Command Palette
Search for a command to run...
Ensemble De Données Multimodales MINT-1T (paire Texte-image)
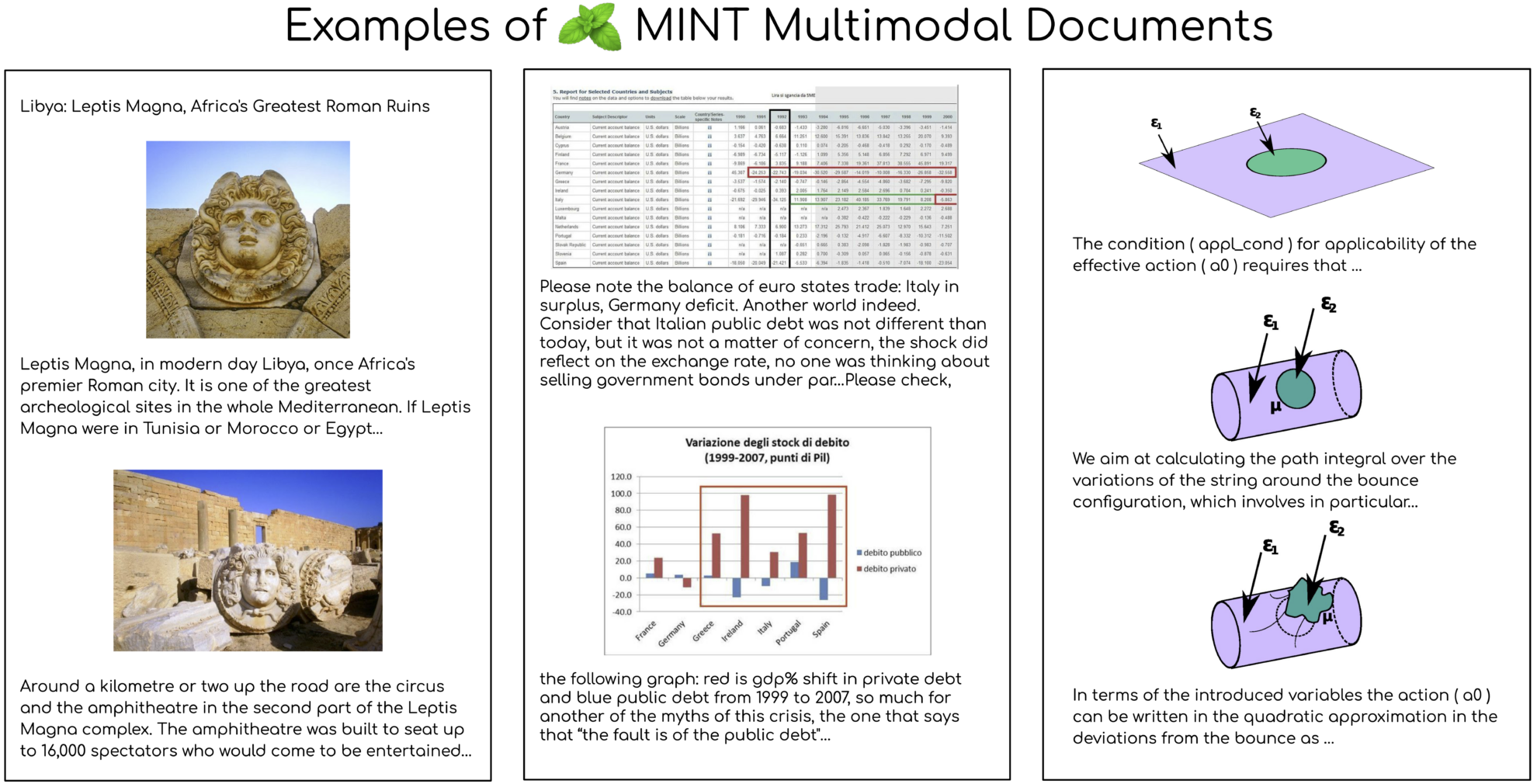
L'ensemble de données MINT-1T est un ensemble de données multimodal ouvert conjointement par Salesforce AI et plusieurs institutions en 2024. Il a connu une expansion significative en termes d'échelle, atteignant mille milliards de balises de texte et 3,4 milliards d'images, soit 10 fois la taille du précédent plus grand ensemble de données open source. Les résultats pertinents de l'article sont «MINT-1T : Multiplier par 10 les données multimodales open source : un ensemble de données multimodales avec mille milliards de jetonsLa construction de cet ensemble de données respecte les principes fondamentaux d'échelle et de diversité. Il comprend non seulement des documents HTML, mais aussi des documents PDF et des articles ArXiv. Cette diversité améliore considérablement la couverture des documents scientifiques. Les sources de données de MINT-1T sont diverses, incluant, sans s'y limiter, des pages web, des articles universitaires et des documents qui n'ont pas encore été pleinement exploités dans les ensembles de données multimodaux.
En termes d'expériences de modèles, le modèle multimodal XGen-MM pré-entraîné sur MINT-1T fonctionne bien dans les tests de description d'images et de réponses aux questions visuelles, surpassant le précédent ensemble de données OBELICS. Grâce à l'analyse, MINT-1T a obtenu des améliorations significatives en termes d'échelle, de diversité des sources de données et de qualité, en particulier dans les documents PDF et ArXiv, qui ont une longueur moyenne nettement plus longue et une densité d'image plus élevée. De plus, les résultats de la modélisation thématique des documents via le modèle LDA montrent que le sous-ensemble HTML de MINT-1T présente une gamme plus large de couverture de domaine, tandis que le sous-ensemble PDF est principalement concentré dans les domaines de la science et de la technologie.
MINT-1T démontre d'excellentes performances sur de multiples tâches, notamment dans les domaines scientifiques et technologiques, grâce à la popularité de ces domaines dans les documents ArXiv et PDF. Les performances d’apprentissage contextuel des modèles sont évaluées en utilisant différents nombres d’exemples. Les modèles formés sur MINT-1T surpassent le modèle de base OBELICS sur tous les nombres d'exemples. La sortie de MINT-1T fournit non seulement aux chercheurs et aux développeurs un vaste ensemble de données multimodales, mais offre également de nouveaux défis et opportunités pour la formation et l'évaluation de modèles multimodaux.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.