Command Palette
Search for a command to run...
Contenant Près De 200 000 Livres, l'ensemble De Données De Formation De Niveau OpenAI Est En Ligne

Vous souhaitez également former un modèle GPT puissant comme OpenAI, mais vous souffrez du manque d'ensembles de données de formation suffisants ? Récemment, un internaute de la communauté Reddit a téléchargé un ensemble de données en texte brut contenant près de 200 000 livres. Former un modèle GPT de première classe n’est plus un rêve.
Récemment, un article de ressource brûlant dans la communauté de l'apprentissage automatique « Un ensemble de données de 196 640 manuels en texte clair pour la formation de grands modèles linguistiques tels que GPT »Cela a déclenché une discussion animée.
Cet ensemble de données contient des liens de téléchargement pour tous les grands corpus de textes à partir de septembre 2020. De plus, il contient le texte brut de tous les livres de Bibliotik (une bibliothèque de ressources de livres en ligne), ainsi que beaucoup de code pour la formation.
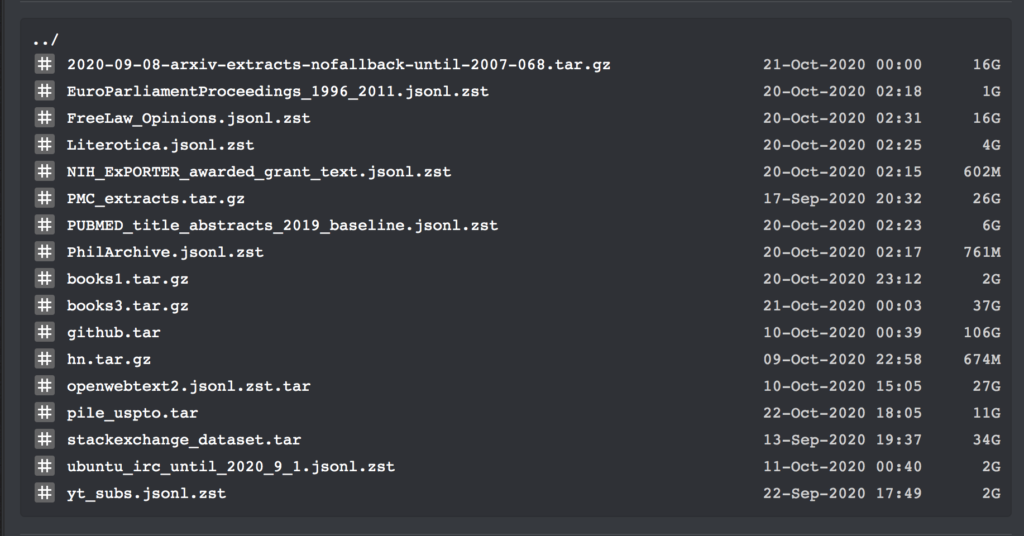
Hier encore, l'internaute Shawn Presser a publié un ensemble de données en texte brut dans la communauté d'apprentissage automatique de Reddit, qui a reçu des éloges unanimes.
Ces ensembles de données contiennent un total de 196 640 volumes de données en texte brut, qui peuvent être utilisés pour former de grands modèles linguistiques tels que GPT.
Étant donné que cet ensemble de données contient plusieurs ensembles de données et codes de formation, nous n’entrerons pas dans les détails ici. Nous ne listerons que les informations spécifiques des ensembles de données books1 et books3 :
Ensemble de données en texte brut du livre
Publié par : Shawn Presser
Quantité incluse :livres1 : 1800 livres ; livre3 : 196 640 livres
Format des données :format txt
Taille des données :livres1 : 2,2 Go ; livres3 : 37 Go
Heure de mise à jour :Octobre 2020
Adresse de téléchargement :https://orion.hyper.ai/datasets/13642
Selon l’organisateur de l’ensemble de données, Shawn Presser, la qualité de ces ensembles de données est très élevée. Il lui a fallu environ une semaine pour réparer le script epub2txt pour le seul ensemble de données books1.
En outre, il a également déclaré :L’ensemble de données books3 semble être similaire au mystérieux ensemble de données « books2 » de l’article d’OpenAI.Cependant, comme OpenAI n’a pas fourni d’informations détaillées à ce sujet, il est impossible de comprendre les différences entre les deux.
Cependant, à son avis, cet ensemble de données est extrêmement proche de l’ensemble de données d’entraînement de GPT-3. Avec cela, l’étape suivante consiste à former un modèle de langage NLP comparable à GPT-3. Bien sûr, il y a une condition : il faut aussi préparer suffisamment de GPU.

Selon l'introduction,L'ensemble de données books1 contient 1 800 livres, tous issus du grand corpus de textes BookCorpus.Il s’agit notamment de poésie, de romans, etc.
Par exemple, « Shades of Gray: Noir, City Shrouded By Darkness » de l'écrivaine américaine Kristie Lynn Higgins, « Animal Theater » de Benjamin Broke et « America One » de T.I. Patauger.
Le puissant GPT-3 est soutenu par l'ensemble de données de formation
Les amis qui s'intéressent au domaine du traitement du langage naturel savent qu'en mai de cette année, le modèle de traitement du langage naturel GPT-3, construit par OpenAI à un coût énorme, a attiré une grande attention dans l'industrie avec son incroyable capacité de génération de texte, et est populaire depuis.
