Command Palette
Search for a command to run...
Ensemble De Données De Raisonnement De Bon Sens De Grand Modèle HellaSwag
Date
Taille
Organisation
URL de publication
URL du document
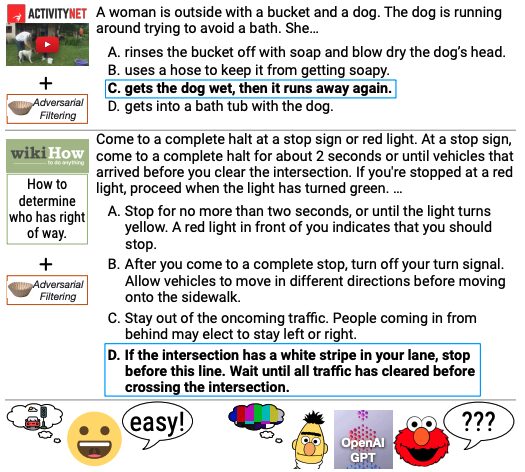
L'ensemble de données HellaSwag est un nouvel ensemble de données de défi pour tester l'inférence en langage naturel de bon sens (NLI de bon sens). L'ensemble de données a été lancé par l'Université de Washington et Allen AI en 2019 dans le but d'explorer les performances des modèles pré-entraînés en profondeur dans le raisonnement de bon sens en construisant un ensemble de données qui constitue un défi pour les modèles de pointe existants. Articles et résultats connexesHellaSwag : une machine peut-elle vraiment finir votre phrase ?" a été accepté par l'ACL 2019. L'ensemble de données HellaSwag contient 70 000 questions qui, bien qu'elles soient très faciles pour les humains (précision de plus de 95%), même les modèles de pointe ont du mal à atteindre des performances proches de celles des humains (précision d'environ 48%). L'ensemble de données est construit grâce à la méthode de filtrage contradictoire (AF), qui utilise une série de discriminateurs pour sélectionner de manière itérative les mauvaises réponses générées par la machine afin d'augmenter la difficulté de l'ensemble de données. La création de HellaSwag met en lumière le fonctionnement interne des modèles pré-entraînés en profondeur et offre une nouvelle direction à la recherche en PNL, où les repères co-évoluent avec les modèles de pointe de manière conflictuelle pour fournir des tâches plus difficiles.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.