Command Palette
Search for a command to run...
L'examen Final n'est Pas Encore Là, Mais l'algorithme Dit Que Je Vais Certainement Échouer En Physique
La physique universitaire est un cours obligatoire de base pour les étudiants en sciences et en ingénierie, mais comme elle est assez difficile, de nombreux étudiants en sont intimidés. Les chercheurs ont proposé d’utiliser des algorithmes d’IA pour prédire quels élèves risquent d’échouer aux cours de physique, afin que les enseignants puissent mieux fournir des conseils pédagogiques et ajuster l’allocation des ressources pédagogiques.
Il faut dire que les capacités prédictives des algorithmes deviennent de plus en plus puissantes, qu’il s’agisse de prédire si un couple va se disputer ou de prédire quand des tremblements de terre, des inondations, etc. se produiront.
Les algorithmes peuvent désormais même prédire si vous allez échouer à votre cours de physique.
Il s’agit d’une étude récente publiée sur arxiv.org par des chercheurs de l’Université de Virginie-Occidentale et du California Institute of Technology.

Ils ont publié un article intéressant :« Utiliser l'apprentissage automatique pour identifier les élèves les plus à risque dans les cours de physique »
L’article indique que grâce à des algorithmes d’apprentissage automatique, les notes de fin d’études des étudiants dans les cours de physique de base peuvent être évaluées. Le modèle prédictif classe les étudiants dans les catégories A, B, C, D, F et W (retrait).
Remarque : Les notes et les pourcentages adoptés par la plupart des collèges et universités aux États-Unis sont à peu près les suivants : A : 90+ ; B : 80+; C: 70+; D: 60+; F : Échec ; W : Retrait (abréviation de Retrait).
Résultats prévus : sonnez l'alarme, vous pouvez encore l'économiser
Vous souvenez-vous de la panique ressentie lorsque vous étiez dominé par la physique universitaire ?
Pour de nombreux étudiants en sciences et en ingénierie, la physique universitaire est aussi difficile que les mathématiques avancées et constitue l’une des matières les plus intimidantes.
Une étude étrangère montre que parmi les étudiants qui se sont spécialisés dans l'ingénierie et les sciences (collectivement appelés STEM) mais qui ont finalement changé de spécialisation ou n'ont pas réussi à obtenir un diplôme,Une petite moitié d’entre eux l’ont fait parce que leurs matières principales, comme la physique et les mathématiques, étaient trop difficiles.

Le taux d’attrition des étudiants en STEM, en particulier ceux des disciplines de base, augmente d’année en année. Dans le même temps, la demande de la société à leur égard reste élevée, ce qui entraîne un manque important de talents.
Par conséquent, des chercheurs de l’Université de Virginie-Occidentale et de l’Institut de technologie de Californie ont proposé queUtilisons des algorithmes d’IA pour sauver ces étudiants.
Ils pensent que les algorithmes d’apprentissage automatique peuvent être utilisés pour identifier les étudiants qui risquent d’échouer à un cours. De cette façon, les enseignants peuvent fournir des conseils ciblés en fonction des résultats prévus, améliorant ainsi le taux de réussite des étudiants et comprenant leur maîtrise des connaissances en temps opportun.
Algorithme : Se référer aux performances passées pour prédire les résultats futurs
Extraction d'échantillons
Les chercheurs ont utilisé trois échantillons provenant de deux universités pour former un algorithme d’IA afin de prédire les performances des étudiants.
Les données d'échantillon comprennent :Résultats des étudiants à l'ACT (American College Entrance Examination), moyenne générale à l'université et données collectées dans les cours de physique (telles que les notes des devoirs et les résultats des tests).
Parmi eux, les échantillons 1 et 2 provenaient d’étudiants spécialisés en sciences physiques et en ingénierie dans une université de l’est des États-Unis.
