLab-v3+ Le module SPP est utilisé dans la structure encodeur-décodeur.Les bords fins des objets peuvent être restaurés. Affiner les résultats de segmentation.
Préparation à la formation du modèle
But:Basé sur DeepLab-v3+, développer un modèle de classification à 7 niveaux pour la classification des terres
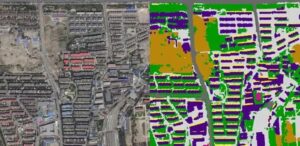
données:304 images de télédétection d'une région provenant de Google Earth. En plus de l'image originale, il comprend également des images de support de 7 catégories, des masques de 7 catégories, des images de 25 catégories et des images de masques de 25 catégories annotées par des professionnels. La résolution de l'image est de 560*560 et le taux d'allocation spatiale est de 1,2 m.

La partie supérieure est l'image originale et la partie inférieure est l'image de classification 7
Le code de réglage des paramètres est le suivant :
net = DeepLabV3Plus(backbone = 'xception')criterion = CrossEntropyLoss()optimizer = optim.SGD(net.parameters(), lr=0.05, momentum=0.9,weight_decay=0.00001)lr_fc=lambda iteration: (1-iteration/400000)**0.9exp_lr_scheduler = lr_scheduler.LambdaLR(optimizer,lr_fc,-1)
Détails de la formation
Sélection du taux de hachage :NVIDIA T4
Cadre de formation :PyTorch V1.2
Itérations :600 époque
Durée de la formation :Environ 50h
Je suis d'accord :0,8285 (données d'entraînement)
CA:0,7838 (données d'entraînement)
Lien vers le jeu de données : https://openbayes.com/console/openbayes/datasets/qiBDWcROayo
Lien direct vers le processus de formation détaillé : https://openbayes.com/console/openbayes/containers/dOPqM4QBeM6

Utilisation du tutoriel
L'exemple de fichier d'affichage dans le didacticiel est predict.ipynb. L'exécution de ce fichier installera l'environnement et affichera l'effet de reconnaissance du modèle existant.
Chemin du projet
– Chemin de l'image de test :
semantic_pytorch/out/result/pic3
– Chemin de l'image du masque :
semantic_pytorch/out/result/label
– Prédire le chemin de l'image :
sémantique_pytorch/out/résultat/prédire
– Liste des données d'entraînement :train.csv
– Liste des données de test :test.csv
Instructions
Le modèle de formation entre dans semantic_pytorch et le modèle formé est enregistré dans model/new_deeplabv3_cc.pt.
Le modèle utilise DeepLabV3plus et, dans les paramètres de formation, Loss utilise l'entropie croisée binaire. Le numéro d'époque est 600 et le taux d'apprentissage initial est de 0,05.
Instructions de formation :
python main.pySi vous utilisez le modèle que nous avons formé, enregistrez-le dans le dossier modèle fix_deeplab_v3_cc.pt et appelez-le directement dans predict.py.
Instructions prédictives :
python predict.pyAdresse du tutoriel :https://openbayes.com/console/openbayes/containers/dOPqM4QBeM6
Auteur du modèle:
Wang Yanxin, étudiant en deuxième année d'ingénierie logicielle à l'Université du Heilongjiang, actuellement stagiaire chez OpenBayes.
Question 1 : Pour développer ce modèle, quels canaux avez-vous utilisés et quelles informations avez-vous consultées ?
Wang Yanxin :Principalement par le biais des communautés techniques, de GitHub et d'autres canaux, j'ai vérifié certains articles DeepLab-v3+ et des cas de projets associés, j'ai appris à l'avance quels étaient les pièges et comment les surmonter, et j'ai fait des préparatifs suffisants pour interroger et résoudre les problèmes à tout moment lorsque je rencontre des problèmes dans le processus de développement de modèle ultérieur.
Question 2 : Quels obstacles avez-vous rencontrés au cours du processus ? Comment l'as-tu surmonté ?
Wang Yanxin :La quantité de données n'est pas suffisante, ce qui entraîne des performances moyennes de l'IoU et de l'AC. La prochaine fois, vous pourrez essayer d’utiliser un ensemble de données de télédétection public avec des données plus riches.
Question 3 : Quelles autres directions souhaitez-vous essayer en matière de télédétection ?
Wang Yanxin :Cette fois, je classe les terres. Ensuite, je souhaite utiliser une combinaison d’apprentissage automatique et de technologie de télédétection pour analyser les paysages océaniques et les éléments marins, ou combiner la technologie acoustique pour essayer d’identifier et d’évaluer la topographie des fonds marins.
La quantité de données utilisée dans cette formation est relativement faible et les performances IoU et AC sur l'ensemble de formation sont moyennes. Vous pouvez également essayer d’utiliser des ensembles de données de télédétection publics existants pour la formation du modèle. D’une manière générale, plus la formation est approfondie et plus les données de formation sont riches, meilleures sont les performances du modèle.
Dans le prochain article de cette série,Nous avons compilé 11 ensembles de données de télédétection publiques grand public et les avons classés.Vous pouvez choisir en fonction de vos besoins et former un modèle plus complet basé sur les idées de formation fournies dans cet article.
se référer à :
http://tb.sinomaps.com/CN/0494-0911/home.shtml
file:///Users/antonia0912/Downloads/2018-6A-50.pdf
https://zhuanlan.zhihu.com/p/75333140
http://www.mnr.gov.cn/zt/zh/zljc/201106/t20110619_2037196.html








