Command Palette
Search for a command to run...
Ce Groupe d'ingénieurs a Fait Progresser La PNL Chinoise À Grands Pas Pendant Leur Temps libre.

Quelqu'un a dit que si vous avez étudié le PNL (traitement du langage naturel), vous saurez à quel point le PNL chinois est difficile.
Bien que les deux appartiennent à la PNL, il existe de grandes différences d'analyse et de traitement entre l'anglais et le chinois en raison d'habitudes linguistiques différentes, et les difficultés et les défis sont également différents.

De plus, certains des modèles actuellement populaires sont principalement développés pour l’anglais. Associées aux habitudes d’utilisation uniques du chinois, de nombreuses tâches (comme la segmentation des mots) sont très difficiles, ce qui entraîne des progrès très lents dans le domaine du PNL chinois.
Mais ce genre de problème pourrait bientôt changer, car depuis l'année dernière, de nombreux excellents projets open source ont émergé, ce qui a grandement favorisé le développement du domaine chinois du PNL.
Modèle : ALBERT pré-entraîné chinois
En 2018, Google a lancé le modèle de langage BERT, Bidirectional Encoder Representations from Transformers. En raison de ses performances extrêmement puissantes, il a balayé les charts de nombreuses normes PNL dès sa sortie et a été immédiatement salué comme un chef-d'œuvre.
Mais l’un des inconvénients de BERT est qu’il est trop grand. BERT-large possède 300 millions de paramètres, ce qui le rend très difficile à former. En 2019, Google AI a lancé le modèle léger ALBERT (A Little BERT), qui possède des paramètres 18 fois plus petits que le modèle BERT, mais ses performances sont meilleures.
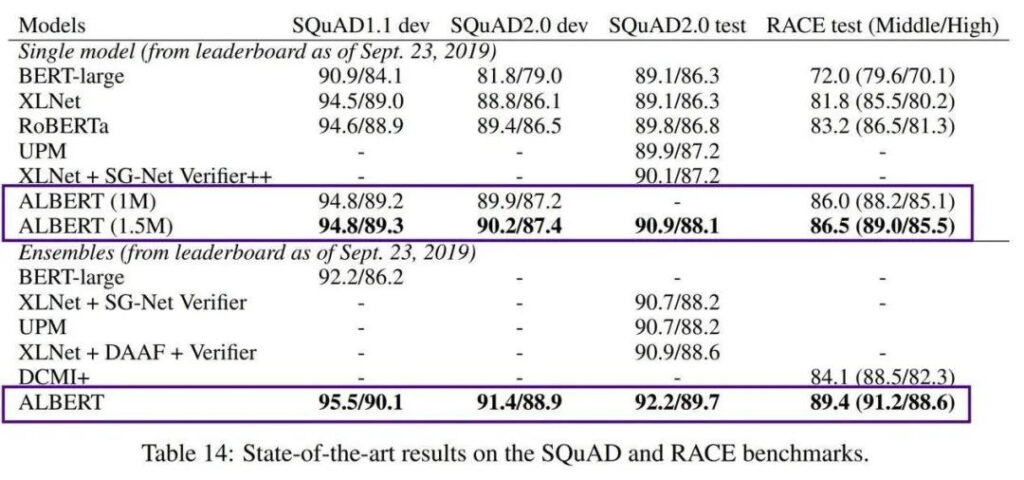
Bien qu'il résolve le problème du coût élevé de la formation et du grand nombre de paramètres des modèles pré-entraînés, AlBERT ne cible toujours que les contextes anglais, ce qui fait que les ingénieurs qui se concentrent sur le développement chinois se sentent un peu impuissants.
Afin de rendre ce modèle utilisable dans le contexte chinois et de bénéficier à davantage de développeurs, l'équipe d'ingénieurs de données Xu Liang a ouvert le premier modèle ALBERT pré-entraîné chinois en octobre 2019.
