Command Palette
Search for a command to run...
Recherche d'information, Planification De Parcours, E-commerce, Quels Sont Les Champs De Bataille Du KDD ?

KDD 2020, la principale conférence internationale dans le domaine de l'exploration de données, débutera la semaine prochaine. Sur les 2 035 articles soumis cette année, 338 ont été acceptés. Parmi eux, les géants technologiques nationaux tels que BAT, Didi et Huawei ont obtenu de bons résultats.
La conférence internationale annuelle sur l'exploration de données et la découverte de connaissances ACM SIGKDD 2020 (Conférence sur la découverte de connaissances et l'exploration de données, appelée KDD),Il se déroulera en ligne du 23 au 27 août.

Avec le développement de la technologie des bases de données et l’accumulation continue de données, le domaine de l’exploration de données a reçu de plus en plus d’attention.
Le nombre de soumissions au KDD a également augmenté à un rythme visible ces dernières années, passant de 1 115 en 2016 à 2 035 cette année. Dans ces travaux, les contributions des Chinois deviennent de plus en plus importantes et les résultats sont très impressionnants.
Le KDD en est à sa 26e année et la force de recherche scientifique du peuple chinois augmente d'année en année
Le KDD a débuté en 1995 et est organisé chaque année par le Comité spécial de l'ACM sur l'exploration de données et la découverte de connaissances (SIGKDD).Recommandé par la CCF (China Computer Federation) comme conférence internationale de classe A.Elle est connue comme la « Coupe du monde » dans le domaine de l’exploration de données.
En tant que conférence internationale de plus haut niveau dans le domaine de l'exploration de données au monde, KDD est célèbre pour son taux d'acceptation strict des articles, avec un taux d'acceptation annuel ne dépassant pas 20%, et cette année ne fait pas exception.
Le 25 mai, KDD 2020 a officiellement annoncé les articles acceptés.Cette année, un total de 1 279 articles ont été soumis au volet recherche (articles universitaires destinés à la communauté de recherche) et 216 ont été acceptés, soit un taux d'acceptation de 16,8%.
756 articles ont été soumis au programme Applied Data Science (le programme pratique pour l'industrie).121 articles ont été acceptés, avec un taux d'acceptation de 16%.
Cette année c'est le 26ème KDD. Selon les statistiques sur le nombre d'articles publiés et de prix remportés, la participation des Chinois au KDD a augmenté d'année en année ces dernières années, leurs performances sont devenues de plus en plus fortes, de plus en plus d'articles ont été sélectionnés et ils ont remporté de nombreux prix.
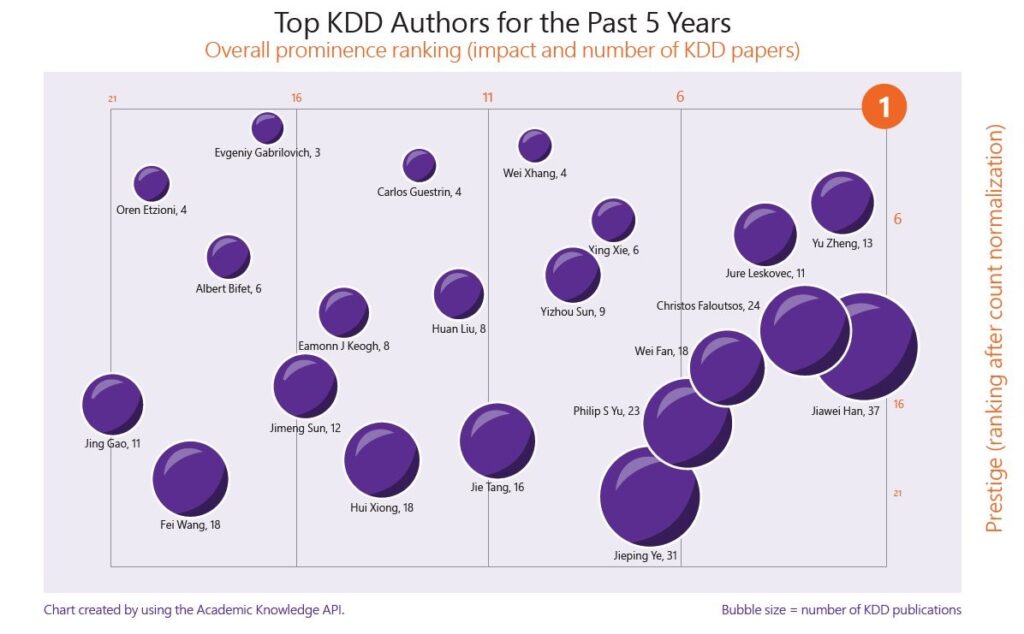
Ces dernières années, les réalisations des grandes entreprises technologiques nationales dans le domaine du KDD sont devenues de plus en plus impressionnantes.
