HyperAI
Command Palette
Search for a command to run...
Ensemble De Données De Détection d'arbres Haute Résolution AdaTreeFormer-Yoesmite Yosemite
Date
il y a 2 ans
Taille
2.61 GB
URL de publication
URL du document
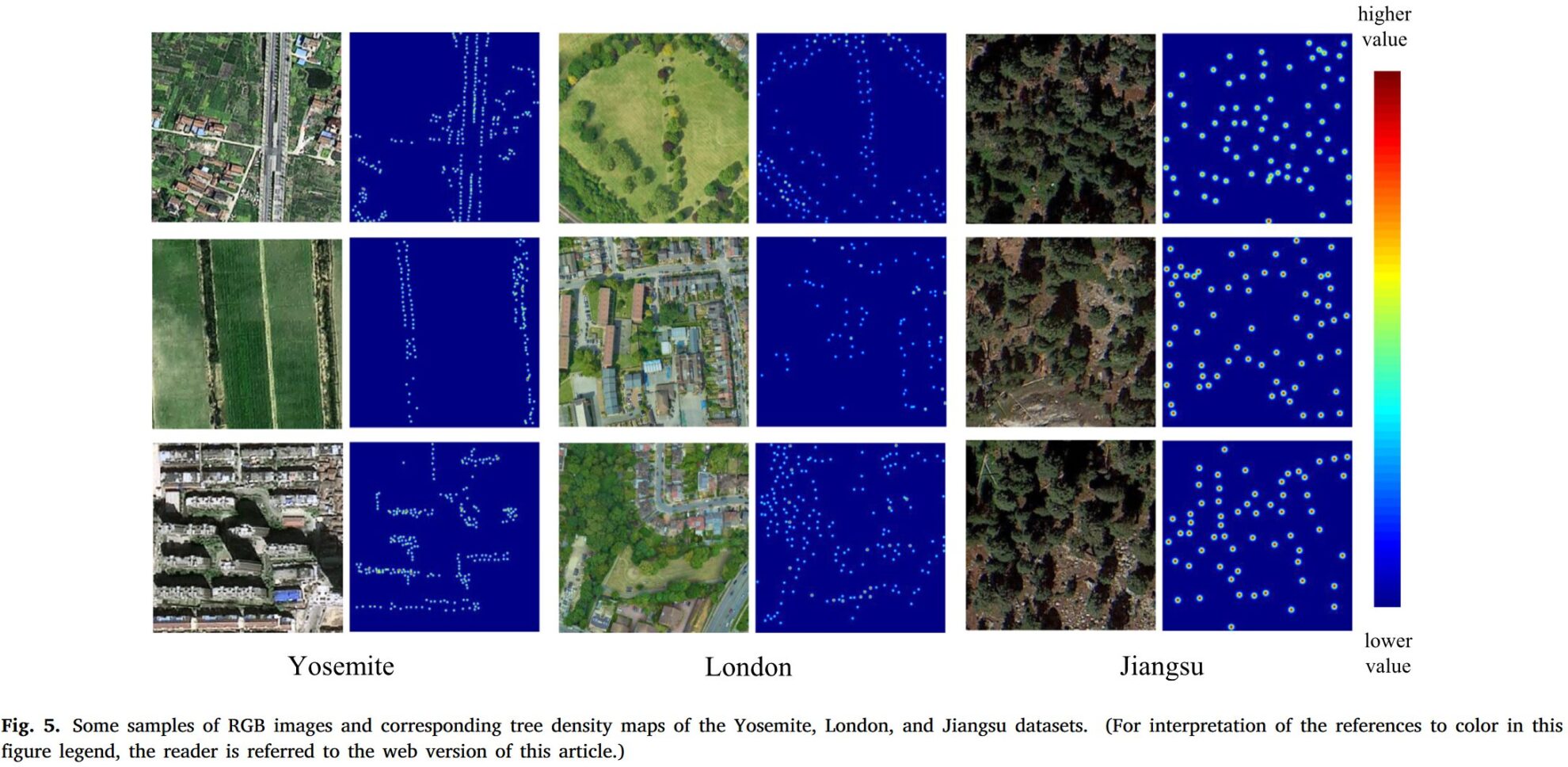
Cet ensemble de données a été créé par l'Université Tongji et le King's College de Londres dans l'article «AdaTreeFormer : adaptation de domaine à quelques clichés pour le comptage d'arbres à partir d'une seule image haute résolution" a été proposé dans le " Cet article contient trois ensembles de données : l'ensemble de données de Londres, l'ensemble de données de Yosemite et l'ensemble de données du Jiangsu. Cet ensemble de données est un ensemble de données de détection d'arbres à haute résolution à Londres.
- Emplacement : Parc national de Yosemite, Californie, États-Unis
- Type de paysage : Zone montagneuse boisée
- Nombre moyen d'arbres par image : 36
- Nombre total d'arbres : 98 949
- Résolution de l'image : 0,12 m
- Division des données : ensemble d'entraînement : 1 350 images, ensemble de test : 1 350 images L'ensemble de données Yosemite couvre principalement des zones montagneuses boisées avec une faible densité d'arbres et un terrain complexe, offrant un environnement de test important pour les performances des modèles sur des terrains complexes.
Contexte du jeu de données
- Différents types d’arbres et terrains : Différents types, tailles et formes d’arbres, ainsi que différents terrains (par exemple, urbains, agricoles, montagneux) rendent le comptage des arbres plus compliqué.
- Manque de données de formation de haute qualité : les modèles d’apprentissage en profondeur s’appuient généralement sur de grandes quantités de données étiquetées, mais ces données sont coûteuses et prennent du temps à obtenir.
- Problème d'écart de domaine : dans la tâche de comptage d'arbres, différentes scènes (telles que urbaines et rurales), différents types d'imagerie (tels que des images aériennes et des images satellites) et différentes densités d'arbres peuvent entraîner des différences significatives entre le domaine source et le domaine cible.
AdaTreeFormer-Yoesmite.torrent
Partage 2Téléchargement 0Terminé 177Total des téléchargements 298
Ce jeu de données est fourni par les utilisateurs de la communauté et est destiné uniquement à des fins éducatives et informatives. Si un contenu enfreint des droits d'auteur, veuillez nous contacter à [email protected] pour examen et retrait rapides.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.
Codage assisté par IA
GPU prêts à l’emploi
Tarifs les plus avantageux
HyperAI Newsletters
Abonnez-vous à nos dernières mises à jour
Nous vous enverrons les dernières mises à jour de la semaine dans votre boîte de réception à neuf heures chaque lundi matin
Propulsé par MailChimp