Galerie de projets
https://github.com/brightmart/albert_zh
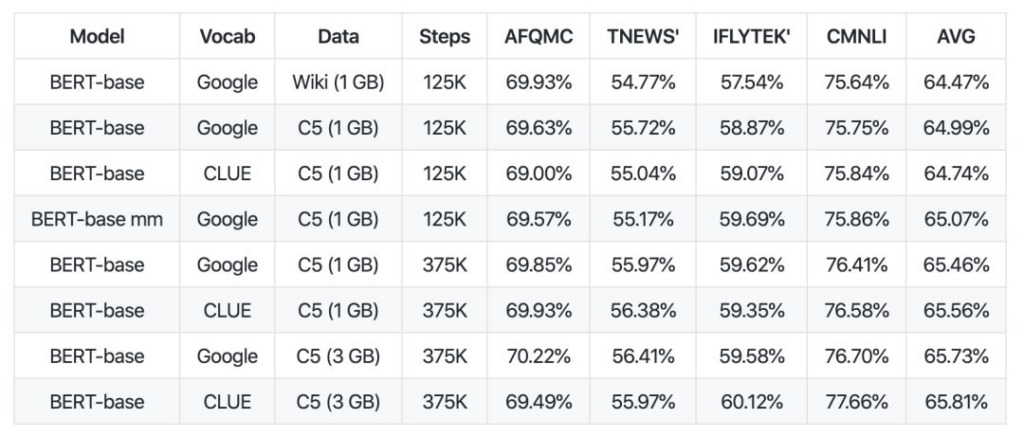
Ce modèle ALBERT pré-entraîné chinois (appelé albert_zh) est formé sur un corpus chinois massif. Le contenu de la formation provient de plusieurs encyclopédies, actualités et communautés interactives, dont 30 Go de corpus chinois et plus de 100 milliards de caractères chinois.
D'après la comparaison des données, la longueur de la séquence de pré-formation d'albert_zh est définie sur 512, la taille du lot est de 4096 et la formation génère 350 millions de données de formation. Un autre modèle de pré-formation puissant, roberta_zh, génère 250 millions de données de formation avec une longueur de séquence de 256.
La pré-formation albert_zh génère plus de données de formation et utilise des séquences plus longues. On s'attend à ce qu'albert_zh ait de meilleures performances que roberta_zh et puisse mieux gérer des textes plus longs.
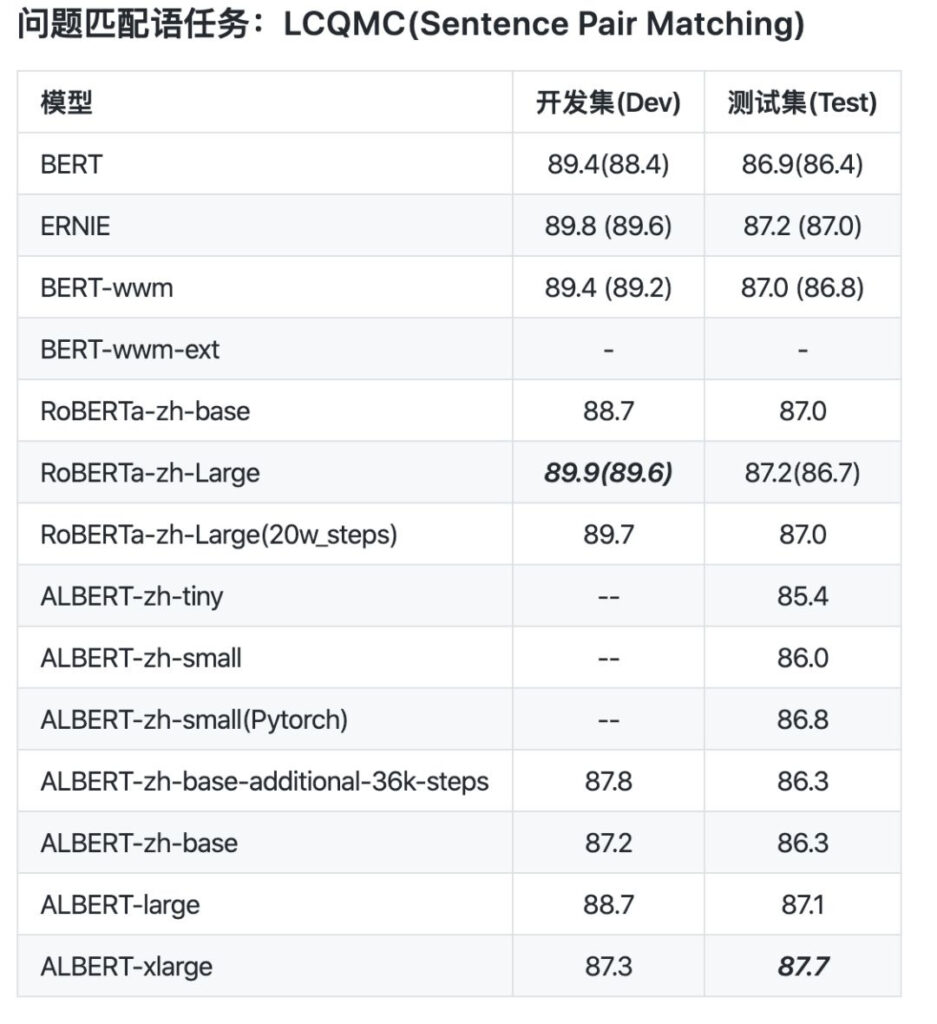
De plus, albert_zh a formé une série de modèles ALBERT avec différentes tailles de paramètres, de minuscule à très grand, ce qui a grandement favorisé la popularité d'ALBERT dans le domaine du PNL chinois.
