Command Palette
Search for a command to run...
Libérez l'artiste Original ! Wav2Lip Utilise l'IA Pour Écouter De La Musique Et Synchroniser Les Mouvements Des Lèvres Des Personnages

« voir c'est croire »Cela est devenu inefficace face à la technologie de l’IA. Les technologies de changement de visage et de synchronisation labiale émergent en un flux infini, et les effets deviennent de plus en plus réalistes. Aujourd'hui, nous allons vous présenter Wav2Lip Le modèle n'a besoin que d'une vidéo originale et d'un audio cible pour les combiner en un seul.
Ces dernières années, les films d'animation hollywoodiens ont remporté à plusieurs reprises plus d'un milliard de dollars au box-office, comme « Zootopia » et « La Reine des neiges », tous d'excellente qualité.Prenons simplement l'exemple des mouvements des lèvres : c'est très rigoureux, et les mouvements des lèvres des personnages animés sont presque identiques à ceux des vraies personnes.
Pour obtenir un tel effet, un processus très complexe est nécessaire, qui nécessite d’énormes ressources humaines et matérielles. C'est pourquoi, pour réduire les coûts, de nombreux producteurs d'animation n'utilisent que des mouvements de lèvres relativement simples.
Aujourd’hui, l’IA s’efforce de faciliter le travail des artistes conceptuels. Une équipe de l'Université d'Hyderabad en Inde et de l'Université de Bath au Royaume-Uni a publié un article dans ACM MM2020 cette année« Un expert en synchronisation labiale est tout ce dont vous avez besoin pour une génération de voix et de lèvres dans la nature »,Un modèle d'IA appelé Wav2Lip est proposé, qui n'a besoin que d'une vidéo d'une personne et d'une voix cible pour combiner les deux en une seule, permettant aux deux de fonctionner ensemble de manière transparente.
Technique de synchronisation labiale Wav2Lip, l'effet est tellement remarquable
Il existe en fait de nombreuses technologies pour la synchronisation labiale. Même avant l’émergence de la technologie basée sur l’apprentissage profond, certaines technologies faisaient correspondre la forme des lèvres du personnage au signal vocal réel.
Mais Wav2Lip présente des avantages absolus parmi toutes les méthodes. D'autres méthodes existantes sont principalement basées sur des images statiques pour produire des vidéos synchronisées sur les lèvres qui correspondent à la voix cible, mais la synchronisation labiale ne fonctionne souvent pas bien pour les personnages dynamiques et parlants.
Wav2Lip peut effectuer directement une conversion labiale sur des vidéos dynamiques et générer des résultats vidéo correspondant à la voix cible.
De plus, non seulement des vidéos mais aussi des synchronisations labiales avec des images animées sont disponibles, vos packs d'émoticônes seront donc enrichis à partir de maintenant !

L'évaluation manuelle a montréPar rapport aux méthodes existantes, les vidéos générées par Wav2Lip surpassent les méthodes existantes dans plus de 90 % des cas.
Quelle est l’efficacité du modèle ? Super Neuro a effectué quelques tests. La vidéo suivante montre l'effet de fonctionnement de la démo officielle. Les supports d'entrée sont les supports de test fournis par le fonctionnaire, ainsi que les supports de test chinois et anglais sélectionnés par Super Neural Network.
Les personnages de la vidéo d'origine ne parlent pas
Grâce au fonctionnement du modèle d'IA, la forme des lèvres du personnage est synchronisée avec la voix d'entrée
On peut voir que l'effet est parfait dans la vidéo d'animation de la démo officielle. Dans le test Super Neural Real Person, à part une légère déformation et un tremblement des lèvres, l'effet global de synchronisation des lèvres est toujours relativement précis.
Le tutoriel est sorti, apprenez en trois minutes
Après avoir vu cela, êtes-vous également impatient de l'essayer ? Si vous avez déjà une idée audacieuse, pourquoi ne pas commencer maintenant ?
Actuellement, le projet est open source sur GitHub, et l'auteur fournit des démonstrations interactives, des notebooks Colab et du code de formation complet, du code d'inférence, des modèles pré-entraînés et des tutoriels.
