HyperAI
Command Palette
Search for a command to run...
LoveDA 用于领域自适应语义分割的遥感土地覆盖数据集
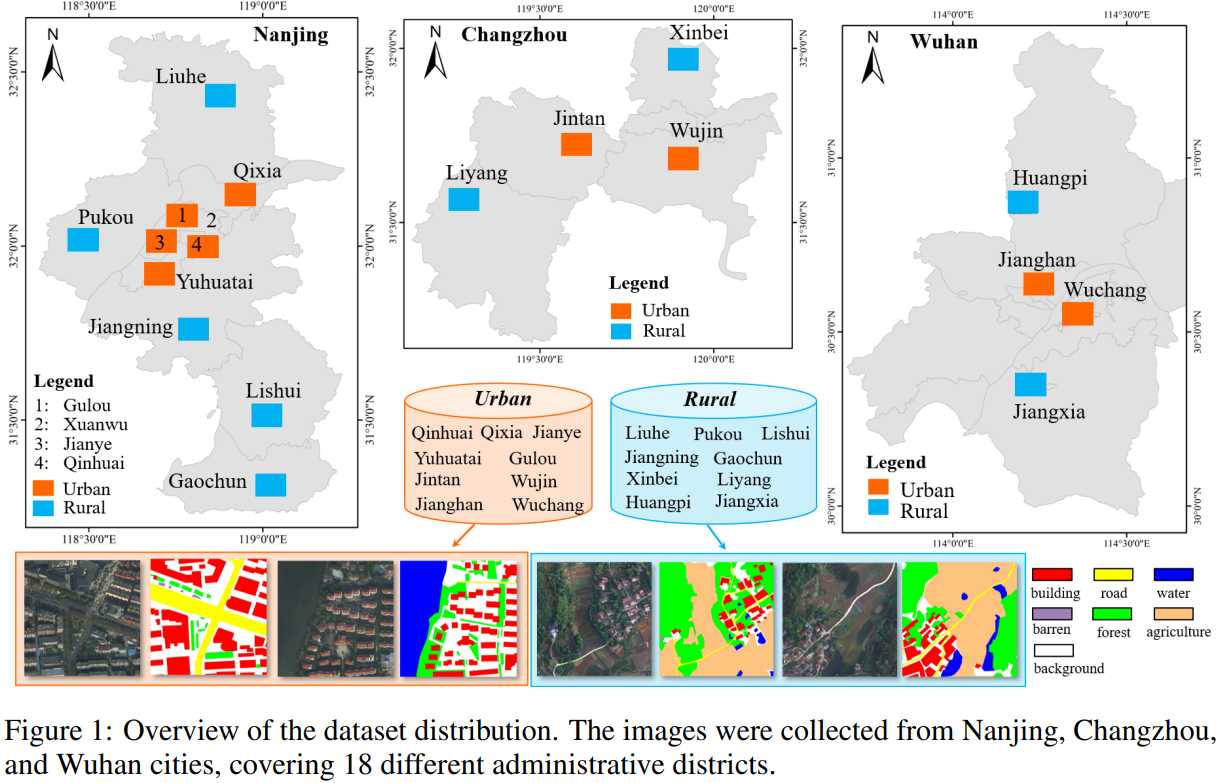
LoveDA 数据集是一个用于遥感领域的土地覆盖数据集,专门为域自适应语义分割 (Domain Adaptive Semantic Segmentation) 而设计。它由武汉大学测绘遥感信息工程国家重点实验室 RSIDEA 团队构建,旨在推动语义分割和迁移学习在遥感领域的研究。以下是 LoveDA 数据集的一些关键特点:
- 多尺度对象:数据集中的高空间分辨率 (HSR) 图像采集自中国三个不同城市的 18 个复杂的城乡场景,这些场景中的同一类别对象在不同的地理景观中呈现出完全不同的尺度变化。
- 复杂背景样本:LoveDA 数据集包含丰富的细节和更大的类内差异,特别是背景样本,这增加了分类任务的复杂性。
- 不一致的类别分布:城乡场景在类别分布上存在差异,城市场景包含更多的人造对象,如建筑和道路,而农村场景则包含更多的自然元素,如水体和森林。
- 适用性:该数据集既适用于土地覆盖的语义分割任务,也适用于无监督域适应 (UDA) 任务,为研究者提供了新的挑战和研究方向。
- 大规模标注:LoveDA 数据集包含 5,987 张高分辨率影像和 166,768 个标注的语义对象,是同类数据集中规模最大的之一。
- 数据来源:数据集的影像来源于 Google Earth 平台,收集自南京、常州和武汉,总覆盖面积达 536.15 平方公里。
- 开源:LoveDA 数据集是免费且开源的,相关代码和数据可以在 GitHub 上找到,促进了社区内的研究和合作。
- 社会影响:该数据集的开发旨在推进遥感领域的土地覆盖制图技术,可能对社会产生积极影响,如减少实地测绘所需的人力和物力资源。 LoveDA 数据集的发布为遥感领域的研究者提供了一个具有挑战性的数据资源,以解决实际问题,并推动相关技术的发展。
LoveDA.torrent
做种 1正在下载 0已完成 329总下载量 690
此数据集由社区用户贡献,仅用于教育和信息目的。如有任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。