Command Palette
Search for a command to run...
L'ECCV Le Plus Chaud De l'histoire a Ouvert Ses Portes, Et Ces Articles Sont Très Intéressants

L'ECCV 2020, l'une des trois principales conférences internationales dans le domaine de la vision par ordinateur, s'est tenue en ligne du 23 au 27 août. Cette année, l'ECCV a accepté un total de 1 361 articles. Nous avons sélectionné les 15 articles les plus populaires à partager avec les lecteurs.
En raison de l'impact de l'épidémie, l'ECCV 2020 de cette année, comme d'autres conférences de premier plan, est passée du mode hors ligne au mode en ligne et a débuté le 23 août.

ECCV, dont le nom complet est Conférence européenne sur la vision par ordinateur (European International Conference on Computer Vision),Il s'agit de l'une des trois principales conférences internationales sur la vision par ordinateur (les deux autres sont CVPR et ICCV), organisée tous les deux ans.
Bien que l’épidémie de cette année ait perturbé les projets de nombreuses personnes, l’enthousiasme de chacun pour la recherche scientifique et la soumission d’articles reste intact. Selon les statistiques,L'ECCV 2020 a reçu un total de 5 025 soumissions valides, soit plus du double du nombre de soumissions lors de la session précédente (2018), et est donc considéré comme « l'ECCV le plus chaud de l'histoire ».
Finalement, 1 361 articles ont été acceptés pour publication, avec un taux d’acceptation de 27%.Parmi les articles acceptés, on compte 104 articles oraux, représentant 2% du total des soumissions valides, et 161 articles phares, représentant environ 3%. Le reste des papiers sont des affiches.
Estimation de pose, nuage de points 3D, excellente liste d'articles
Quels résultats de recherche passionnants nous a apporté cette année ce grand événement dans le domaine de la vision par ordinateur ?
Nous avons sélectionné 15 articles parmi les articles sélectionnés, couvrant plusieurs directions telles que la détection d'objets 3D, l'estimation de la pose, la classification d'images et la reconnaissance faciale.
Réidentification des piétons « Veuillez ne pas me déranger : Réidentification des piétons sous l'interférence d'autres piétons »

unité:Université des sciences et technologies de Huazhong, Université Sun Yat-sen, Tencent Youtu Lab
résumé:
La réidentification traditionnelle d’une personne suppose que l’image recadrée ne contient qu’une seule personne. Cependant, dans les scènes surpeuplées, les détecteurs standard peuvent générer des cadres de délimitation de plusieurs personnes avec une grande proportion de piétons en arrière-plan ou d'occultations humaines.
Les caractéristiques extraites de ces images avec interférence piétonne peuvent contenir des informations d'interférence, ce qui entraînera des résultats de récupération erronés.
Pour résoudre ce problème, cet article propose un nouveau réseau profond (PISNet). PISNet utilise d’abord le module d’attention guidée par image Query pour améliorer les caractéristiques de la cible dans l’image.
De plus, nous proposons un module d'attention inversée et une fonction de perte de séparation multi-personnes pour favoriser le module d'attention afin de supprimer l'interférence des autres piétons.Notre méthode est évaluée sur deux nouveaux ensembles de données d’interférence piétonne et les résultats montrent qu’elle surpasse les méthodes Re-ID de pointe.

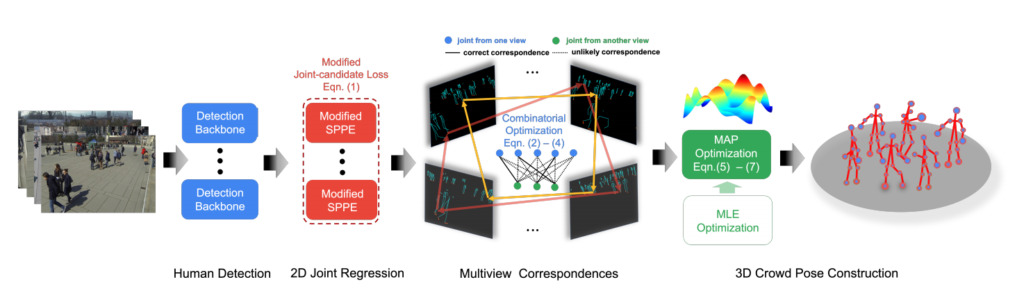
Estimation de pose « Estimation de pose 3D de plusieurs personnes dans des scènes bondées via une géométrie multi-points de vue »

