Command Palette
Search for a command to run...
Une Équipe De l'Université Du Zhejiang Publie Une Nouvelle Méthode De Synthèse De Vues 3D, Bien Meilleure Que NeRF Et NV
Avec seulement quelques vidéos sous différents angles, l'image complète à 360° du corps humain peut être construite sans aucun angle mort. Il faut dire que la capacité d’imagination de l’IA devient de plus en plus puissante. De tels outils pourraient apporter de nouvelles avancées à l’industrie du cinéma et de la télévision, à la présentation des programmes sportifs, etc. à l’avenir.
À l’avenir, la manière dont nous regardons les films, les matchs de football, les concerts, etc. pourrait être complètement modifiée par la « vidéo à point de vue libre ».
Vous ne savez peut-être pas ce qu'est une « vidéo à point de vue libre », mais vous avez sûrement déjà expérimenté des vidéos VR, AR ou joué à des jeux 3D. Elles entrent toutes dans la catégorie des vidéos à point de vue libre et leurs caractéristiques sont les suivantes :Il peut être visualisé sous n’importe quel angle, offrant une expérience totalement immersive.

Comment une telle vidéo peut-elle être tournée ? D'une manière générale, la méthode traditionnelle nécessite plusieurs caméras pour filmer sous différents angles, puis combiner les vidéos sous tous les angles.

Cependant, cette méthode repose sur plusieurs caméras, ce qui est non seulement coûteux mais également limité par l'environnement du lieu de tournage.
Il existe un autre moyen de se débarrasser de ces limitations.En saisissant simplement quelques clichés du corps humain pris sous différents angles, une nouvelle vue 3D à 360° du corps humain peut être synthétisée.Il s’agit du dernier résultat récemment publié par des chercheurs de l’Université du Zhejiang.
Fin décembre, l'équipe a publié un nouvel article sur arxiv« Corps neuronal : représentations neuronales implicites avec codes latents structurés pour une synthèse visuelle innovante des humains dynamiques », a proposé une nouvelle représentation du corps humain, Neural Body, utilisant des vidéos multi-vues clairsemées pour synthétiser de nouvelles vues de corps humains 3D dynamiques. La vérification expérimentale montre que cette méthode est supérieure aux autres méthodes précédentes.
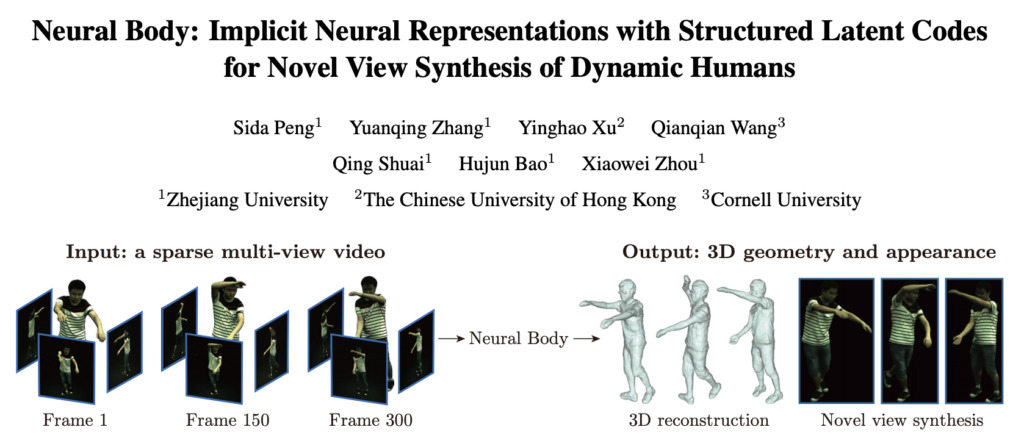
Adresse de l'article : https://arxiv.org/pdf/2012.15838.pdf
Il convient de mentionner que les sept auteurs à l'origine de l'article ont tous étudié ou sont diplômés de l'Université du Zhejiang et proviennent du Laboratoire clé d'État de conception assistée par ordinateur et de graphisme de l'Université du Zhejiang.Parmi eux, Hujun Bao et Xiaowei Zhou sont tous deux professeurs du laboratoire. Après avoir obtenu leur diplôme de premier cycle, Yinghao Xu et Qianqian Wang ont poursuivi leurs doctorats respectivement à l'Université chinoise de Hong Kong et à l'Université Cornell.
Même avec une petite quantité de matériau, vous pouvez toujours générer des vues 3D de haute qualité
Actuellement, qu’il s’agisse d’un film, d’une émission de télévision ou d’un événement sportif, ce que nous voyons sont des images prises par une seule caméra. Si vous pouvez obtenir une « vidéo de perspective gratuite » et voir ce que vous voulez, ce sera certainement une expérience comme avoir la perspective de Dieu.
En fait, l’IA a également étudié ce problème ces dernières années et a produit des solutions de synthèse de vues telles que NeRF et Neural Volumes (NV en abrégé).
Cependant, des études existantes ont montré que l’apprentissage de représentations neuronales implicites de scènes 3D peut permettre d’obtenir une bonne qualité de synthèse de vue dans des conditions de vue d’entrée denses. Cependant, si les vues sont très clairsemées, l’apprentissage de la représentation sera mal posé.

