Command Palette
Search for a command to run...
Ensemble De Données De Compréhension Des Données Graphiques Et Textuelles Des Articles Scientifiques VEGA
Date
Taille
Organisation
URL de publication
URL du document
Balises
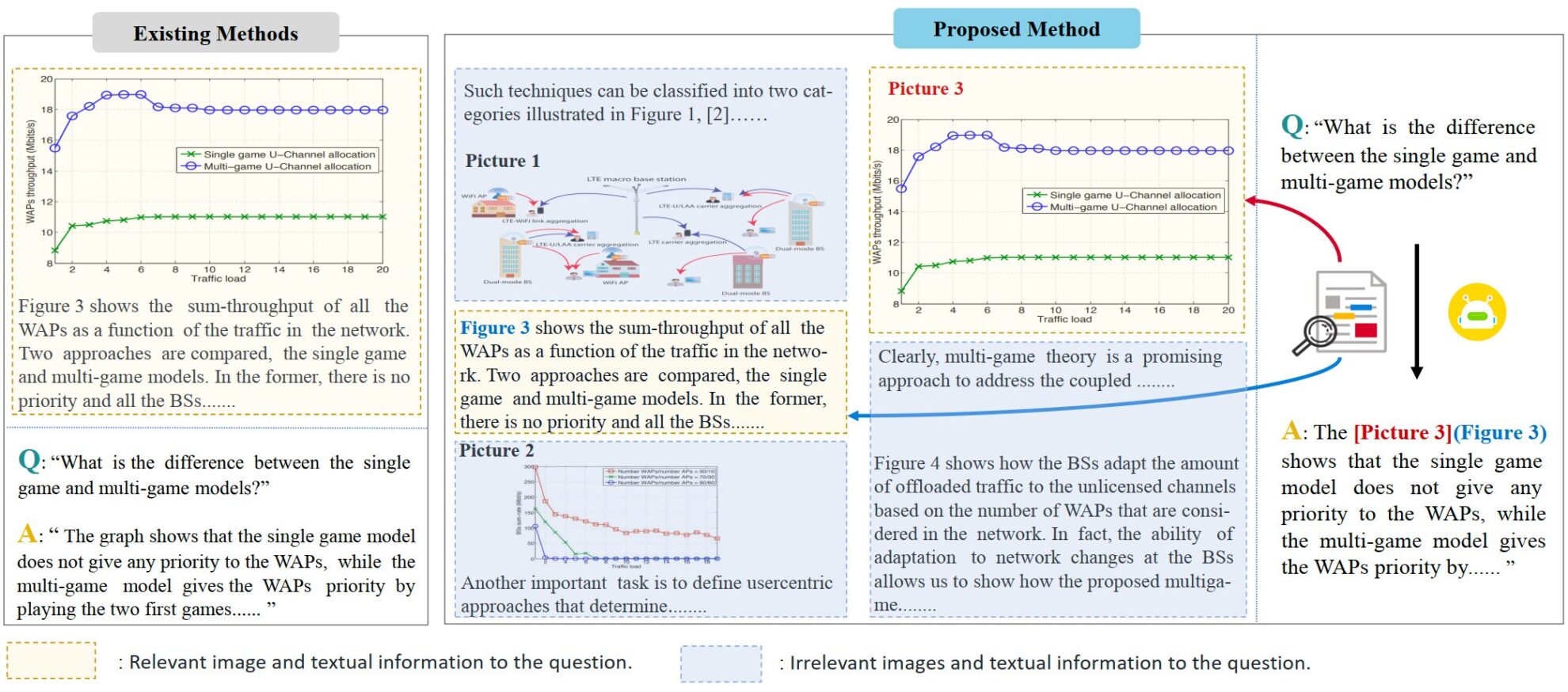
VEGA est un ensemble de données multimodal axé sur la compréhension des articles scientifiques. Il a été proposé par l'équipe de Ji Rongrong à l'Université de Xiamen en 2024 et est conçu pour évaluer et améliorer les performances des modèles lors du traitement d'entrées contenant des informations textuelles et visuelles complexes. Le document pertinent est «VEGA : Apprentissage de la compréhension image-texte entrelacée dans les grands modèles vision-langageL'ensemble de données contient des données textuelles et imagées issues de plus de 50 000 articles scientifiques et est spécialement conçu pour la tâche de compréhension d'images et de textes entrelacés (IITC). Le processus de construction de l'ensemble de données VEGA comprend trois étapes : le filtrage des questions, la construction du contexte et la modification des réponses. Il vise à fournir en entrée un contenu textuel et imagé entrelacé plus long et plus complexe, et exige que le modèle précise les images référencées lors de la réponse. VEGA est dérivé de l'ensemble de données SciGraphQA, qui est un ensemble de données pour les tâches de compréhension d'images papier et contient 295 000 paires questions-réponses. Sur cette base, l’équipe de recherche a réalisé trois étapes : sélection des questions, construction du contexte et modification des réponses pour obtenir l’ensemble de données VEGA. Il contient 593 000 données de formation de type papier et 2 326 données de test de 2 tâches différentes. Il vise à fournir un contenu entrelacé texte-image plus long et plus complexe en entrée et nécessite que le modèle spécifie les images référencées lors de la réponse.
- Sélection des questions : certaines questions de l’ensemble de données d’origine manquent de références d’images claires, ce qui entraînera une confusion lorsque les informations d’entrée seront étendues à plusieurs images.
- Construction du contexte : la question et la réponse dans l'ensemble de données d'origine ne concernent qu'une seule image et fournissent peu d'informations contextuelles. Afin d'augmenter la quantité de texte et d'images, l'équipe de recherche a téléchargé les fichiers sources des articles pertinents sur arxiv et a construit des données de deux longueurs : 4 000 jetons et 8 000 jetons. Chaque paire question-réponse contient jusqu'à 8 images.
- Modification de la réponse : L'auteur a modifié les réponses dans l'ensemble de données d'origine et a indiqué les images référencées lors de la réponse pour répondre aux exigences de la tâche IITC.
Citation
@misc{zhou2024vegalearninginterleavedimagetext, titre={VEGA : Apprentissage de la compréhension entrelacée image-texte dans les grands modèles vision-langage}, author={Chenyu Zhou et Mengdan Zhang et Peixian Chen et Chaoyou Fu et Yunhang Shen et Xiawu Zheng et Xing Sun et Rongrong Ji}, année={2024}, eprint={2406.10228}, préfixe d'archive={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2406.10228}, }
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.