Command Palette
Search for a command to run...
Ensemble De Données De Structure Cristalline LLM4Mat-Bench
Date
URL de publication
URL du document
LLM4Mat-Bench est un ensemble de données d'évaluation de modèles de langage multimodaux pour la prédiction des propriétés des matériaux créé conjointement par l'Université de Princeton, l'Université de Toronto et d'autres institutions. Les résultats de l'article connexe sont «LLM4Mat-Bench : Analyse comparative de grands modèles linguistiques pour la prédiction des propriétés des matériaux« » vise à évaluer les performances des grands modèles de langage (LLM) dans les tâches de prédiction et de découverte de matériaux. L'ensemble de données contient environ 1,97 million d'échantillons de structures cristallines provenant de 10 bases de données publiques sur les matériaux, couvrant 45 propriétés physiques et chimiques différentes. Il s'agit de la plus grande référence à ce jour pour évaluer les performances des grands modèles de langage (LLM) pour la prédiction des propriétés des matériaux.
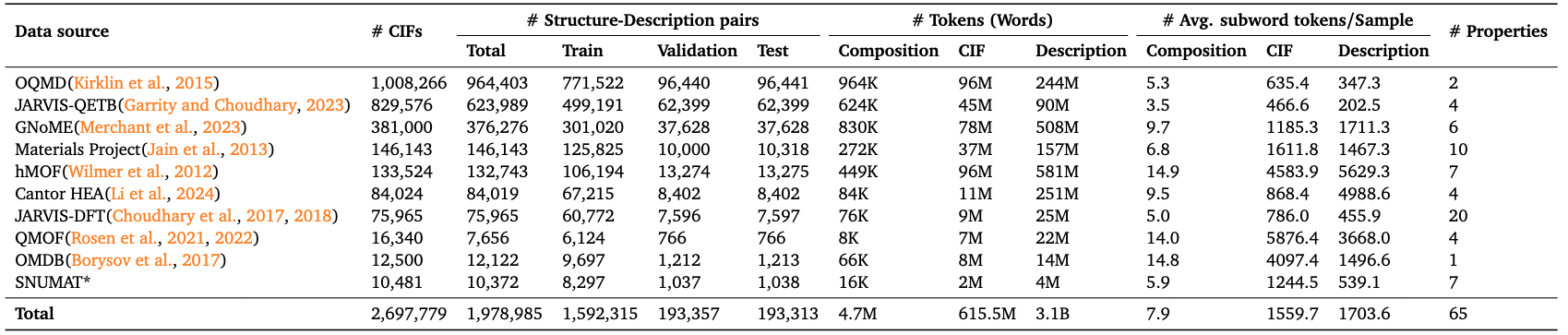
Quantité totale de données :
- Mode de composition de cristal (Composition) : environ 4,7 M de jetons
- Mode de structure cristalline (CIF) : environ 615,5 M de jetons
- Descriptions textuelles : environ 3,1 milliards de jetons Le processus de création de cet ensemble de données comprend la collecte de fichiers CIF originaux et de propriétés matérielles à partir de plusieurs bases de données de matériaux grand public, et la génération automatique de descriptions de langage structurel basées sur la structure cristalline, formant ainsi un échantillon de données de structure multimodal et unifié. Chaque enregistrement d'échantillon contient l'ID du matériau correspondant, la formule chimique, les valeurs de propriété (telles que la bande interdite, l'énergie de formation, la densité, le module d'élasticité, etc.) et d'autres informations. L'objectif principal de LLM4Mat-Bench est de promouvoir l'intégration croisée de la science des matériaux et du traitement du langage naturel, et de promouvoir la recherche et le développement d'applications dans les domaines de l'évaluation de modèles spécifiques aux tâches, de la prédiction des propriétés et du réglage fin des instructions. Ses caractéristiques multi-sources, multimodales et à grande échelle en font une référence importante dans la recherche de modèles de langage matériel.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.