Selon les statistiques, les trois principales sociétés BAT ont publié un total de 12 articles en 2018. Cette année, Alibaba à elle seule a publié 25 articles, Tencent a publié 10 articles, Baidu a publié 9 articles et Didi, Huawei et JD.com ont chacun publié 6 articles.
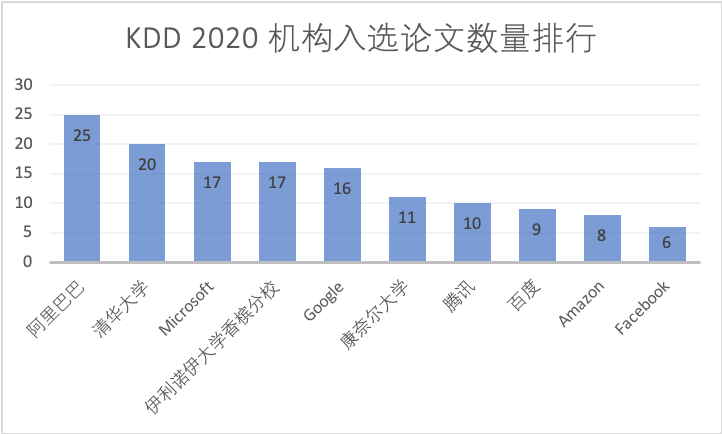
KDD 2020 : Où se situe le champ de bataille pour les grandes entreprises ?
Nous avons trié les articles acceptés des principales entreprises nationales par scénarios d'application pour que chacun puisse les apprendre et s'y référer. Certains de ces articles ont été publiés sur arXiv, vous pouvez donc y jeter un œil.
Recherche d'informations « Extraction des fonctionnalités privilégiées des recommandations Taobao »

Unité : Alibaba
résumé:Les fonctionnalités jouent un rôle important dans les tâches de prédiction du commerce électronique. Pour garantir la cohérence entre la formation hors ligne et la diffusion en ligne, nous utilisons généralement les mêmes fonctionnalités pour les deux. Cependant, cette cohérence ignore certaines caractéristiques distinctives. Par exemple, des fonctionnalités telles que le temps de visite sur une page de détails d'un produit fournissent des informations lors de l'estimation du taux de conversion (CVR), qui est la probabilité qu'un utilisateur achète le produit après avoir cliqué dessus. Cependant, les prédictions CVR doivent être effectuées en ligne avant qu'un clic ne se produise.Nous définissons les fonctionnalités qui sont discriminantes mais qui ne peuvent être utilisées dans la formation que comme fonctionnalités privilégiées. Basé sur la technique de distillation pour combler le fossé entre la formation et l'inférence, cet article propose un algorithme de fractionnement de caractéristiques (PFD).Nous avons mené des expériences sur deux tâches de prédiction de base pour les recommandations Taobao, à savoir le taux de clics pour le classement à gros grain et le CVR pour le classement à grain fin. En extrayant les fonctionnalités interactives interdites lors de la diffusion du CTR et les fonctionnalités post-hoc pour le CVR, nous obtenons des améliorations significatives par rapport à leurs bases de référence solides. Lors des tests A/B en ligne, les mesures de clic se sont améliorées de +5,0% dans la tâche CTR. Dans la tâche CVR, la métrique de conversion est améliorée de 2,3%. De plus, en abordant plusieurs problèmes liés à l’entraînement PFD, nous obtenons une vitesse d’entraînement comparable comme base de référence sans aucune distillation.
