Command Palette
Search for a command to run...
Corpus Médical Multilingue À Grande Échelle MMedC
Date
Taille
Organisation
URL de publication
URL du document
Licence
CC BY-NC-SA 3.0
Balises
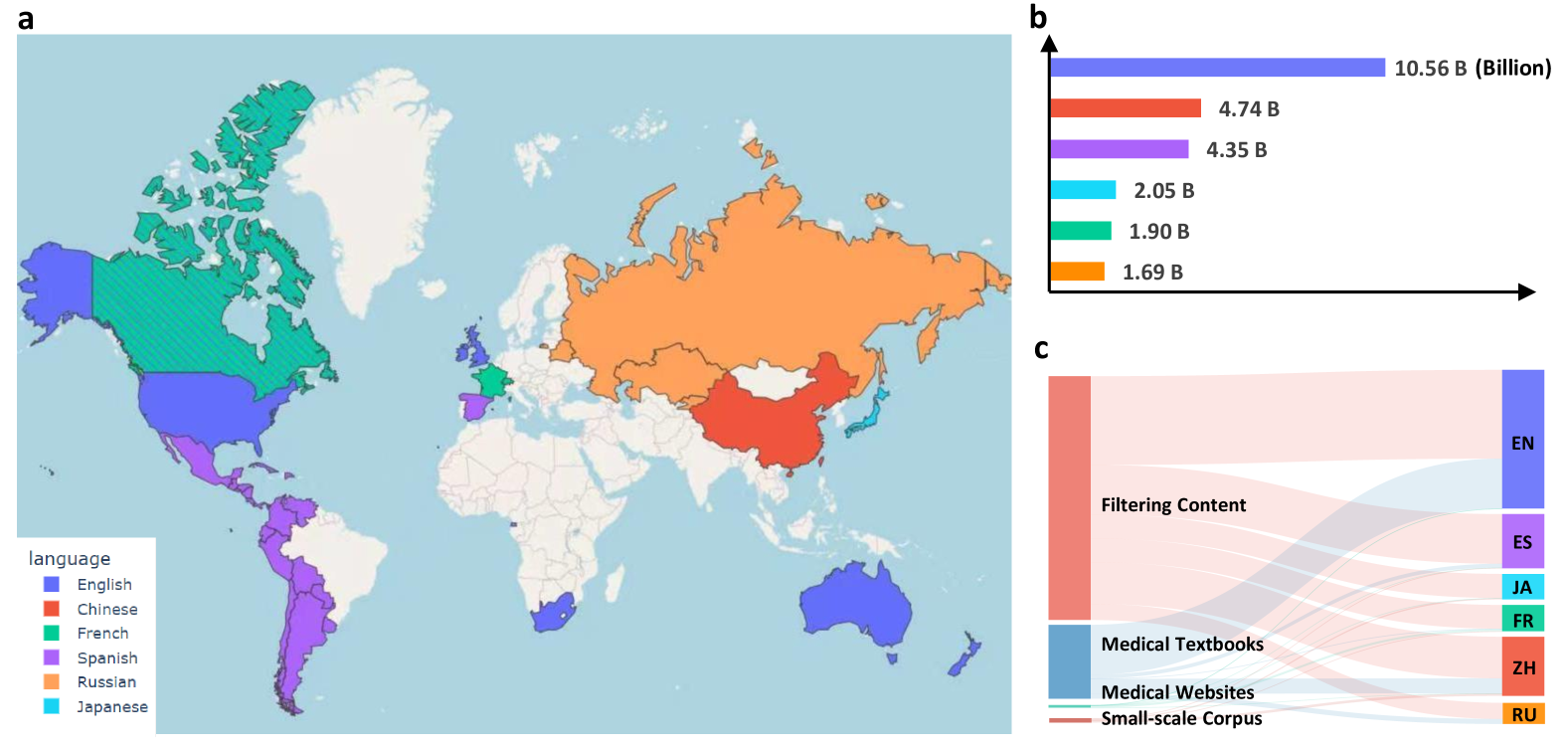
Le Massive Multilingual Medical Corpus (MMedC) est un corpus médical multilingue construit par l'équipe Smart Healthcare de l'École d'intelligence artificielle de l'Université Jiao Tong de Shanghai en 2024. Il contient environ 25,5 milliards de jetons couvrant 6 langues principales : anglais, chinois, japonais, français, russe et espagnol. Cet ensemble de données a été créé pour faire progresser le développement de modèles de langages médicaux multilingues, couvrant la majeure partie du monde, et la prise en charge de davantage de langues est toujours en cours de mise à jour et d'extension. Les résultats pertinents de l'article sontVers la construction d'un modèle linguistique multilingue pour la médecine", publié dans Nature Communications. Les sources de données de MMedC comprennent principalement quatre aspects : premièrement, le contenu lié à la médecine est filtré à partir de bases de données de textes généraux à grande échelle (telles que CommonCrawl) grâce à des algorithmes heuristiques ; deuxièmement, le texte est extrait des manuels médicaux à l’aide de la technologie de reconnaissance optique de caractères (OCR) ; troisièmement, les données sont extraites de sites Web médicaux officiellement agréés dans de nombreux pays ; enfin, certains ensembles de données médicales à petite échelle existants sont intégrés. De plus, afin d’évaluer le développement de modèles multilingues dans le domaine médical, l’équipe de recherche a également conçu une nouvelle norme d’évaluation de questions-réponses multilingues à choix multiples nommée MMedBench. Toutes les questions de MMedBench sont directement dérivées des banques de questions d'examen médical de divers pays plutôt que simplement obtenues par traduction, évitant ainsi les biais de compréhension diagnostique causés par les différences dans les directives de pratique médicale dans différents pays. Au cours du processus d'évaluation, le modèle doit non seulement choisir la bonne réponse, mais également fournir une explication raisonnable, testant ainsi davantage la capacité du modèle à comprendre et à interpréter des informations médicales complexes et à réaliser une évaluation plus complète. L'équipe de recherche a également ouvert le modèle de base médical multilingue MMed-Llama 3, qui a obtenu des résultats exceptionnels dans de nombreux tests de performance, surpassant considérablement les modèles open source existants et est particulièrement adapté au réglage fin personnalisé dans le secteur médical. Toutes les données et tous les codes ont été rendus open source, favorisant ainsi davantage la collaboration et le partage de technologies au sein de la communauté mondiale de recherche. La construction et l'open source de MMedC fournissent un support de données riche et de haute qualité pour la formation et l'évaluation de modèles de langage médical multilingues, aident à résoudre les problèmes de barrières linguistiques et de mondialisation des ressources médicales, et démontrent un grand potentiel d'application dans le domaine médical.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.