Command Palette
Search for a command to run...
PyTorch 1.5 Est Sorti, TorchServe En Collaboration Avec AWS

Récemment, PyTorch a publié une mise à jour vers la version 1.5. En tant que framework d'apprentissage automatique de plus en plus populaire, PyTorch a également apporté des mises à niveau fonctionnelles majeures cette fois-ci. De plus, Facebook et AWS ont collaboré pour lancer deux importantes bibliothèques PyTorch.
Comme PyTorch est de plus en plus utilisé dans les environnements de production, fournir à la communauté de meilleurs outils et plates-formes pour faire évoluer efficacement la formation et déployer des modèles est devenu une priorité absolue pour PyTorch.
Récemment, PyTorch 1.5 est sorti.Les principales bibliothèques torchvision, torchtext et torchaudio ont été mises à niveau et des fonctionnalités telles que la conversion de modèles de l'API Python vers l'API C++ ont été introduites.

en plus,Facebook a également collaboré avec Amazon pour lancer deux outils majeurs : le framework de diffusion de modèles TorchServe et le contrôleur Kubernetes TorchElastic.
TorchServe vise à fournir un chemin propre, compatible et de qualité industrielle pour le déploiement à grande échelle de l'inférence de modèle PyTorch.
Le contrôleur TorchElastic Kubernetes permet aux développeurs d'utiliser rapidement des clusters Kubernetes pour créer des tâches de formation distribuées tolérantes aux pannes dans PyTorch.
Il semble que ce soit une initiative de Facebook et d’Amazon visant à déclarer la guerre à TensorFlow dans le cadre du modèle d’IA de performance à grande échelle.
TorchServe : pour les tâches d'inférence
Le déploiement de modèles d’apprentissage automatique pour l’inférence à grande échelle n’est pas facile. Les développeurs doivent collecter et empaqueter les artefacts de modèle, créer une pile de service sécurisée, installer et configurer des bibliothèques logicielles pour la prédiction, créer et utiliser des API et des points de terminaison, générer des journaux et des mesures pour la surveillance et gérer plusieurs versions de modèle sur potentiellement plusieurs serveurs.
Chacune de ces tâches prend beaucoup de temps et peut ralentir le déploiement du modèle de plusieurs semaines, voire de plusieurs mois. De plus, l’optimisation des services pour les applications en ligne à faible latence est indispensable.
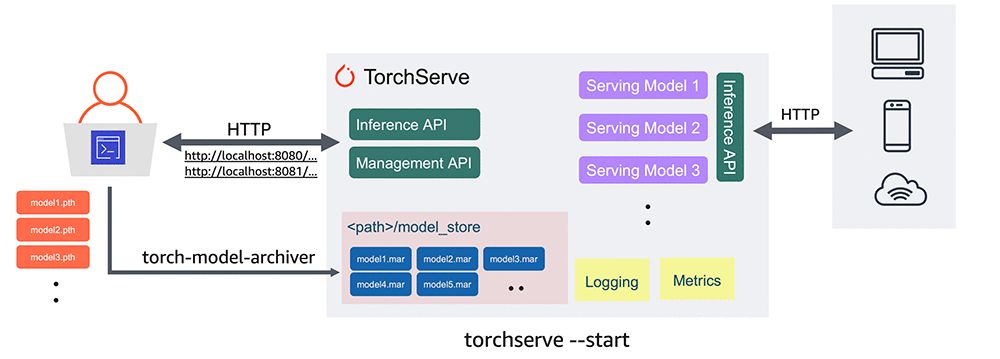
Auparavant, les développeurs utilisant PyTorch ne disposaient pas d’une méthode officiellement prise en charge pour déployer les modèles PyTorch. La sortie du framework de service de modèle de production TorchServe va changer cette situation, facilitant la mise en production des modèles.
Dans l'exemple suivant, nous montrerons comment extraire un modèle formé de Torchvision et le déployer à l'aide de TorchServe.