Adresse du document :
https://arxiv.org/abs/1907.05171
Recherche d'informations « Cadre de recommandation multi-intérêts contrôlable »

Unité : Alibaba
résumé:Ces dernières années, avec le développement rapide de la technologie d’apprentissage en profondeur, les réseaux neuronaux ont été largement utilisés dans les systèmes de recommandation de commerce électronique. Nous formalisons le problème de recommandation du système de recommandation comme un problème de recommandation séquentielle, visant à prédire le prochain élément avec lequel un utilisateur est susceptible d'interagir. Les travaux récents donnent généralement une intégration holistique de la séquence de comportement de l'utilisateur. Cependant, une intégration utilisateur unifiée ne peut pas refléter les multiples intérêts d’un utilisateur sur une période donnée. Dans cet article, nous proposons un nouveau cadre multi-intérêts contrôlable pour la recommandation séquentielle appelé ComiRec. Notre module multi-intérêts capture plusieurs intérêts à partir des séquences de comportement des utilisateurs et peut être utilisé pour récupérer des éléments candidats à partir d'un pool d'éléments à grande échelle. Ces éléments sont ensuite introduits dans un module d’agrégation pour obtenir des informations de recommandation globales. Le module d’agrégation utilise des facteurs contrôlables pour équilibrer la précision et la diversité des recommandations. Nous menons des expériences de recommandation séquentielle sur deux ensembles de données du monde réel : Amazon et Taobao.Les résultats expérimentaux montrent que notre cadre permet d’obtenir des améliorations significatives par rapport aux modèles de pointe. Notre cadre a également été déployé avec succès sur la plateforme cloud distribuée hors ligne d'Alibaba.
Adresse du document :
https://arxiv.org/abs/2005.09347
Recherche d'informations « Un cadre de recommandation précis et diversifié basé sur un réseau neuronal convolutif à graphes bayésiens »

Entreprise : Huawei
résumé:Dans les systèmes de recommandation, l’apprentissage précis de la représentation des utilisateurs et des éléments est un sujet très important. Avec les recherches approfondies et l’application des réseaux convolutifs graphiques, l’application des réseaux convolutifs graphiques aux systèmes de recommandation a attiré de plus en plus d’attention. Les modèles de recommandation basés sur des graphiques existants considèrent tous le graphique d’interaction utilisateur-élément observé comme la vérité fondamentale entre les utilisateurs et les éléments. Cependant, dans le contexte des systèmes de recommandation, ce paramètre n’est pas toujours raisonnable. Par exemple, ce paramètre traitera les interactions sans arêtes dans le graphique d’interaction comme des exemples négatifs, et de telles interactions non observées peuvent être des interactions potentielles dans le futur ; d'autre part, certains bords observés peuvent être irréels ou causés par du bruit. Pour résoudre ce problème,Dans ce travail, nous utilisons le réseau convolutionnel de graphes bayésiens (BGCN) pour modéliser l'incertitude dans les graphes d'interaction utilisateur-élément.