Exemple 1 :Tous les étudiants ayant terminé le cours de physique 1 au collège de 2000 à 2018 ont été inclus, avec un échantillon de 7 184 personnes.
Exemple 2 : Les données couvrent les semestres de l’automne 2016 au printemps 2019, avec un échantillon de 1 683 étudiants. L'échantillon comprend des données sur les performances en classe, telles que le nombre moyen de réponses, les notes moyennes aux devoirs et les notes aux examens semestriels.
Exemple 3 :Les données proviennent d'un cours d'introduction à la mécanique pour toute l'année universitaire 2017. L'échantillon 3 a été collecté dans une autre université, située dans l'ouest des États-Unis.
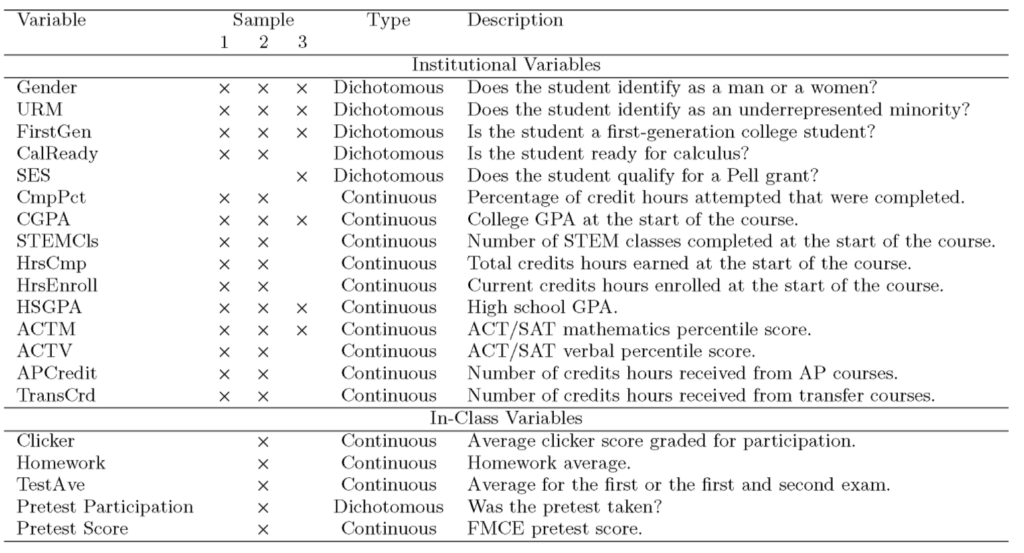
variable
Les variables utilisées dans cette étude proviennent toutes de l’université et de la classe. Parallèlement, certaines informations démographiques telles que le sexe et l’origine ethnique sont également incluses.
Prédiction de l'algorithme de forêt aléatoire
Dans l'étude,Un algorithme d’apprentissage automatique de forêt aléatoire a été utilisé pour prédire les notes finales des étudiants dans un cours d’introduction à la physique.L'algorithme divisera finalement les étudiants en ceux qui obtiennent A, B ou C (classés comme étudiants ABC) et ceux qui obtiennent D, F ou W (classés comme étudiants potentiellement en échec DFW).
Pour comprendre les performances de l’algorithme, ils ont divisé l’ensemble de données en ensembles de données de test et d’entraînement. L'ensemble de données de formation est utilisé pour développer le modèle de classification afin de former le classificateur.
L'ensemble de données de test est utilisé pour caractériser les performances du modèle.
Une fois que le modèle de classification a prédit les résultats des tests pour chaque étudiant dans l’ensemble de données de test, les prédictions sont comparées aux résultats réels.
Résultat : Gênant, précision 57 %
Après avoir ajusté et vérifié le modèle, les chercheurs sont arrivés à un résultat de prédiction, mais le taux de précision n'est pas très optimiste...
