Command Palette
Search for a command to run...
Traduction De Bandes Dessinées, Intégration De l'IA, Articles De l'Université De Tokyo Inclus Dans AAAI'21

Récemment, une étude sur la traduction automatique de textes de bandes dessinées a suscité de vives discussions. L'équipe Mantra, composée de deux doctorants de l'Université de Tokyo, a publié un article, qui a été inclus dans l'AAAI 2021. Le projet Mantra vise à fournir des outils de traduction automatique pour les bandes dessinées japonaises.
Récemment, une publication conjointe de l'équipe Mantra de l'Université de Tokyo, Yahoo (Japon) et d'autres institutions « Vers une traduction entièrement automatisée de mangas »(Adresse de l'article https://arxiv.org/abs/2012.14271)L’article a attiré l’attention du monde universitaire et de la communauté bidimensionnelle.

L'équipe Mantra a réussi à atteindreLes dialogues, les mots d'ambiance, les étiquettes et autres textes des bandes dessinées sont automatiquement reconnus, les personnages sont distingués et le contexte est connecté. Enfin, le texte traduit est correctement remplacé et intégré dans la zone de bulle.
Avec cet outil de traduction magique, l'équipe de traduction et les fans de bandes dessinées devraient être très heureux.
Publier des articles, publier des ensembles de données et commercialiser
En termes de recherche scientifique, l'article a été accepté par l'AAAI 2021. L'équipe de recherche a également ouvert un ensemble de données d'évaluation de traduction composé de cinq bandes dessinées de styles différents (fantastique, romance, combat, suspense et vie).
Ensemble de données d'évaluation de la traduction de bandes dessinées OpenMantra
Adresse du document :https://arxiv.org/abs/2012.14271
Format des données : fichiers JSON annotés et images brutes
Contenu des données :1593 phrases, 848 scènes, 214 pages de bandes dessinées
Taille des données : 36,8 Mo
Mis à jour : 7 décembre 2020
Adresse de téléchargement :https://orion.hyper.ai/datasets/14137
En termes de productisation,Mantra prévoit de lancer un moteur de traduction automatique packagéElle fournit non seulement des services automatisés de traduction et de distribution de bandes dessinées aux éditeurs, mais propose également des services pour les utilisateurs individuels.
Vous trouverez ci-dessous quelques traductions du manga japonais « Surrounding Men » sélectionnées sur le compte Twitter officiel de Mantra.Cette bande dessinée multi-images, légèrement de style danmei, est pleine de joie et d'amour gay, avec le fond anthropomorphique des appareils numériques couramment utilisés dans la vie.:
glisserVoir la version japonaise originale de « Nearby Man »
et traduction automatique des versions chinoise et anglaise
La reconnaissance, la traduction et l’intégration sont toutes des étapes importantes
Les étapes spécifiques de mise en œuvre sont expliquées en détail par l'équipe de recherche Mantra dans l'article « Vers une traduction de mangas entièrement automatisée ».
La première étape consiste à localiser le texte
La première étape pour réaliser une traduction automatique de bande dessinée consiste à extraire la zone de texte.
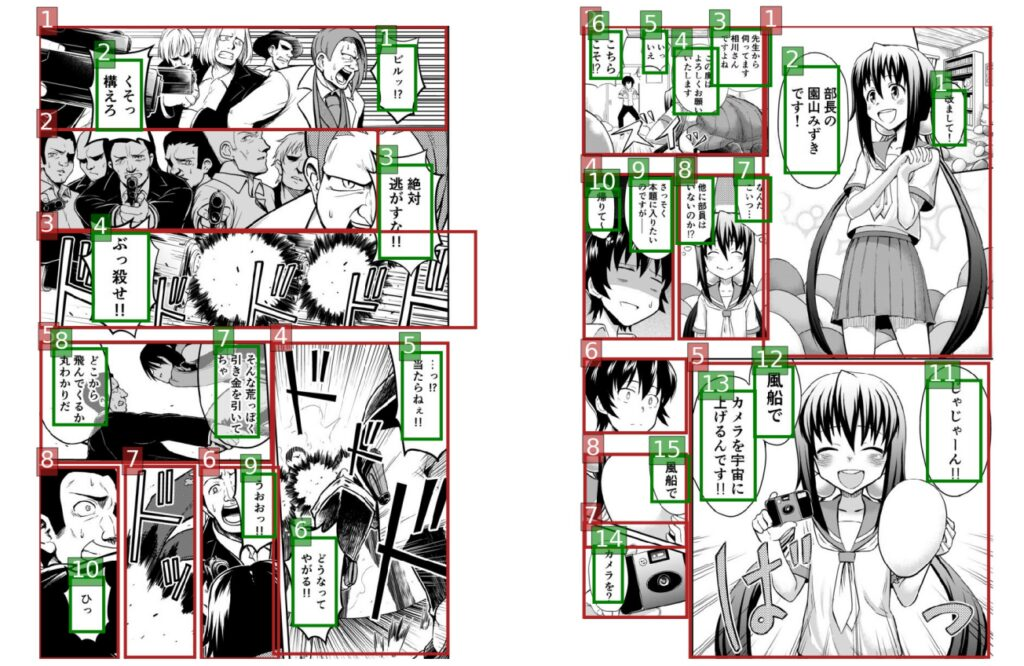
Cependant, en raison de la particularité des bandes dessinées, les dialogues de différents personnages, les onomatopées, les annotations de texte, etc. seront tous affichés dans une image de bande dessinée. Les dessinateurs utiliseront des bulles, des polices différentes et des polices exagérées pour afficher des textes avec différents effets.
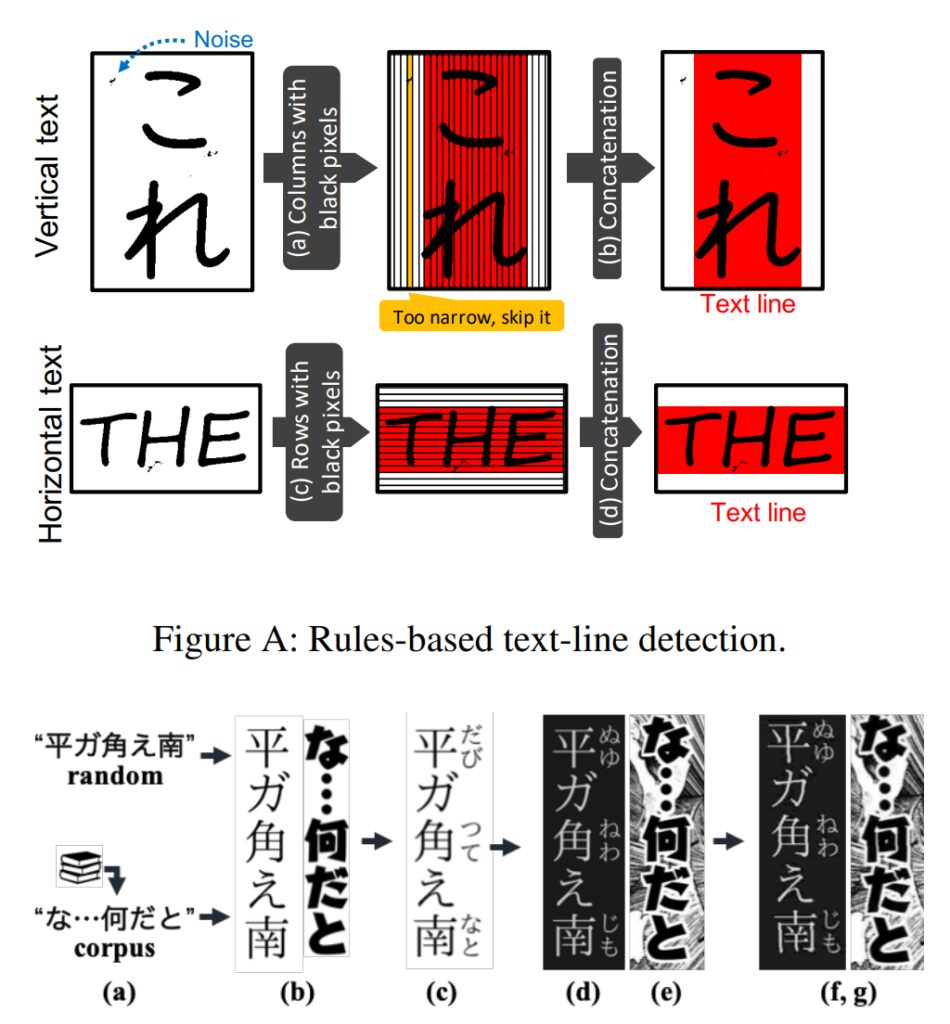
L'équipe de recherche a constaté qu'en raison de ces différentes polices et styles dessinés à la main dans les bandes dessinées, même les systèmes OCR les plus avancés (tels que l'API Google Cloud Vision) fonctionnent mal sur le texte des bandes dessinées.
L'équipe a donc développé un module de reconnaissance de texte optimisé pour les bandes dessinées, capable de reconnaître des caractères spéciaux en détectant les lignes de texte et en identifiant les caractères de chaque ligne de texte.
Étape 2 Identification du contenu
Dans les bandes dessinées, le texte le plus courant est le dialogue entre les personnages, et les bulles de texte de dialogue seront découpées en plusieurs morceaux.
Cela nécessite que la traduction automatique soit capable de distinguer avec précision les rôles, de prêter attention au lien entre les sujets et d'éviter les répétitions dans le contexte, ce qui impose des exigences plus élevées à la traduction automatique.
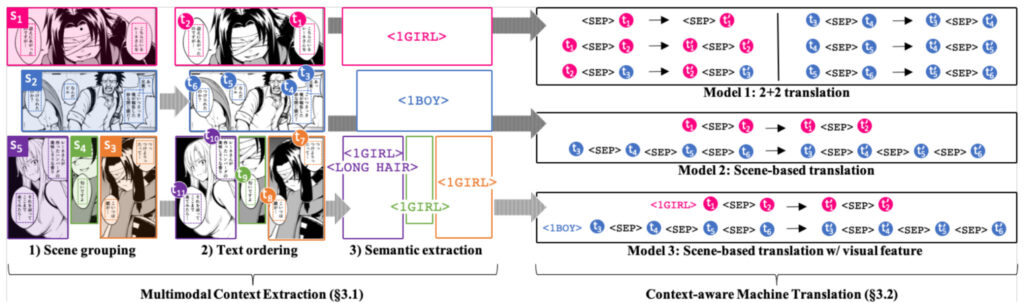
Dans cette étape, il est nécessaire d’y parvenir grâce à la connaissance du contexte, à la reconnaissance des émotions et à d’autres méthodes. En matière de connaissance du contexte, l’équipe Mantra a utilisé trois méthodes : le regroupement de textes, l’ordre de lecture des textes et l’extraction de la sémantique visuelle pour obtenir une connaissance du contexte multimodal.
Étape 3 Intégration automatique
Le moteur automatisé Mantra peut non seulement distinguer les caractères et traduire avec précision dans le contexte, mais également résoudre la partie la plus longue et la plus laborieuse de la traduction de bandes dessinées : l'intégration des caractères.