Nous proposons une fonction de perte BPR détaillée pour le processus de formation et discutons également en détail de la manière de faire des prédictions dans le cadre de notre modèle. Nous avons validé notre modèle sur quatre ensembles de données publics et avons constaté que notre modèle BGCN surpassait les modèles de recommandation basés sur des graphiques existants dans toutes les mesures d'évaluation. Nous avons également vérifié cela sur les ensembles de données de produits et constaté que la précision du modèle BGCN était également améliorée.De plus, nous avons également constaté que les résultats de recommandation de notre modèle BGCN prennent en compte à la fois la précision et la diversité, et que l'effet de recommandation sur les utilisateurs « à démarrage à froid » est plus significatif.
Liens connexes :
https://zhuanlan.zhihu.com/p/142812078
Planification des itinéraires « Polestar : un moteur de transport public intelligent, efficace et national »

Unité : Baidu
résumé:Les transports publics jouent un rôle important dans la vie quotidienne des gens. Il a été prouvé que les transports publics sont plus écologiques, plus efficaces et plus économiques que toute autre forme de transport. Cependant, à mesure que les réseaux de transport deviennent de plus en plus vastes et que les situations de déplacement deviennent plus complexes, il devient difficile pour les gens de trouver efficacement le meilleur itinéraire d’un endroit à un autre via les systèmes de transport public. À cette fin, dans cet article, nous proposons Polestar, un moteur basé sur les données pour un routage intelligent et efficace des transports publics. Plus précisément, nous proposons d’abord un nouveau modèle de graphique de transport public (PTG) pour les systèmes de transport public avec différents coûts de déplacement, tels que le temps ou la distance. Nous avons ensuite introduit un généralAlgorithmes de recherche d'itinéraire et méthode de liaison de site efficace pour générer efficacement des itinéraires candidats. Sur cette base, nous proposons un modèle de classement des candidats à double chemin pour capturer les préférences des utilisateurs dans des situations de voyage dynamiques. Enfin, des expériences sur deux ensembles de données réelles démontrent les avantages de NorthStar en termes d’efficacité et d’efficience.En fait, début 2019, Polestar était déjà déployé sur Baidu Maps, l’un des plus grands services de cartographie au monde. Jusqu’à présent, Polaris a fourni des services à plus de 330 villes, répondu à plus de 100 millions de requêtes par jour et obtenu une augmentation significative des taux de clics des utilisateurs.
Adresse du document :
https://arxiv.org/abs/2007.07195
Planification de chemin Réseaux convolutifs de graphes spatio-temporels hybrides : amélioration de la prévision du trafic grâce aux données de navigation

Unité : Alibaba
résumé:Les prévisions de trafic suscitent un intérêt croissant ces derniers temps en raison de la popularité des services de navigation en ligne, du covoiturage et des projets de villes intelligentes. En raison de la nature non stationnaire du trafic routier, le manque d’informations contextuelles limitera fondamentalement la précision de la prédiction. Pour résoudre ce problème, nous proposons un réseau convolutionnel de graphes spatio-temporels hybrides (H-STGCN), capable de « déduire » les temps de trajet futurs en exploitant les données de volume de trafic à venir. Plus précisément, nous proposons un algorithme permettant d’obtenir le trafic à venir à partir d’un moteur de navigation en ligne. En utilisant une relation flux-densité linéaire par morceaux, une nouvelle structure de transformateur convertit le volume entrant en un temps de trajet équivalent. Nous combinons ce signal avec le signal de temps de trajet couramment utilisé, puis appliquons une convolution graphique pour capturer les dépendances spatiales.En particulier, nous construisons une matrice d’adjacence composite qui reflète la proximité du transport inné. Nous menons des expériences approfondies sur des ensembles de données du monde réel. Les résultats montrent que H-STGCN surpasse considérablement les méthodes de pointe sur diverses mesures, en particulier dans la prédiction de la congestion non répétitive.