#Download a trained PyTorch modelwget https://download.pytorch.org/models/densenet161-8d451a50.pth#Package model for TorchServe and create model archive .mar filetorch-model-archiver \--model-name densenet161 \--version 1.0 \--model-file examples/image_classifier/densenet_161/model.py \--serialized-file densenet161–8d451a50.pth \--extra-files examples/image_classifier/index_to_name.json \--handler image_classifiermkdir model_storemv densenet161.mar model_store/#Start TorchServe model server and register DenseNet161 modeltorchserve — start — model-store model_store — models densenet161=densenet161.mar
Une version bêta de TorchServe est désormais disponible.Les fonctionnalités incluent :
- API native: Prend en charge l'API d'inférence pour la prédiction et l'API de gestion pour la gestion des serveurs de modèles.
- Déploiement sécurisé: Inclut la prise en charge HTTPS pour les déploiements sécurisés.
- Puissantes capacités de gestion de modèles: Permet la configuration complète des modèles, des versions et des travailleurs individuels via l'interface de ligne de commande, les fichiers de configuration ou l'API d'exécution.
- Archives de modèles: Fournit des outils pour effectuer « l'archivage de modèles », un processus d'empaquetage d'un modèle, de paramètres et de fichiers de support dans un seul artefact persistant. À l'aide d'une interface de ligne de commande simple, vous pouvez empaqueter et exporter un seul fichier « .mar » contenant tout ce dont vous avez besoin pour servir un modèle PyTorch. Le fichier .mar peut être partagé et réutilisé.
- Gestionnaires de modèles intégrés: Prend en charge les gestionnaires de modèles couvrant les cas d'utilisation les plus courants tels que la classification d'images, la détection d'objets, la classification de texte et la segmentation d'images. TorchServe prend également en charge les gestionnaires personnalisés.
- Journalisation et métriques: Prend en charge une journalisation robuste et des mesures en temps réel pour surveiller les services d'inférence et les points de terminaison, les performances, l'utilisation des ressources et les erreurs. Il est également possible de générer des journaux personnalisés et de définir des métriques personnalisées.
- Gestion des modèles: Prend en charge la gestion simultanée de plusieurs modèles ou de plusieurs versions du même modèle. Vous pouvez utiliser le contrôle de version du modèle pour revenir à une version antérieure ou pour acheminer le trafic vers différentes versions pour les tests A/B.
- Images prédéfinies:Une fois prêt, vous pouvez déployer le Dockerfile et l'image Docker de Torcherve dans des environnements basés sur CPU et GPU NVIDIA. Les derniers Dockerfiles et images peuvent être trouvés ici.
Les instructions d'installation, les tutoriels et la documentation sont également disponibles sur pytorch.org/serve.
TorchElastic : contrôleur K8S intégré
À mesure que les modèles actuels de formation à l’apprentissage automatique deviennent de plus en plus grands, tels que RoBERTa et TuringNLG, la nécessité de les étendre à des clusters distribués devient de plus en plus importante. Pour répondre à ce besoin, des instances préemptives (telles que les instances Spot Amazon EC2) sont souvent utilisées.
Mais ces instances préemptives elles-mêmes sont imprévisibles, c'est donc là qu'intervient le deuxième outil, TorchElastic.
L'intégration de Kubernetes et TorchElastic permet aux développeurs PyTorch de former des modèles d'apprentissage automatique sur un cluster de nœuds de calcul.Ces nœuds peuvent être modifiés de manière dynamique sans perturber le processus de formation du modèle.
Même si un nœud tombe en panne, la tolérance aux pannes intégrée de TorchElastic vous permet de suspendre la formation au niveau du nœud et de reprendre la formation une fois que le nœud redevient sain.