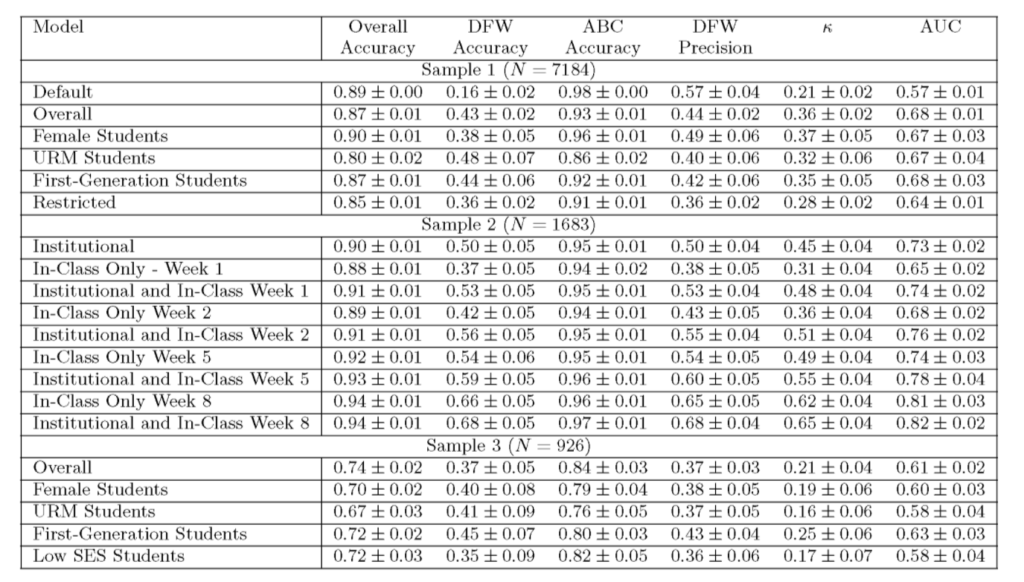
Ils ont souligné que dans les résultats de prédiction pour l’ensemble de l’échantillon,Pour les échantillons comportant davantage d’étudiantes et d’étudiantes issues de minorités, la précision du DFW est plus faible.Ils soulignent que cela nécessiterait des ajustements de modèle en fonction des données démographiques.
Sur le premier échantillonL'algorithme formé prédit uniquement les « étudiants de type DFW » avec une précision de 16 %.Les chercheurs ont analysé que cela pourrait être dû à la faible proportion d’étudiants avec des scores DFW dans l’ensemble de formation (12 %).
Dans l'échantillon 1,La meilleure performance du modèle n'était que 57%, ce qui est à peine mieux que le hasard.
Les résultats sont peu précis et le modèle est controversé
Face à ce résultat, ils estiment que ce type de modèle de classification d’apprentissage automatique peut être un outil puissant pour les enseignants et les étudiants qui ont des difficultés à apprendre.Elle peut mieux guider l’intervention éducative et l’allocation des ressources éducatives.
Internaute : Mais... 57% n'est-il pas un peu bas ?
Cependant, certains critiques estiment queUne technologie comme celle-ci pourrait conduire à des prédictions biaisées ou trompeuses qui pourraient nuire aux étudiants.
Des études ont constamment montré que même lorsqu’elle est formée sur de grands corpus, l’intelligence artificielle peut encore avoir des biais lorsqu’il s’agit de prédire des résultats complexes.
Auparavant, l'outil de recrutement interne d'Amazon basé sur l'IA avait été désactivé car il présentait des préjugés à l'encontre des femmes.
Par conséquent, les gens craignent également que ce type d’algorithme de prédiction des notes non seulement ne parvienne pas à améliorer le taux de rétention des étudiants en STEM, mais qu’il exacerbe les inégalités.
Bien sûr, tous les résultats ne sont que des prédictions. En ce qui concerne les examens, 30 % sont déterminés par le destin, 70 % dépendent du travail acharné et les 90 % restants dépendent de l'humeur de l'enseignant.
-- sur--

