Command Palette
Search for a command to run...
ワンクリックでライブポートレートをデプロイ
概要
One-sentence Summary
Using an online survey and analysis of software documentation and technical manuals, this study evaluates DSpace, EPrints, and Greenstone to examine how each open-source digital library management software assimilates and disseminates information to a world audience.
Key Contributions
- This paper presents a systematic comparative analysis of three open-source digital library management systems (DSpace, Greenstone, and EPrints) to evaluate their architectural designs and functional capabilities for institutional knowledge dissemination.
- By synthesizing findings from an online survey and technical documentation reviews, the study establishes a decision framework that aligns specific software features with organizational requirements including content format, distribution strategy, and deployment timelines.
- The evaluation demonstrates that these GPL-licensed platforms provide extensible, vendor-neutral architectures that lower implementation costs while supporting the reliable global dissemination of digital collections.
Introduction
Digital libraries have transitioned from simple digital archives into sophisticated, networked platforms that support global collaboration and long-term preservation of academic and cultural assets. Commercial management systems often restrict customization and create vendor dependency, while existing open source alternatives fragment across different architectures and metadata standards, complicating platform selection. The authors analyze leading open source digital library management systems, including DSpace, Greenstone, and EPrints, to map their technical capabilities against real world institutional requirements. By evaluating their extensibility, object models, and deployment workflows, the authors deliver a structured reference guide that enables organizations to select the optimal framework based on content format, distribution strategy, and technical constraints.
Dataset
-
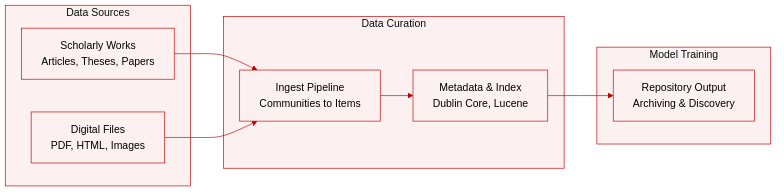
Dataset composition and sources: The authors describe DSpace as a digital asset management repository developed jointly by MIT Libraries and HP Labs. The dataset comprises institutional scholarly outputs such as articles, papers, theses, and dissertations, contributed by universities, research centers, and libraries to support open access and long-term digital archiving.
-
Key details for each subset: Data follows a strict hierarchical structure. Communities and sub-communities reflect institutional units like colleges or laboratories. Collections group related content and may span multiple communities. Items serve as the foundational archival elements, each tied to a single owning collection. Items are subdivided into bundles containing bitstreams categorized as ORIGINAL files, THUMBNAILS, TEXT extracted for indexing, LICENSE documents, and CC_LICENSE metadata. The system accommodates diverse formats including PDF, HTML, JPEG, TIFF, MP3, and AVI.
-
How the paper uses the data: The authors treat DSpace as a repository architecture rather than a machine learning training corpus. They do not specify model training splits, mixture ratios, or algorithmic fine-tuning procedures. Instead, the paper focuses on how the system ingests, preserves, indexes, and exposes academic content for interoperable discovery and institutional management.
-
Processing and metadata construction: The authors outline a standardized ingest and preservation workflow. Every item receives a qualified Dublin Core metadata record, with optional crosswalks like MODS and MARC21 compatibility for external system exchange. Full-text extraction runs automatically during submission to populate the TEXT bundle for search indexing. Non-dynamic HTML documents are preserved using relative links to maintain internal references, while absolute links are stored unchanged. Batch tools convert content into directory structures with XML metadata files for import and export. Persistent identifiers are assigned via the CNRI Handle System, and search indexing is powered by Apache Lucene to enable fielded queries, stemming, and stop word removal.
Method
The authors leverage a modular and extensible architecture designed to support the management, preservation, and retrieval of digital scholarly content within an open-access repository system. The overall framework is structured around three primary phases: submission, management, and retrieval, each governed by distinct components and workflows. At the core of the system, metadata and digital files are organized into items, which are stored within collections and communities, forming the foundation for both preservation and discovery.
The submission process begins with the submitter, who uploads files and associated metadata through a web interface. As shown in the figure below, this input is processed into structured data streams that are routed into the management layer. The management component handles the storage of items, which consist of both the digital file and its corresponding metadata. These items are organized within collections and communities, which serve as logical groupings for content. The system ensures long-term preservation by maintaining an archive in a current format, with mechanisms in place to update and manage the repository's content over time.

Within the management layer, the system supports administrative control over metadata schemas, allowing administrators to define the fields that are captured for each item type. This configuration enables customization of the submission form, ensuring that only relevant metadata fields are presented to users. The system supports a range of item types, such as refereed journal articles, theses, and technical reports, each with its own set of mandatory and optional metadata fields. This flexibility is achieved through a layered approach to metadata handling, where the schema is defined in three or four stages: defining the maximal set of fields, specifying item types, determining which fields are mandatory per type, and mapping these to the Open Archives Initiative (OAI) standards for interoperability. The system also provides a core API in Perl, enabling developers to access and extend the underlying digital library functionality.

The retrieval phase is designed to support efficient browsing and searching by end-users. The system allows users to navigate through the repository using metadata-based browsing, enabling them to filter results by criteria such as author, department, year, or publication type. This navigation is facilitated through a concept referred to as representations, or views, which generate hierarchical structures from the metadata fields. As illustrated in the figure below, these views are derived from the item metadata and provide a flexible way to organize and present content. The system supports full-text and field-based searching, allowing users to query specific metadata fields with fine granularity via SQL queries. Additionally, the system is OAI-compliant, enabling automated harvesting of metadata by external services, which enhances the dissemination of content across a global network of repositories.

The system architecture also incorporates multiple user roles—administrator, editor, and author—each with distinct permissions and responsibilities. The administrator manages the backend configuration, including the appearance and functionality of the web interface and the overall repository setup. Editors review submissions prior to publication and may correct metadata to maintain consistency. Authors are responsible for submitting documents and managing their own submissions, including editing and removal, subject to administrative restrictions. The system is built on open-source technologies, including MySQL for the database and Apache for the web server, with the application logic implemented in Perl, ensuring a robust, scalable, and customizable platform.