GPT-3 peut non seulement répondre aux questions, traduire et rédiger des articles de meilleure qualité, mais dispose également de certaines capacités de calcul mathématique. La raison pour laquelle il possède ces puissantes capacités est indissociable de l’énorme ensemble de données de formation qui le sous-tend.
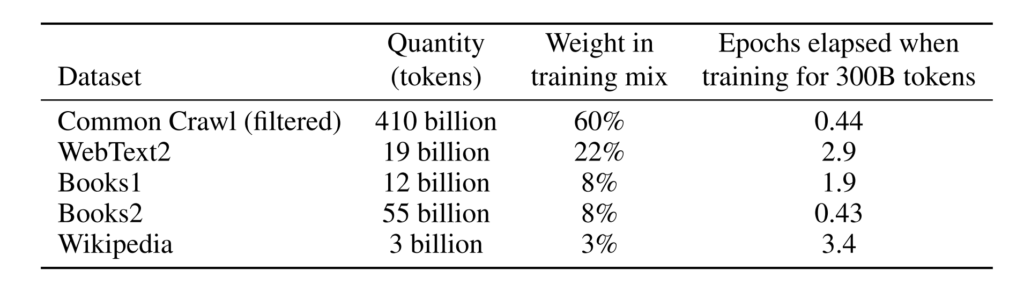
Selon l'introduction,L’ensemble de données de formation utilisé par GPT-3 est très volumineux. Il est basé sur l'ensemble de données CommonCrawl contenant près de 1 000 milliards de mots, de textes Web, de données, de Wikipédia et d'autres données. Le plus grand ensemble de données qu’il utilise a une capacité de 45 To avant traitement.Ses coûts de formation ont également atteint le montant stupéfiant de 12 millions de dollars américains.
Des ensembles de données de formation plus volumineux et davantage de paramètres de modèle placent GPT-3 loin devant dans les modèles de traitement du langage naturel.
Cependant, pour les développeurs ordinaires, s'ils souhaitent former un modèle de langage de première classe, sans parler du coût élevé de la formation, ils seront bloqués à l'étape de la formation de l'ensemble de données.
Par conséquent, l'ensemble de données apporté par Shawn Presser a sans aucun doute résolu ce problème, et certains internautes ont déclaré qu'ils avaient économisé d'énormes coûts grâce à ce travail.
Super Neuro a maintenant déplacé l'ensemble de données books1 vers https://orion.hyper.ai,Recherchez le mot-clé « livre » ou « texte », ou cliquez sur le texte original pour obtenir l'ensemble de données.
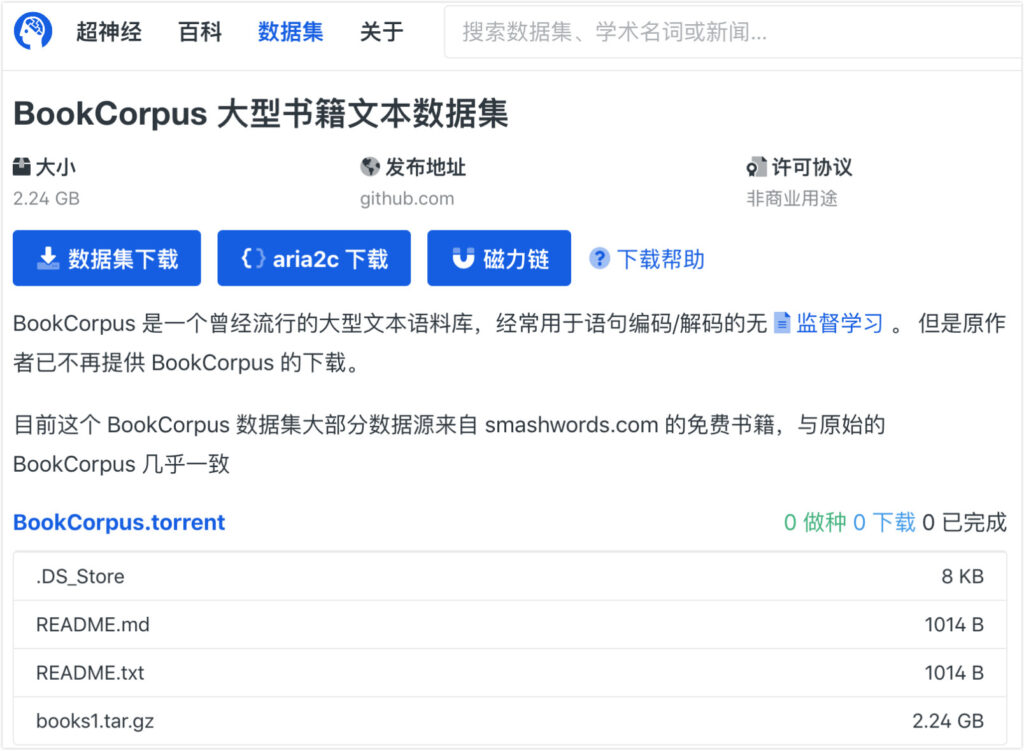
D'autres ensembles de données peuvent être obtenus à partir des liens suivants :
Adresse de téléchargement du jeu de données books3 :
https://the-eye.eu/public/AI/pile_preliminary_components/books3.tar.gz
Adresse de téléchargement du code de formation :
https://the-eye.eu/public/AI/pile_preliminary_components/github.tar
Publication originale sur Reddit :https://www.reddit.com/r/MachineLearning/comments/ji7y06/p_dataset_of_196640_books_in_plain_text_for/
-- sur--