Adresse du document :
https://arxiv.org/abs/2006.12715
Planification des parcours « Prédiction des effets de traitement individuels dans les compétitions par équipes à grande échelle dans le cadre de l'économie du vélo partagé »

Unité : Didi
résumé:Pour maximiser l'engagement cumulatif des utilisateurs (par exemple, les clics cumulés) dans les recommandations séquentielles, il faut généralement équilibrer deux objectifs potentiellement contradictoires, à savoir rechercher un engagement immédiat plus élevé des utilisateurs (par exemple, le taux de clics) et encourager les utilisateurs à parcourir (c'est-à-dire plus d'articles).Les travaux existants étudient souvent ces deux tâches séparément, ce qui conduit souvent à des résultats sous-optimaux.Dans cet article, nous étudions ce problème dans une perspective d’optimisation en ligne et proposons un cadre flexible et pratique pour échanger explicitement un temps de navigation utilisateur plus long et un engagement utilisateur immédiat plus élevé. Plus précisément, en considérant les éléments comme des actions, les demandes des utilisateurs comme des états et les départs des utilisateurs comme des états absorbants, nous formulons le comportement de chaque utilisateur comme un processus de décision de Markov personnalisé (MDP), réduisant ainsi le problème de maximisation de l'engagement cumulatif des utilisateurs à un problème de chemin le plus court stochastique (SSP). Parallèlement, grâce à l’estimation immédiate des probabilités de participation et de sortie des utilisateurs, il est démontré que le problème SSP peut être résolu efficacement par programmation dynamique.Des expériences sur des ensembles de données du monde réel démontrent l’efficacité de la méthode. De plus, cette méthode a été déployée sur une grande plateforme de commerce électronique, augmentant le nombre cumulé de clics de plus de 7 %.
Adresse du document :
Services aux consommateurs : maximiser l'engagement cumulé des utilisateurs dans les recommandations continues : une perspective d'optimisation en ligne

Unité : Alibaba
résumé:Afin de maximiser l'engagement cumulatif des utilisateurs (par exemple, les clics cumulés) dans les recommandations séquentielles, il est généralement nécessaire d'équilibrer deux objectifs potentiellement contradictoires, à savoir, rechercher un engagement immédiat plus élevé des utilisateurs (par exemple, le taux de clics) et encourager la navigation des utilisateurs (c'est-à-dire une plus grande exposition des articles). Les études existantes étudient souvent ces deux tâches séparément, ce qui conduit souvent à des résultats sous-optimaux.
Dans cet article, nous étudions ce problème dans une perspective d’optimisation en ligne et proposons un cadre flexible et pratique pour échanger explicitement un temps de navigation utilisateur plus long et un engagement utilisateur immédiat plus élevé. Plus précisément, en considérant les éléments comme des actions, les demandes des utilisateurs comme des états et les départs des utilisateurs comme des états absorbants, nous formulons le comportement de chaque utilisateur comme un processus de décision de Markov personnalisé (MDP) et simplifions le problème de maximisation de la participation cumulative des utilisateurs en un problème de chemin le plus court stochastique (SSP). Dans le même temps, en estimant les probabilités instantanées de participation et de sortie des utilisateurs, il est prouvé que la programmation dynamique peut résoudre efficacement le problème SSP.Nos expériences sur des ensembles de données réels démontrent l’efficacité de notre approche. De plus, cette méthode a été déployée sur une grande plateforme de commerce électronique, augmentant le nombre cumulé de clics de plus de 7 %.
Adresse du document :
Services aux consommateurs « Créer des chatbots intelligents pour le service client : apprendre à répondre rapidement »

Unité : Didi
résumé:
Ces dernières années, les chatbots intelligents ont été largement utilisés dans le domaine du service client. L’un des principaux défis des chatbots pour maintenir une conversation fluide avec les clients est de répondre au bon moment. Cependant, la plupart des chatbots avancés suivent une approche interaction par interaction.Ces chatbots répondent après chaque déclaration du client, ce qui peut dans certains cas conduire à des réponses inappropriées et induire en erreur le processus de conversation.
