Command Palette
Search for a command to run...
Ensemble De Données arXiv De 1,1 To : 1,7 Million d'articles, Vous Pouvez Voir Votre Prochaine Vie
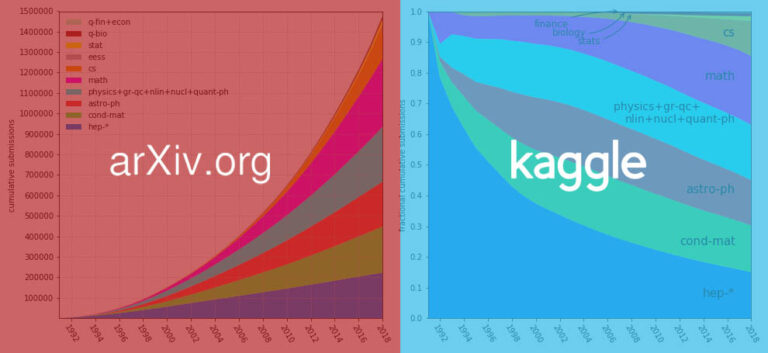
Récemment, arXiv a regroupé plus de 1,7 million d'articles dans un ensemble de données et l'a placé sur la plateforme Kaggle, ce qui facilite l'accès et le téléchargement des articles à l'avenir. L'ensemble de données fait actuellement environ 1,1 To et continuera de croître avec des mises à jour hebdomadaires.
Plus de 1,7 million de documents universitaires, d'une taille de 1,1 To, il s'agit d'un ensemble de données récemment ouvert par arXix sur Kaggle. Lorsque les internautes ont posé des questions à ce sujet, ils se sont exclamés : « C'est trop cool ! »
L'équipe de compilation de l'ensemble de données a déclaré qu'elle espérait inspirer les chercheurs concernés à explorer des technologies d'apprentissage automatique plus riches et à proposer davantage de découvertes et d'innovations.
Les ensembles de données ouverts facilitent les recherches sur papier
Depuis près de 30 ans, arXiv offre au public et aux communautés de recherche un accès libre à des articles scientifiques couvrant un large éventail de domaines.Des vastes branches de la physique aux nombreuses branches de l’informatique, en passant par toutes les disciplines telles que les mathématiques, les statistiques, le génie électrique, la biologie quantitative et l’économie.
Il existe de nombreux articles de recherche sur arXiv, et même si de nombreuses personnes en bénéficient,Cependant, il est souvent signalé qu'il présente des défauts tels qu'une navigation, une recherche et un tri peu pratiques.Certaines personnes ont même trouvé des conseils pour rechercher des articles sur arXiv et les ont partagés avec vous.
Ainsi, pour rendre arXiv plus accessible, l'Université Cornell propose désormais un ensemble de données arXiv gratuit et ouvert sur Kaggle.
L'ensemble de données contient 1,7 million d'articles universitaires, ainsi que des éléments liés aux articles (fonctionnalités), tels que le titre de l'article, l'auteur, la catégorie, le résumé et le PDF en texte intégral.
Eleonora Presani, directrice exécutive d'arXiv, a déclaré : « Disposer de l'intégralité du corpus arXiv sur Kaggle accroît considérablement le potentiel des articles arXiv. En fournissant l'ensemble des données sur Kaggle, nous ne nous contentons plus de permettre aux utilisateurs d'acquérir des connaissances en lisant ces articles.Plus important encore, les données et informations derrière arXiv devraient être mises à la disposition du public dans un format lisible par machine. "

Presani a ajouté : « ArXiv est plus qu'un simple dépôt d'articles ; c'est une plateforme de partage de connaissances. Cela nous oblige à innover dans la façon dont nous présentons et interprétons les connaissances disponibles. Les utilisateurs de Kaggle peuvent contribuer à repousser les limites de cette innovation, et cela devient pour nous un nouveau canal de collaboration avec la communauté. »
Regardez : Que contient l'ensemble de données arXiv ?