Lors du processus d'intégration, vous devez d'abord effacer la zone intégrée, puis intégrer les caractères. Étant donné que les formes, l’orthographe, les combinaisons et les lectures connectées des caractères japonais, chinois et anglais sont toutes différentes, ce processus est particulièrement difficile.
Dans cette étape, vous devez effectuer : correspondance de page → détection de zone de texte → comptage de pixels des bulles de texte → division des bulles connectées → alignement entre les langues → reconnaissance de texte → extraction de contexte.
Expérience : test d'ensemble de données et de modèle
Dans la partie expérimentale de l'article, l'équipe Mantra a mentionné qu'il n'existe actuellement aucun ensemble de données de bandes dessinées incluant plusieurs langues. Ils ont donc créé les ensembles de données OpenMantra (open source) et PubManga, qui OpenMantra est utilisé pour évaluer la traduction automatique et contient 1 593 phrases, 848 scènes et 214 pages de bandes dessinées. L’équipe Mantra a demandé à des traducteurs professionnels de traduire l’ensemble de données en anglais et en chinois.

L'ensemble de données PubManga est utilisé pour évaluer le corpus construit, qui contient des annotations de : 1) cadres de délimitation de texte et de cadres ; 2) texte (séquences de caractères) en japonais et en anglais ; et 3) l'ordre de lecture des cadres et du texte.
Pour former le modèle, l’équipe a préparé 842 097 paires de pages de bandes dessinées en japonais et en anglais, avec un total de 3 979 205 paires de phrases japonais-anglais.La méthode spécifique peut être trouvée dans le document. L’évaluation finale de l’effet du modèle est effectuée manuellement. L'équipe Mantra a invitéCinq traducteurs professionnels japonais-anglais, notez les phrases avec un programme d'évaluation de traduction professionnel.
Derrière le projet : des âmes intéressantes qui apprennent ensemble
Actuellement, ce document a été inclus dans l'AAAI 2021 et les travaux de production progressent également régulièrement. D’après le compte Twitter de l’équipe Mantra, nous pouvons constater que de nombreux comics ont utilisé avec succès Mantra pour la traduction automatique.
Un tel projet de trésor a été réalisé par deux doctorants de l’Université de Tokyo. Le PDG Shonosuke Ishiwatari et le directeur technique Ryota Hinami sont tous deux titulaires d'un doctorat de l'Université de Tokyo et ont fondé l'équipe Mantra en 2020.

PDG Shonosuke Ishiwa,Il est entré en licence au Département des sciences de l'information de l'Université de Tokyo en 2010 et a obtenu un doctorat. en 2019.Il se concentre principalement sur la recherche et le développement dans le domaine du traitement du langage naturel, y compris la traduction automatique et la génération de dictionnaires, et est également le deuxième auteur de cet article.
Il convient de mentionner qu’Ishiwa Xiangzhisuke possède une riche expérience en recherche. Non seulement il a été boursier d'échange à la CMU, mais il a également effectué un stage chez Microsoft Research Asia à Pékin pendant six mois de 2016 à 2017. À cette époque, il était engagé dans des recherches sur le NLC (Natural Language Computing) dans l'équipe du chercheur en chef de la MSRA, Liu Shujie.
Le directeur technique Hinami Ryotaishi est entré à l'école la même année que Shonosuke et s'est concentré sur le domaine de la reconnaissance d'images.En 2016-17, j'ai effectué un stage chez Microsoft Research Asia avec Shonosuke Ishiwa.
Ce couple d'amis aux compétences complémentaires a réalisé la plupart des travaux de Mantra. N'est-ce pas enviable de la quantité de cheveux aux résultats ?
Si vous souhaitez en savoir plus sur Mantra, vous pouvez consulter le journal (https://arxiv.org/abs/2012.14271)、Site officiel du projet(https://mantra.co.jp/)Ou téléchargez le jeu de données(https://orion.hyper.ai/datasets/14137), pour des recherches plus approfondies.