Dans cet article, nous proposons un modèle de déclenchement de réponse multi-tours (MRTM) pour résoudre ce problème. MRTM apprend à partir de conversations homme-machine à grande échelle entre les clients et les agents grâce à un système d'apprentissage auto-supervisé.Il utilise la relation de correspondance sémantique entre le contexte et la réponse pour former un modèle de correspondance sémantique et obtient le poids des énoncés co-occurrents dans le contexte grâce à un mécanisme d'auto-attention asymétrique. Les pondérations sont ensuite utilisées pour déterminer si un contexte donné doit être pris en compte.
Nous menons des expériences approfondies sur deux ensembles de données de conversation collectés à partir de systèmes de service client en ligne réels. Les résultats montrent que le MRTM surpasse considérablement la ligne de base. De plus, nous avons intégré MRTM dans le chatbot du service client de Didi. En s'appuyant sur sa capacité à identifier le temps de réponse approprié, le chatbot peut agréger progressivement les informations sur plusieurs cycles de conversation et apporter des réponses plus intelligentes au moment opportun.
Adresse du document :
https://dl.acm.org/doi/10.1145/3394486.3403390
Commerce électronique : « Réseaux d'attention à double graphes hétérogènes pour améliorer les performances de recherche en magasin à longue traîne dans le commerce électronique »

Unité : Alibaba
résumé:
Réseaux d'attention à double graphes hétérogènes pour améliorer les performances de la recherche en magasin dans le commerce électronique
Avec l'énorme croissance des utilisateurs et des magasins Taobao, la recherche en magasin est confrontée à plusieurs défis uniques :
1) De nombreux noms de magasins ne peuvent pas exprimer pleinement les produits qu’ils vendent, c’est-à-dire l’écart sémantique entre les requêtes des utilisateurs et les noms de magasins ;
2) En raison du manque d'interaction avec l'utilisateur, il est difficile de fournir de bons résultats de recherche pour les requêtes à longue traîne, et il est difficile de récupérer des magasins à longue traîne qui sont très pertinents pour la requête. Pour relever ces deux défis clés, nous nous tournons vers les réseaux de neurones graphiques (GNN). Spécifiquement,En utilisant les données d'interaction utilisateur issues de la recherche en magasin et de la recherche de produits, nous proposons un réseau d'attention à double graphe hétérogène (DHGAT) intégré à une architecture à deux tours.Tout d’abord, nous construisons un graphique hétérogène dans le contexte de la recherche en magasin en exploitant la proximité de premier et de second ordre à partir du comportement de recherche des utilisateurs, du comportement de clic des utilisateurs et des enregistrements d’achat des utilisateurs. Ensuite, DHGAT est conçu pour se concentrer sur l’adoption des voisins hétérogènes et homogènes des requêtes et des magasins pour améliorer sa propre représentation, ce qui contribue à atténuer le phénomène de longue traîne.De plus, DHGAT comble le fossé sémantique en combinant les titres des éléments connexes, enrichissant ainsi la sémantique du texte de requête et des noms de magasin.
Adresse du document :
https://dl.acm.org/doi/10.1145/3394486.3403393
E-commerce : Un plan publicitaire avec livraison garantie au niveau de la demande : prédiction et allocation》
Entreprise : Tencent
résumé:Les recherches existantes sur la diffusion de publicité en ligne modélisent généralement le service comme un problème d’allocation d’offre au niveau du groupe ou de l’utilisateur et supposent que les résultats de recherche sont disponibles et que les contrats sont signés, se concentrant ainsi sur la recherche de la meilleure allocation pour la diffusion en ligne. Cependant, ces technologies ne suffisent pas à répondre aux besoins des tendances industrielles actuelles :
1) Les annonceurs recherchent un ciblage plus précis, ce qui nécessite non seulement des attributs au niveau de l’utilisateur, mais également des attributs au niveau de la demande ;
2) Les utilisateurs préfèrent des services publicitaires plus conviviaux, ce qui entraînera davantage de restrictions sur la publicité ;
3) Le goulot d’étranglement pour la croissance des revenus des éditeurs ne réside pas seulement dans les services publicitaires, mais aussi dans la précision des prévisions et les stratégies de vente.