Les informations de base de l'ensemble de données arXiv sont les suivantes :
Ensemble de données arXiv
Publié par : Paul Ginsparg, Moonshot Factory, Jack Hidary
Quantité incluse :Plus de 1,7 million de documents universitaires
Format des données :json
Taille des données :1,1 To
Heure de sortie :Août 2020
Adresse de téléchargement :https://www.kaggle.com/Cornell-University/arxiv
Actuellement, l'ensemble de données arXiv fournit un fichier de métadonnées au format json, qui contient les entrées pertinentes pour chaque article, comme suit :
- id : adresse d'accès au papier, qui peut être utilisée pour accéder au papier ;
- soumissionnaire : soumissionnaire du document ;
- auteurs : auteurs de l’article ;
- titre : titre de l'article ;
- commentaires : autres informations telles que le nombre de pages et de figures dans l’article ;
- journal-ref : informations sur la revue dans laquelle l'article a été publié ;
- doi : identifiant d'objet numérique ;
- résumé : Résumé de l'article ;
- catégories : les catégories ou balises auxquelles appartient l’article dans arXiv ;
- versions : versions papier.
Vous pouvez facilement parcourir, filtrer et vérifier ces vastes documents.
De plus, les utilisateurs peuvent accéder à chaque article directement sur arXiv via les deux liens suivants :
- https://arxiv.org/abs/{id} : la page de l'article, y compris le résumé et d'autres liens ;
- https://arxiv.org/pdf/{id} : Page de téléchargement du document PDF.
L'accès en masse est également disponible : le PDF complet est disponible gratuitement sur le bucket gs://arxiv-dataset sur Google Cloud Storage, ou via l'API Google (documentation json et documentation xml).
Les fichiers PDF papier sont regroupés dans plusieurs fichiers .tar.gz dans le dossier tarpdfs, et l'ensemble de données a une taille d'environ 1,1 To. Les détails sont les suivants (voici les 1ère, 2ème et 3ème parties des champs en janvier 2010 (1001)) :
tarpdfs/arXiv_pdf_1001_001.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_001.tar.gz)tarpdfs/arXiv_pdf_1001_002.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_002.tar.gz)tarpdfs/arXiv_pdf_1001_003.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_003.tar.gz)
Les utilisateurs peuvent également télécharger des données sur leur machine locale à l’aide d’outils tels que gsutil.

Cependant, quels sont les scénarios d’utilisation spécifiques de cet ensemble de données ? De nombreux internautes ont déjà des idées, comme la modélisation de sujets et l’utilisation des données pour former GPT-3.
arXiv : un immense référentiel de documents universitaires
Les étudiants des milieux de la recherche scientifique et universitaire doivent être familiarisés avec arXiv.
Il s'agit d'un site Web qui rassemble des prépublications d'articles en physique, mathématiques, informatique et biologie. Il fournit non seulement une plateforme aux chercheurs scientifiques pour « réserver des idées », mais sert également d'immense bibliothèque de ressources permettant à chacun de rechercher et de lire des articles.
En octobre 2008, arXiv.org avait collecté plus de 500 000 prépublications ; à la fin de 2014, sa collection atteignait 1 million ;En octobre 2016, les soumissions sur arXiv dépassaient les 10 000 par mois.
arXiv a été créé par le physicien Paul Ginsbag en 1991. Son intention initiale était de collecter des prépublications d'articles de physique, et s'est ensuite étendue à d'autres domaines tels que l'astronomie et les mathématiques.
arXiv était à l'origine hébergé au Laboratoire national de Los Alamos (LANL), il s'appelait donc à ses débuts la « base de données de préimpression LANL ». Actuellement, arXiv est basé à l'Université Cornell et dispose de sites miroirs dans le monde entier. Le site a été renommé arXiv.org en 1999.
En termes simples, arXiv est un site Web utilisé pour « réserver une place ». Afin d'éviter que leurs idées ne soient plagiées par d'autres avant que l'article ne soit inclus, les chercheurs publieront leurs brouillons sur arXiv pour prouver leur originalité.
Références :
https://www.kaggle.com/Cornell-University/arxiv?select=arxiv-metadata-oai-snapshot.json
https://zh.wikipedia.org/wiki/ArXiv
-- sur--