Il convient de mentionner qu'en janvier 2020, Google AI a publié ALBERT V2, puis a lentement lancé la version chinoise d'ALBERT de Google.
Référence : ChineseGLUE pour Chinese GLUE
Une fois que nous avons des modèles, comment pouvons-nous juger s’ils sont bons ou mauvais ? Cela nécessite un benchmark de test suffisamment bon. L'année dernière également, le benchmark ChineseGLUE pour le NLP chinois a été rendu open source.
ChineseGLUE est basé sur le test de référence GLUE, reconnu dans le secteur, qui est une collection de neuf tâches de compréhension de la langue anglaise. Son objectif est de promouvoir la recherche de systèmes de compréhension du langage naturel généraux et robustes.
Auparavant, il n’existait pas de version chinoise correspondant à GLUE, et certains modèles pré-entraînés ne pouvaient pas être jugés lors de tests publics sur différentes tâches, ce qui entraînait un décalage dans le développement et l’application de la PNL dans le domaine chinois, et même un retard dans l’application technologique.
Face à cette situation, le Dr Zhenzhong Lan, premier auteur d'AlBERT, Xu Liang, développeur d'ablbert_zh, et plus de 20 autres ingénieurs ont lancé conjointement un benchmark pour le PNL chinois : ChineseGLUE.
Galerie de projets
https://github.com/chineseGLUE/chineseGLUE
L’émergence de ChineseGLUE a permis d’inclure le chinois comme indicateur pour l’évaluation de nouveaux modèles, formant ainsi un système d’évaluation complet pour tester les modèles chinois pré-entraînés.
Ce puissant benchmark de test comprend les aspects suivants :
1) Un test de référence pour les tâches chinoises composé de plusieurs phrases ou paires de phrases, couvrant plusieurs tâches linguistiques à différents niveaux.
2) Fournir une liste de classement des évaluations de performance, qui sera mise à jour régulièrement pour fournir une base pour la sélection des modèles.
3) Une collection de modèles de référence, comprenant le code de départ, les modèles pré-entraînés et les repères pour les tâches ChineseGLUE, qui sont disponibles dans des frameworks tels que TensorFlow, PyTorch et Keras.
4) Disposer d'un vaste corpus original pour la recherche de pré-formation ou de modélisation du langage, qui est d'environ 10G (2019), et qui devrait être étendu à un corpus original suffisant (par exemple 100G) d'ici la fin de 2020.
Le lancement et l’amélioration continue de ChineseGLUE devraient voir la naissance de modèles NLP chinois plus puissants, tout comme GLUE a vu l’émergence de BERT.
Fin décembre 2019, le projet a été migré vers un projet plus complet et plus supporté techniquement : CLUEbenchmark/CLUE.
Galerie de projets
https://github.com/CLUEbenchmark/CLUE
Données : L'ensemble de données le plus complet et le plus grand corpus de l'histoire
Avec les modèles pré-entraînés et les tests de référence, un autre lien important est constitué par les ressources de données telles que les ensembles de données et les corpus.
Cela a conduit à une organisation plus complète, CLUE, qui est l'abréviation de GLUE en chinois. Il s'agit d'une organisation open source qui fournit des critères d'évaluation pour la compréhension de la langue chinoise. Leurs domaines d’intérêt comprennent : les tâches et les ensembles de données, les benchmarks, les modèles chinois pré-entraînés, les corpus et les publications de classement.