Étant donné que l’échelle des modèles au niveau des demandes est de plusieurs ordres de grandeur supérieure à celle des modèles au niveau de la population ou au niveau de l’utilisateur, la résolution de ces problèmes n’est pas triviale.
Face à ce défi, nous avons proposé un système de planification publicitaire au niveau des demandes et à livraison garantie, conçu de manière holistique, et avons soigneusement optimisé trois éléments clés, notamment la prévision des impressions, les ventes et le service.Notre système a été déployé dans le système de publicité à livraison garantie en ligne de Tencent et a servi des milliards d'utilisateurs pendant près d'un an. Les évaluations sur des données réelles à grande échelle et les performances des systèmes déployés démontrent que notre conception peut améliorer considérablement la précision et la vitesse de livraison de la prédiction d’impression au niveau de la demande.
Adresse du document : Pas encore publié
INPREM : un modèle de prédiction des soins de santé explicable et fiable

Entreprise : Tencent
résumé:
La construction de modèles prédictifs pour la médecine personnalisée basés sur des dossiers médicaux électroniques historiques est devenue un domaine de recherche actif. Grâce à ses puissantes capacités d’extraction de fonctionnalités, les méthodes d’apprentissage en profondeur ont obtenu de bons résultats dans de nombreuses tâches de prédiction clinique. Cependant, le manque d’interprétabilité et de crédibilité rend son application difficile dans les cas réels de prise de décision clinique.
Pour répondre à cette problématique, nous proposons dans cet article un modèle prédictif interprétable et fiable (INPREM) pour les soins de santé. Premièrement, l’INPREM est conçu comme un modèle linéaire interprétable pour parvenir à l’interprétabilité. Dans le même temps, des relations non linéaires sont codées dans les poids appris pour modéliser les dépendances entre et au sein de chaque visite.Cela nous permet d'obtenir la matrice de contribution des variables d'entrée,En tant que preuve des résultats prévus, cela aide les médecins à comprendre pourquoi le modèle fait une telle prédiction, rendant le modèle plus interprétable.Deuxièmement, pour la fiabilité, nous plaçons une porte aléatoire (suivant une distribution de Bernoulli pour activer ou désactiver) sur chaque poids du modèle, ainsi qu'une branche supplémentaire pour estimer le bruit des données. Le modèle utilise l’échantillonnage de Monte Carlo et une fonction objective qui prend en compte le bruit des données pour capturer l’incertitude de chaque prédiction. À son tour, l’incertitude capturée informe le médecin du niveau de confiance du modèle, rendant le modèle plus fiable. Nous démontrons empiriquement que l’INPREM proposé présente des avantages significatifs par rapport aux méthodes existantes.
Adresse du document :
https://dl.acm.org/doi/abs/10.1145/3394486.3403087
Les inscriptions pour la conférence en ligne KDD 2020 sont ouvertes
KDD 2020 est en cours et les inscriptions pour la conférence sont désormais ouvertes :
https://www.kdd.org/kdd2020/#!
L'ordre du jour complet a été annoncé. Les étudiants intéressés peuvent assister à la réunion à distance via Zoom. Les billets étudiants coûtent 50 $ US. L'une des séances les plus attendues, la cérémonie d'ouverture et la remise des prix, se dérouleront de 8h00 à 10h00, heure locale, le 25 août. Restez à l'écoute.
Pour le programme complet, veuillez consulter :
https://www.kdd.org/kdd2020/schedule
Sources :
https://www.kdd.org/kdd2020/accepted-papers#ads-papers
https://www.aminer.cn/conf/kdd2020/papers
-- sur--








