Command Palette
Search for a command to run...
Damedane, La Chanson Divine De B Station : L'essence Réside Dans Le Changement De Visage, Vous Pouvez l'apprendre En Cinq Minutes

Les technologies de l’IA qui changent le visage émergent en un flux infini, mais chaque génération est meilleure que la précédente. Récemment, un modèle de mouvement de premier ordre à changement de visage d'IA publié dans NeurIPs 2019 est devenu populaire et son effet de transfert d'expression est meilleur que d'autres méthodes dans le même domaine. Récemment, cette technologie a provoqué une nouvelle tendance sur la station B...
Récemment, une vague de vidéos au style trop « brut » (argot de la station B, signifiant diablement drôle) a émergé sur Bilibili, avec des millions de vues, ce qui les rend assez populaires.
Maîtrisez toutes vos compétences et utilisez «Mouvement du premier ordre, modèle de mouvement du premier ordre»Le projet de changement de visage d'IA a généré une variété de vidéos avec des styles uniques.
Par exemple, Jacky Cheung, Du Fu, Tang Monk et l'émoji tête de panda ont chanté « Damedane » et « Unravel » avec beaucoup d'émotion... L'image ressemble à ceci :


Si vous n’êtes pas satisfait des images animées, passons directement à la vidéo :
La version du chat qui pleure de la chanson de lavage de cerveau "damedane", qui a été jouée 2,113 millions de fois jusqu'à présent, source : B station Up master thick hair Hu Tutu
Je dois dire que c'est un peu addictif... Vous pouvez vous rendre à la petite station cassée pour chercher d'autres œuvres à regarder.
Ces vidéos ont attiré d'innombrables internautes qui ont voulu s'y essayer et ont laissé des messages demandant des tutoriels. Ensuite, examinons les technologies qui permettent d’obtenir ces effets de changement de visage (la racine de tous les maux) :Modèle de mouvement du premier ordre.
Learning Garden B Station, plusieurs tutoriels pour vous apprendre le playback
Jusqu'à présent, des technologies similaires de changement de visage et de synchronisation labiale ont émergé en un flot incessant, et chaque fois qu'une technologie est proposée, elle déclenche une vague d'engouement pour le changement de visage.
Le modèle de mouvement du premier ordre est très populaire car il est efficace pour optimiser les traits du visage et la forme des lèvres, et il est facile à utiliser et efficace à mettre en œuvre.
Par exemple, si vous souhaitez modifier le visage de «damedane» au début de l'article,Cela ne prend que quelques secondes à réaliser et peut être appris en cinq minutes.
La plupart des téléchargeurs sur Bilibili choisissent Google Drive et Colab pour réaliser des tutoriels. Compte tenu de la difficulté de contourner le pare-feu, nous avons sélectionné un tutoriel d'un des maîtres et utilisé le service de conteneur de puissance de calcul d'apprentissage automatique national (https://openbayes.com), et maintenant vous pouvez également profiter du temps d'utilisation gratuit du vGPU chaque semaine pour terminer facilement ce tutoriel.
Mise à jour 2020-09-30 : Actuellement, bilibili a supprimé toutes les vidéos liées au « changement de visage par IA », donc l'équipe OpenBayes a ajouté une version texte correspondante du tutoriel étape par étape :
Vous pouvez compléter votre propre «damedane» en moins de 5 minutes
Ce tutoriel vidéo explique étape par étape, afin que même un novice puisse facilement apprendre cette technique de changement de visage. Le maître up a également téléchargé le notebook sur la plateforme, et il peut être utilisé directement en le clonant simplement en un clic.
Cependant, de nombreux hôtes techniques d'Up ont déclaré qu'en plus du divertissement, ils réalisent des vidéos pour des échanges techniques, ils espèrent donc que tout le monde n'en abusera pas de manière malveillante.
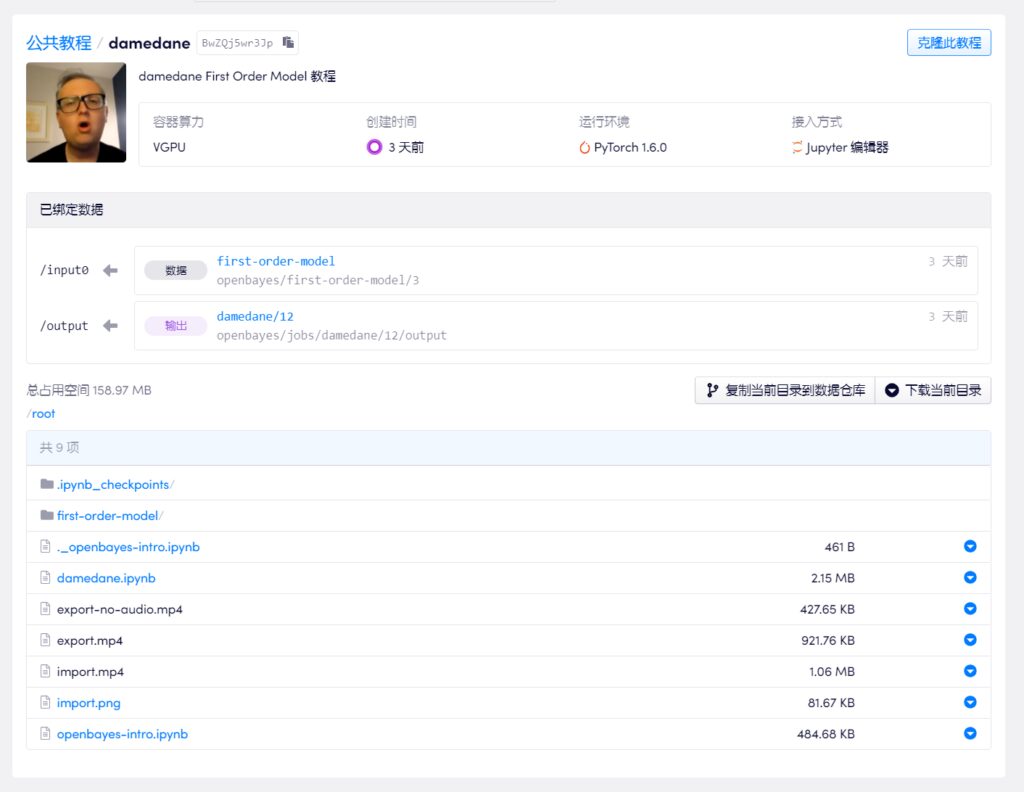
Adresse du tutoriel vidéo :
https://openbayes.com/console/openbayes/containers/BwZQj5wr3Jp
Adresse Github du projet d'origine :
https://github.com/AliaksandrSiarohin/first-order-model
Un autre outil qui change de visage, à quoi sert-il ?
Le modèle de mouvement du premier ordre provient d'un article présenté lors de la conférence de haut niveau NeurlPS 2019.Modèle de mouvement du premier ordre pour l'animation d'images,Les auteurs sont de l'Université de Trente en Italie et snap.