Il y a quelque temps, CLUE a publié l'ensemble de données NLP chinois le plus grand et le plus complet, couvrant 142 ensembles de données dans 10 catégories, CLUEDatasetSearch.

Galerie de projets
https://github.com/CLUEbenchmark/CLUEDatasetSearch
Son contenu comprend toutes les principales directions de recherche actuelles telles que le NER, l'assurance qualité, l'analyse des sentiments, la classification de textes, l'attribution de textes, le résumé de textes, la traduction automatique, les graphiques de connaissances, les corpus et la compréhension de lecture.
Tapez simplement des mots-clés ou des informations telles que des champs associés sur la page du site Web et vous pourrez rechercher les ressources correspondantes. Chaque ensemble de données fournit des informations telles que le nom, l'heure de mise à jour, le fournisseur, la description, les mots-clés, la catégorie et l'adresse papier.
Récemment, l'organisation CLUE a ouvert 100 Go de corpus chinois et une collection de modèles chinois pré-entraînés de haute qualité, et a soumis un article à arViv.

En termes de corpus, CLUE a ouvert le code source de CLUECorpus2020 : corpus de pré-formation à grande échelle pour le chinois 100 Go de corpus de pré-formation chinois.
Ces contenus sont obtenus après nettoyage du corpus de la partie chinoise du jeu de données Common Crawl.
Ils peuvent être utilisés directement pour des tâches de pré-formation, de modèle de langage ou de génération de langage, ou pour publier de petits vocabulaires spécifiquement pour les tâches de PNL chinoises.
Galerie de projets
https://github.com/CLUEbenchmark/CLUECorpus2020
En termes de collection de modèles, CLUEPretrainedModels a été publié : une collection de modèles chinois pré-entraînés de haute qualité - les grands modèles les plus avancés, les petits modèles les plus rapides et les modèles spécifiques à la similarité.
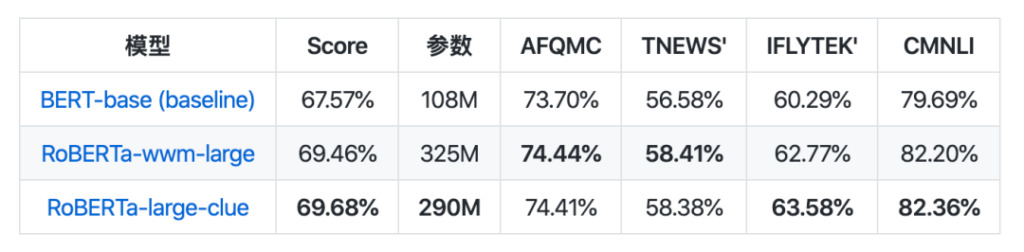
Le grand modèle obtient les mêmes résultats que le meilleur modèle NLP chinois actuel, et surpasse même certaines tâches. Le petit modèle est environ 8 fois plus rapide que Bert-base. Le modèle de similarité sémantique est utilisé pour traiter les problèmes de similarité sémantique ou de paires de phrases, et est susceptible d'être meilleur que l'utilisation directe d'un modèle pré-entraîné.
Galerie de projets
https://github.com/CLUEbenchmark/CLUEPretrainedModels
La libération de ces ressources est, dans une certaine mesure, comme un carburant qui alimente le processus de développement, et des ressources suffisantes peuvent ouvrir la voie à un développement rapide de l’industrie chinoise du PNL.
Ils rendent la PNL chinoise facile
D’un point de vue linguistique, le chinois et l’anglais sont les deux langues qui comptent le plus grand nombre d’utilisateurs et la plus grande influence au monde. Cependant, en raison de leurs caractéristiques linguistiques différentes, ils sont également confrontés à des problèmes différents dans la recherche dans le domaine de la PNL.
Bien que le développement du PNL chinois soit en effet plus difficile et en retard par rapport à la recherche sur l'anglais, qui peut être mieux compris par les machines, c'est précisément grâce aux ingénieurs mentionnés dans l'article qui sont prêts à promouvoir le développement du PNL chinois et à continuer d'explorer et de partager leurs résultats que ces technologies peuvent être mieux itérées.
Merci à leurs efforts et à leurs contributions à tant de projets de grande qualité ! Dans le même temps, nous espérons que davantage de personnes pourront participer et promouvoir conjointement le développement de la PNL chinoise.
-- sur--