unité:Université Johns Hopkins, Université nationale de Singapour
résumé:
Les contraintes extrêmes sont au cœur de la mise en correspondance des caractéristiques et de l'estimation de la profondeur dans les méthodes actuelles d'estimation de la pose humaine 3D multi-machines. Bien que la formulation fonctionne de manière satisfaisante dans les scènes de foule clairsemées, son efficacité est souvent remise en question dans les scènes de foule denses, principalement en raison de l'ambiguïté de deux sources.
Le premier est l’inadéquation des articulations humaines due à de simples indices fournis par la distance euclidienne entre les articulations et les lignes épipolaires. Le deuxième problème est le manque de robustesse dû à la minimisation naïve du problème sous forme de moindres carrés.
Dans cet article,Nous partons de la formulation d’estimation de pose 3D multi-personnes et la reformulons comme une estimation de pose de foule.Notre approche se compose de deux éléments clés : un modèle graphique pour une correspondance rapide entre vues croisées et un estimateur a posteriori maximum (MAP) pour la reconstruction de la pose humaine en 3D. Nous démontrons l’efficacité et la supériorité de notre approche sur quatre ensembles de données de référence.
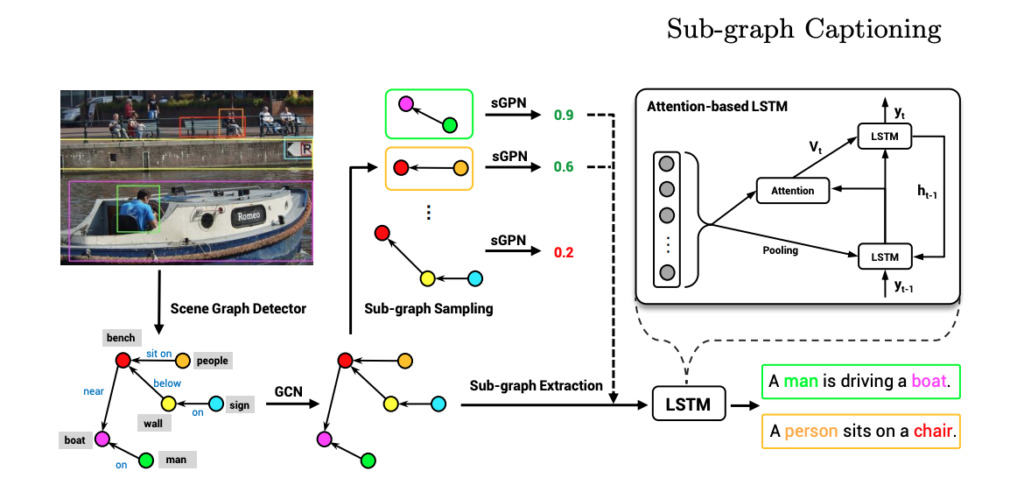
Description d'images 《Génération de description en langage naturel via la décomposition de graphes de scènes》