C'est pourquoi, pour résoudre ce problème mal posé, une équipe de recherche de l'Université du Zhejiang, de l'Université chinoise de Hong Kong et de l'Université Cornell a proposé l'idée clé d'intégrer les résultats d'observation sur des images vidéo.
Le dernier résultat de recherche de l’équipe a proposé le corps neuronal.Il s’agit d’une nouvelle représentation du corps humain qui suppose que les représentations neuronales apprises sur différentes images partagent le même ensemble de codes latents ancrés sur une grille déformable afin que les observations sur différentes images puissent être naturellement intégrées.Le maillage déformable fournit également un guidage géométrique au réseau pour apprendre plus efficacement les représentations 3D.

Les chercheurs ont mené des expériences sur un ensemble de données multi-vues nouvellement collecté et ont montré que leur méthode présente un avantage considérable par rapport aux méthodes précédentes en termes de qualité de synthèse des vues.
Lors d’une démonstration, l’équipe a démontré la capacité de sa méthode à reconstruire des figures en mouvement à partir de vidéos monoculaires de personnes effectuant diverses actions.

Cette méthode réduit considérablement le coût de la synthèse vidéo à point de vue libre, au moins en économisant le coût de la caméra, et a donc une applicabilité plus large.
Obtenez un corps neuronal en 5 étapes
1. Code latent structuré
Afin de contrôler la position spatiale et la posture humaine des codes latents, l’équipe a ancré ces codes latents à un modèle humain déformable (SMPL). SMPL est un modèle basé sur les sommets de la peau, qui est défini comme des paramètres de forme, des paramètres de pose et des fonctions de transformation de corps rigide par rapport au système de coordonnées SMPL.
Le code latent est utilisé avec un réseau neuronal pour représenter la géométrie locale et l’apparence d’une personne. L’ancrage de ces codes sur un modèle déformable permet de représenter une personne dynamique. Grâce à la représentation dynamique des personnes, l'équipe a construit un modèle de variable latente qui mappe le même ensemble de codes latents dans des domaines implicites de densité et de couleur à travers les images, intégrant naturellement les observations.
2. Prolifération du code
Étant donné que les codes latents structurés sont rares dans l’espace 3D, l’interpolation directe des codes latents entraînera des vecteurs nuls pour la plupart des points 3D. Pour résoudre ce problème, l’équipe a diffusé le code latent défini sur la surface dans l’espace tridimensionnel proche.