Comme vous pouvez le constater d'après le titre,Le but de cet article est de faire bouger des images statiques.Étant donné une image source et une vidéo de conduite, faites en sorte que l'image de l'image source se déplace avec les actions de la vidéo de conduite. C'est-à-dire faire bouger tout.
L’effet est illustré dans la figure ci-dessous. Le coin supérieur gauche est la vidéo de conduite, et le reste sont des images statiques sources :

Composition du cadre du modèle
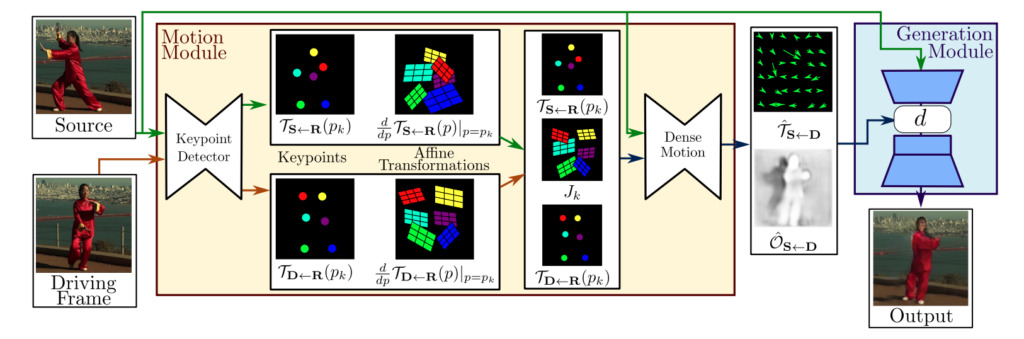
En général, le cadre du modèle de mouvement du premier ordre se compose de deux modules :Module d'estimation de mouvement et module de génération d'images.
Module d'estimation de mouvement :Grâce à l'apprentissage auto-supervisé, les informations sur l'apparence et le mouvement de l'objet cible sont séparées et les caractéristiques sont représentées.
Module de génération d'images :Le modèle modélise les occlusions qui se produisent pendant le mouvement de la cible, puis extrait les informations d'apparence d'une image de célébrité donnée et les combine avec la représentation des caractéristiques précédemment obtenue pour la synthèse vidéo.
En quoi est-il meilleur que le modèle traditionnel ?
Certaines personnes peuvent se demander en quoi cela est différent des méthodes précédentes de changement de visage de l’IA ? L'auteur donne une explication.
L'opération vidéo de changement de visage précédente nécessitait les opérations suivantes :
- En général, il est nécessaire d’effectuer une formation préalable sur les données d’image faciale des deux parties à échanger ;
- Il est nécessaire d'annoter les points clés de l'image source, puis de procéder à la formation du modèle correspondant.
Mais en réalité, il y a moins de données personnelles sur les visages et peu de temps pour la formation.Par conséquent, les modèles traditionnels fonctionnent généralement mieux sur des images spécifiques, mais lorsqu'ils sont utilisés sur le grand public, la qualité est difficile à garantir et ils sont sujets à des pannes.

Par conséquent, la méthode proposée dans cet article résout le problème de la dépendance aux données et améliore considérablement l’efficacité de la génération. Vous souhaitez réaliser un transfert d'expression et d'action,SeulementIl suffit de l'entraîner sur des ensembles de données d'images de la même catégorie.
Par exemple, si vous souhaitez réaliser un transfert d’expression, quel que soit le visage que vous remplacez, il vous suffit de vous entraîner sur l’ensemble de données du visage ; si vous souhaitez réaliser un transfert de mouvement Tai Chi, vous pouvez utiliser l'ensemble de données vidéo Tai Chi pour l'entraînement.
Une fois la formation terminée, en utilisant le modèle pré-entraîné correspondant, vous pouvez faire bouger l'image source avec la vidéo de conduite.

L'auteur a comparé sa méthode avec les méthodes les plus avancées dans ce domaine, X2Face et Monkey-Net. Les résultats ont montré que dans le même ensemble de données, tous les indicateurs de cette méthode ont été améliorés.Sur deux ensembles de données de visage (VoxCeleb et Nemo), notre méthode surpasse également considérablement X2Face, qui a été initialement proposé pour la génération de visages.

-- sur--