Les détails du projet sont les suivants :
Nom du projet:Wav2Lip
Adresse GitHub :
https://github.com/Rudrabha/Wav2Lip
Environnement d'exploitation du projet :
- Langue : Python 3.6+
- Programme de traitement vidéo : ffmpeg
Téléchargez le modèle de détection de visage pré-entraîné :
https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth
En plus de préparer l'environnement ci-dessus, vous devez également télécharger et installer les packages logiciels suivants :
- librosa==0.7.0
- numpy==1.17.1
- opencv-contrib-python>=4.2.0.34
- opencv-python==4.1.0.25
- tensorflow==1.12.0
- torche==1.1.0
- torchvision==0.3.0
- tqdm==4.45.0
- nombre==0,48
Cependant, vous n’avez pas besoin de vous préparer à ces procédures fastidieuses.Il vous suffit de préparer une photo/vidéo d'une personne (une personne CGI est également acceptable) + un audio (un audio synthétique est également acceptable).Vous pouvez l'exécuter en un seul clic sur la plate-forme de service de conteneur de puissance de calcul d'apprentissage automatique domestique.
Portail:https://openbayes.com/console/openbayes/containers/EiBlCZyh7k7
Actuellement, la plateforme propose également du temps d'utilisation gratuit du vGPU chaque semaine, afin que chacun puisse facilement terminer le didacticiel.
Le modèle comporte trois pondérations : Wav2Lip, Wav2Lip+GAN et Expert Discriminator. Parmi eux, les effets des deux derniers sont nettement meilleurs que l’utilisation du modèle Wav2Lip seul. Les poids utilisés dans ce tutoriel sont Wav2Lip+GAN.
Les auteurs du modèle soulignent queTous les résultats de son code source ouvert ne doivent être utilisés qu'à des fins de recherche/académiques/personnelles,Le modèle est formé sur la base de l'ensemble de données LRS2 (Lip Reading Sentences 2), donc toute forme d'utilisation commerciale est strictement interdite.
Pour éviter les abus de la technologie, les chercheurs recommandent également fortement que tout contenu créé à l'aide du code et des modèles de Wav2Lip soit marqué comme synthétique.
La technologie clé derrière tout cela : le discriminateur de synchronisation labiale
Comment Wav2Lip écoute-t-il l'audio et synchronise-t-il les lèvres avec autant de précision ?
On dit que la clé pour réaliser une percée est :Les chercheurs ont utilisé un discriminateur de synchronisation labiale,Cela oblige le générateur à produire en continu des mouvements de lèvres précis et réalistes.
De plus, cette étude améliore la qualité visuelle en utilisant plusieurs images consécutives au lieu d’une seule image dans le discriminateur et en utilisant une perte de qualité visuelle (plutôt qu’une simple perte de contraste) pour tenir compte des corrélations temporelles.
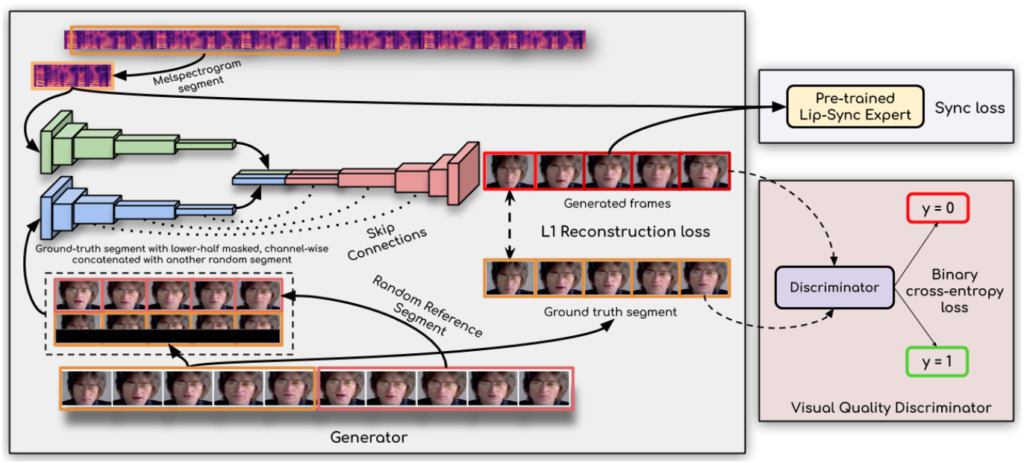
Les chercheurs ont déclaré :Leur modèle Wav2Lip est presque universel, applicable à n’importe quel visage, n’importe quelle voix, n’importe quelle langue, et peut atteindre une grande précision pour n’importe quelle vidéo.Il peut être fusionné de manière transparente avec la vidéo originale, peut également être utilisé pour convertir des visages animés et l'importation de discours synthétisés est également possible.
Il est concevable que cet artefact puisse créer une autre vague de vidéos fantômes...
Adresse du document :
Adresse de démonstration :
https://bhaasha.iiit.ac.in/lipsync/
-- sur--