Étant donné que la diffusion du code ne doit pas être affectée par la position et l'orientation de la personne dans le système de coordonnées mondial, ils transforment la position du code dans le système de coordonnées SMPL.
La diffusion de code regroupe également les informations globales et locales des codes latents structurés, ce qui aide à apprendre le domaine implicite.
3. Régression de la densité et de la couleur
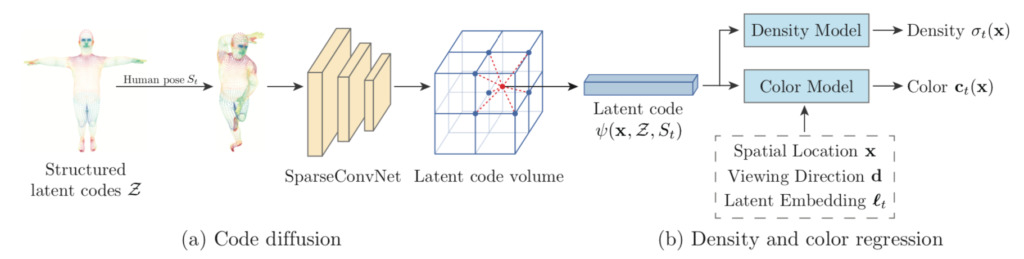
L’équipe de recherche a découvert que des facteurs variant dans le temps affectent l’apparence du corps humain, comme l’éclairage secondaire et l’auto-ombrage. Inspirée par le décodeur automatique, l’équipe a attribué une image d’intégration latente t à chaque image vidéo pour coder les facteurs de variation temporelle.
Rendu volumique
Sous un point de vue donné, l’équipe a utilisé la technologie de rendu de volume classique (également connue sous le nom de rendu stéréo) pour rendre le corps neuronal en une image bidimensionnelle.
Les limites de la scène sont ensuite estimées sur la base du modèle SMPL, et Neural Body prédit ensuite la densité volumique et la couleur de ces points.
Sur la base du rendu volumique, le modèle est optimisé en comparant l'image rendue avec l'image observée.
5. Formation
Par rapport aux méthodes de reconstruction basées sur des images, cette méthode utilise toutes les images de la vidéo pour optimiser le modèle et dispose de plus d'informations pour récupérer la structure 3D.
De plus, l’équipe a utilisé l’optimiseur Adam pour entraîner Neural Body. La formation a été réalisée sur quatre GPU 2080 Ti. Pour une vidéo à quatre vues avec un total de 300 images, la formation prend généralement environ 14 heures.
Après les cinq étapes ci-dessus, Neural Body est capable de réaliser une synthèse vidéo à point de vue libre basée sur un petit nombre de vues, et comparé à d'autres méthodes, l'effet est nettement meilleur que le premier.
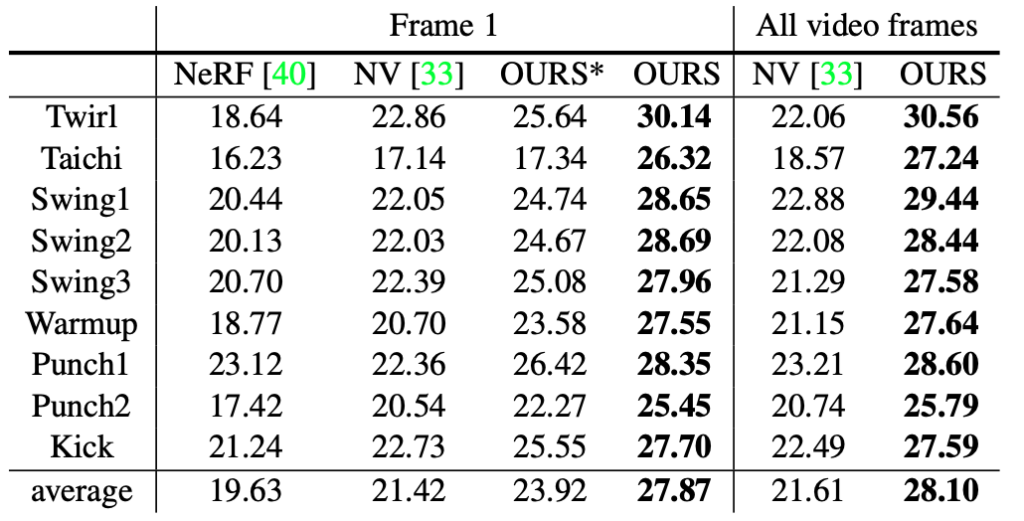
Remarque : « OURS* » et « OURS » représentent les résultats de l’entraînement sur une seule image de vidéo et sur quatre images de vidéo respectivement)
La technologie de remplissage du cerveau de l'IA facilite la réalisation d'effets 3D, et ses applications ne se limitent pas à l'industrie du cinéma et de la télévision et aux événements sportifs en direct. Pour les développeurs de jeux, les instructeurs de fitness, les fournisseurs de publicité 3D, etc., c'est un outil qui peut considérablement améliorer l'efficacité et l'efficience du travail.

Page d'accueil du projet :