unité:Laboratoire d'IA Tencent, Université du Wisconsin-Madison
résumé:
Cet article propose une méthode de génération de description en langage naturel basée sur la décomposition de graphes de scènes.
Utiliser le langage naturel pour décrire des images est une tâche difficile. Cet article examine l’expression du graphe de scène d’image et propose une méthode pour générer une description en langage naturel des images basée sur la décomposition du graphe de scène. Le cœur de cette méthode est de décomposer le graphe de scène correspondant à une image en plusieurs sous-graphes, où chaque sous-graphe correspond à une partie du contenu ou à une partie de la zone de l'image.En sélectionnant des sous-graphes importants via un réseau neuronal pour générer une phrase complète décrivant l'image, cette méthode peut générer des descriptions en langage naturel précises, diversifiées et contrôlables.Les chercheurs ont également mené des expériences approfondies et les résultats ont démontré les avantages de ce nouveau modèle.
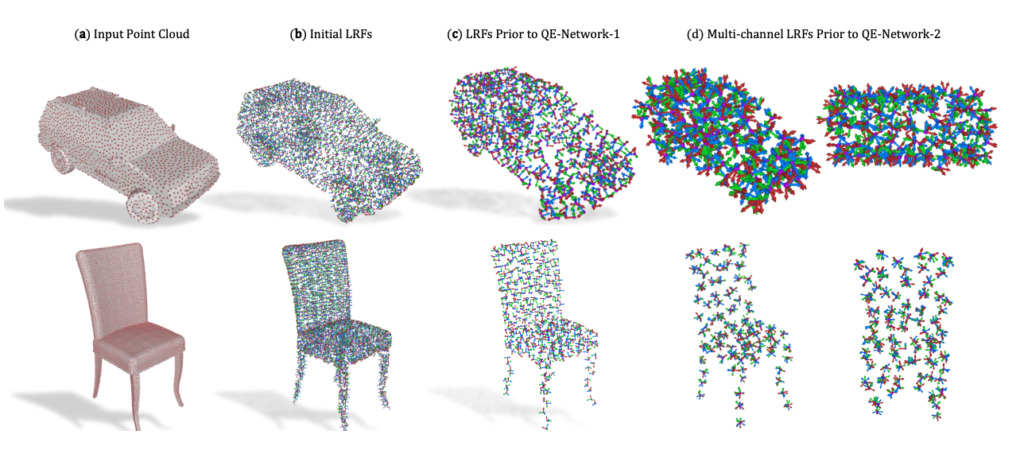
Nuages de points 3D Réseaux de capsules équivariantes quaternioniques pour nuages de points 3D

unité:Université de Stanford, Université technique de Dortmund, Université de Padoue
résumé:
Nous proposons une architecture de capsule 3D pour le traitement des nuages de points qui est équivalente à des groupes SO(3) de rotations, de translations et de permutations d'un ensemble d'entrées non ordonné.
Le réseau fonctionne sur un ensemble clairsemé de cadres de référence locaux calculés à partir du nuage de points d’entrée. Le réseau atteint une variance de bout en bout grâce à une nouvelle couche de capsule de groupe de quaternions 3D, qui comprend un processus de routage dynamique d'équivariance.
Les couches de capsules nous permettent de démêler la géométrie de la pose, ouvrant la voie à des espaces latents plus informatifs et structurés.Ce faisant, nous relions théoriquement le processus de routage dynamique entre les capsules à l'algorithme bien connu de Weiszfeld pour résoudre le problème des moindres carrés pondérés itérativement (IRLS) avec des propriétés de convergence prouvables, obtenant ainsi une estimation de pose robuste à travers les couches de capsules.
Grâce à des capsules de quaternions équivariantes clairsemées, notre architecture permet une classification conjointe des objets et une estimation de l'orientation, que nous validons empiriquement sur des ensembles de données de référence communs.
Reconnaissance faciale « Reconnaissance faciale explicable »