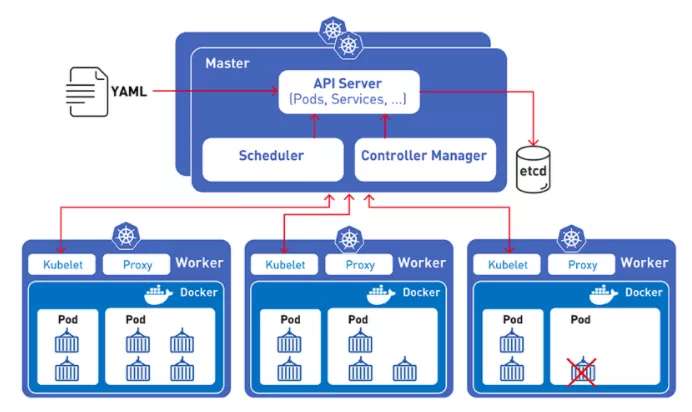
De plus, en utilisant le contrôleur Kubernetes avec TorchElastic, vous pouvez exécuter la tâche critique de formation distribuée sur un cluster avec des nœuds remplacés en cas de problèmes de matériel ou de recyclage de nœuds.
Les tâches de formation peuvent être lancées à l'aide d'une partie des ressources demandées et peuvent évoluer de manière dynamique à mesure que les ressources deviennent disponibles, sans avoir à arrêter ou redémarrer.
Pour profiter de ces fonctionnalités, les utilisateurs spécifient simplement les paramètres de formation dans une définition de tâche simple, et le package Kubernetes-TorchElastic gère le cycle de vie de la tâche.
Voici un exemple simple de configuration TorchElastic pour un travail de formation Imagenet :
apiVersion: elastic.pytorch.org/v1alpha1kind: ElasticJobmetadata:name: imagenetnamespace: elastic-jobspec:rdzvEndpoint: $ETCD_SERVER_ENDPOINTminReplicas: 1maxReplicas: 2replicaSpecs:Worker:replicas: 2restartPolicy: ExitCodetemplate:apiVersion: v1kind: Podspec:containers:- name: elasticjob-workerimage: torchelastic/examples:0.2.0rc1imagePullPolicy: Alwaysargs:- "--nproc_per_node=1"- "/workspace/examples/imagenet/main.py"- "--arch=resnet18"- "--epochs=20"- "--batch-size=32"
Microsoft et Google, vous paniquez ?
La coopération entre les deux sociétés pour lancer la nouvelle bibliothèque PyTorch peut avoir une signification plus profonde, car la routine « ne pas jouer avec vous » n'est pas la première fois qu'elle apparaît dans l'histoire du développement de modèles de framework.
En décembre 2017, AWS, Facebook et Microsoft ont annoncé qu'ils développeraient conjointement ONNX pour les environnements de production.Il s’agit de contrer le monopole de TensorFlow de Google sur l’utilisation industrielle.
Par la suite, les principaux frameworks d’apprentissage en profondeur tels qu’Apache MXNet, Caffe2 et PyTorch ont tous mis en œuvre divers degrés de support pour ONNX, ce qui facilite la migration d’algorithmes et de modèles entre différents frameworks.

Cependant, la vision d’ONNX de connecter le monde universitaire et l’industrie n’a pas réellement répondu aux attentes initiales. Chaque framework utilise toujours son propre système de service, et seuls MXNet et PyTorch ont pénétré dans ONNX.
Aujourd'hui,PyTorch a lancé son propre système de services, et ONNX a presque perdu le sens de son existence (MXNet a déclaré qu'il était perdu).
D'autre part, PyTorch est constamment mis à niveau et mis à jour, et la compatibilité et la facilité d'utilisation du framework s'améliorent.Il se rapproche et dépasse même son plus grand rival, TensorFlow.
Bien que Google dispose de ses propres services et frameworks cloud, la combinaison des ressources cloud d'AWS et du système de framework de Facebook rendra difficile pour Google de faire face à cette puissante combinaison.
Microsoft a été expulsé du groupe de discussion par deux membres de l'ancien trio ONNX. Quels sont les plans de Microsoft pour la prochaine étape ?
-- sur--