unité:Recherche sur les systèmes et les technologies, Visym Labs
résumé:
La reconnaissance faciale explicable (XFR en abrégé) est le problème consistant à expliquer les résultats de correspondance renvoyés par un outil de comparaison de visages.Cela permet de comprendre pourquoi un détecteur correspond à une identité et pas à une autre.Comprendre ce principe peut aider les gens à faire confiance à la reconnaissance faciale et à l’expliquer.
Dans cet article, nous fournissons la première évaluation complète de référence et de base de XFR. Nous définissons un nouveau schéma d'évaluation, appelé « jeu d'inpainting », qui est un ensemble organisé de 3648 triplets (sonde, partenaire, non-partenaire) provenant de 95 sujets, créant un non-partenaire patché en peignant synthétiquement des traits du visage sélectionnés (tels que le nez, le sourcil ou la bouche).
La tâche de l'algorithme XFR est de générer une carte d'attention du réseau qui indique au mieux quelles régions de l'image de la sonde correspondent à l'image appariée, plutôt que les régions non appariées qui sont peintes pour chaque triplet. Cela fournit une base pour quantifier les régions d’image utiles pour la correspondance des visages.
Enfin, nous fournissons une analyse comparative complète sur cet ensemble de données, en comparant cinq algorithmes de pointe sur trois comparateurs de visages. Ce benchmark comprend deux nouveaux algorithmes, appelés Subtree EBP et Density-based Input Sampling Explanation (DISE), qui surpassent considérablement les techniques de pointe existantes.
Nous montrons également des visualisations qualitatives de ces techniques d'attention réseau sur de nouvelles images et explorons comment ces modèles de reconnaissance faciale explicables peuvent améliorer la transparence et la confiance dans les comparateurs de visages.

Estimation de l'âge 《Synthèse de conversion de la durée de vie en âge》

unité:Université de Washington, Université de Stanford, Adobe Research
résumé:
Nous résolvons le problème de la progression et de la régression de l'âge pour une seule photo - en prédisant à quoi ressemblera une personne dans le futur ou dans le passé.
La plupart des méthodes de vieillissement existantes se limitent à modifier la texture et ignorent les changements de forme de la tête au cours du vieillissement et de la croissance humaine. Cela limite l’applicabilité des méthodes précédentes aux personnes âgées, et l’application de ces méthodes aux photos d’enfants ne produit pas de résultats de haute qualité.
Nous proposons une nouvelle architecture de réseau antagoniste générative image à image multi-domaines dont l'espace latent appris modélise un processus de vieillissement bidirectionnel continu.Le réseau est formé sur l'ensemble de données FFHQ, que nous étiquetons en fonction de l'âge, du sexe et de la segmentation sémantique. Utilisez des classes d’âge fixes comme points d’ancrage pour approximer les transformations d’âge continues.Notre cadre peut prédire des portraits de tête complets allant de 0 à 70 ans sur la base d'une seule photo et modifier la texture et la forme de la tête.Nous présentons des résultats sur une grande variété de photos et d’ensembles de données et montrons des améliorations significatives par rapport à l’état de l’art.

Portail : Documents, codes, tout en un clic
Ce qui précède n'est que la pointe de l'iceberg des milliers d'articles sélectionnés dans l'ECCV 2020. Cependant, face à une quantité massive de 1 361 articles, ce n'est vraiment pas une tâche facile de trouver les articles qui vous intéressent, ainsi que les liens originaux, les codes, etc.
Cependant, un Équipe Paper Digest L’équipe a ouvert la voie aux lecteurs, et trouver des articles et des codes n’est plus un problème.
L'équipe a récemment publié un résumé des points saillants du document ECCV 2020 en une phrase.Chaque article était résumé en une phrase, concise et précise, et l’adresse de l’article était jointe.Permettez aux lecteurs de trouver rapidement les articles qu’ils souhaitent le plus lire.

L'adresse est à votre disposition pour vous permettre de la prendre :
En outre, ils ont également soigneusement compilé 170 articles qui ont publié des codes. Les lecteurs peuvent cliquer directement sur le lien correspondant pour visualiser le code :
De plus, crossminds.ai a également compilé la présentation de l'article oral, et les lecteurs peuvent comprendre la technologie de l'article plus clairement et intuitivement grâce à sa démonstration, ce qui est très intéressant :
https://crossminds.ai/category/eccv%202020/
-- sur--








