Command Palette
Search for a command to run...
Rapport technique sur VoxCPM2
Rapport technique sur VoxCPM2
VoxCPM Team
Résumé
Nous présentons VoxCPM2, un modèle fondamental entièrement open-source de génération de parole multilingue et contrôlable, qui étend le paradigme de modélisation hiérarchique combinant diffusion et régression automatique (autoregressive) de VoxCPM. VoxCPM2 améliore ce cadre dans trois dimensions clés : (i) les capacités, en unifiant 30 langues, 9 dialectes chinois, la conception de voix par langage naturel, le clonage de voix contrôlable par style, et le clonage de continuation haute fidélité au sein d’une même architecture de base ; (ii) la qualité, grâce à un AudioVAE asymétrique qui encode à 16 kHz et reconstruit à 48 kHz, permettant une super-résolution implicite avec une efficacité d’encodage élevée ; et (iii) l’échelle, en faisant évoluer simultanément le modèle jusqu’à 2 milliards de paramètres et les données d’entraînement jusqu’à plus de 2 millions d’heures de parole multilingue. Pour supporter ces capacités variées au sein d’un seul modèle, nous introduisons une organisation unifiée des séquences qui exprime tous les modes de génération par différentes combinaisons des mêmes blocs d’entrée de base, permettant un entraînement conjoint sous un seul ensemble de paramètres et de fonction objectif. VoxCPM2 atteint des performances de pointe ou compétitives sur les benchmarks publics TTS en zero-shot et suivant des instructions. Sur notre jeu d’évaluation interne de 30 langues, il obtient un WER moyen de 1,68 %. Ces résultats démontrent que la modélisation hiérarchique par latents continus, sans recourir à aucun tokenizer discret de parole externe, offre une fondation viable et puissante pour la génération de parole multilingue et contrôlable à grande échelle. Les poids du modèle, le code de fine-tuning et les outils d’inférence sont publiés publiquement sous licence Apache 2.0 afin de favoriser la recherche et le développement au sein de la communauté.
One-sentence Summary
VoxCPM2 is a fully open-source multilingual and controllable speech generation foundation model extending the hierarchical diffusion-autoregressive paradigm of VoxCPM to unify 30 languages, 9 Chinese dialects, and style-controllable voice cloning within a 2B parameter backbone trained on over 2 million hours of multilingual speech, utilizing an asymmetric AudioVAE enabling implicit super-resolution and a unified sequence organization to operate without any external discrete speech tokenizer while achieving state-of-the-art or competitive performance on public zero-shot and instruction-following TTS benchmarks and an average WER of 1.68% on an internal 30-language evaluation set, with model weights, fine-tuning code, and inference tools released under the Apache 2.0 license.
Key Contributions
- The paper introduces VoxCPM2, a fully open-source foundation model that unifies 30 languages, 9 Chinese dialects, and diverse generation modes within a single hierarchical continuous-latent backbone. A unified sequence organization expresses all generation modes through different arrangements of the same input building blocks to allow joint training under a single set of parameters.
- Quality is advanced through an asymmetric AudioVAE that encodes at 16 kHz and reconstructs at 48 kHz to enable implicit super-resolution with high encoding efficiency. This architecture supports hierarchical continuous-latent modeling without relying on any external discrete speech tokenizer.
- The model is jointly scaled to 2B parameters and trained on over 2 million hours of multilingual speech to support diverse capabilities. Performance evaluations show state-of-the-art or competitive results on public zero-shot and instruction-following TTS benchmarks, including an average word error rate of 1.68% on an internal 30-language set.
Introduction
Modern text-to-speech applications demand high acoustic fidelity and precise control over speaker identity for uses like dubbing and digital characters. Current approaches often struggle to balance these needs because discrete-token models discard fine acoustic details and continuous-latent alternatives face optimization challenges when jointly modeling structure and texture. The authors introduce VoxCPM2 to address these limitations by leveraging a hierarchical backbone featuring a differentiable semi-discrete bottleneck. This architecture enables end-to-end training on continuous latents without external tokenizers to facilitate joint optimization of semantic planning and acoustic rendering while treating natural-language voice descriptions as ordinary text prefixes for unified controllability.
Dataset
- Dataset Composition: The total training corpus comprises over 2 million hours of multilingual speech where Chinese and English form the majority. The remaining 28 languages range from roughly 1K to 50K hours each based on availability and quality.
- Controllable Data Sources: For controllable generation, the authors combine tens of thousands of hours of open-source expressive speech with several thousand hours of internally curated data. Open-source portions provide broad coverage of emotions and speakers while the internal subset emphasizes higher annotation precision.
- Processing and Annotation: The base TTS data follows a standard pipeline including source separation, voice activity detection, and ASR-based transcript alignment. They pre-screen unlabeled corpora using lightweight emotion classifiers and generate natural-language descriptions for voice design and style attributes using audio understanding models.
- Training Strategy: To decouple style from content, the team clones voice and style onto semantically unrelated transcripts and mixes this synthetic data primarily in stage 2. Reference clips are harvested from the same recording session with speaker-embedding cosine similarity above 0.7, while stage 3 annealing restricts the mixture to natively recorded high-quality speech.
Method
VoxCPM2 adopts a hierarchical diffusion-autoregressive framework where speech is modeled entirely within the continuous latent space of an asymmetric AudioVAE. The architecture comprises four primary components that interact to predict the next latent patch step-by-step: a Local Encoder (LocEnc), a Text-Semantic Language Model (TSLM), a Residual Acoustic Language Model (RALM), and a Local Diffusion Transformer (LocDiT).
Refer to the framework diagram below to visualize the data flow and module interactions within the unified system.
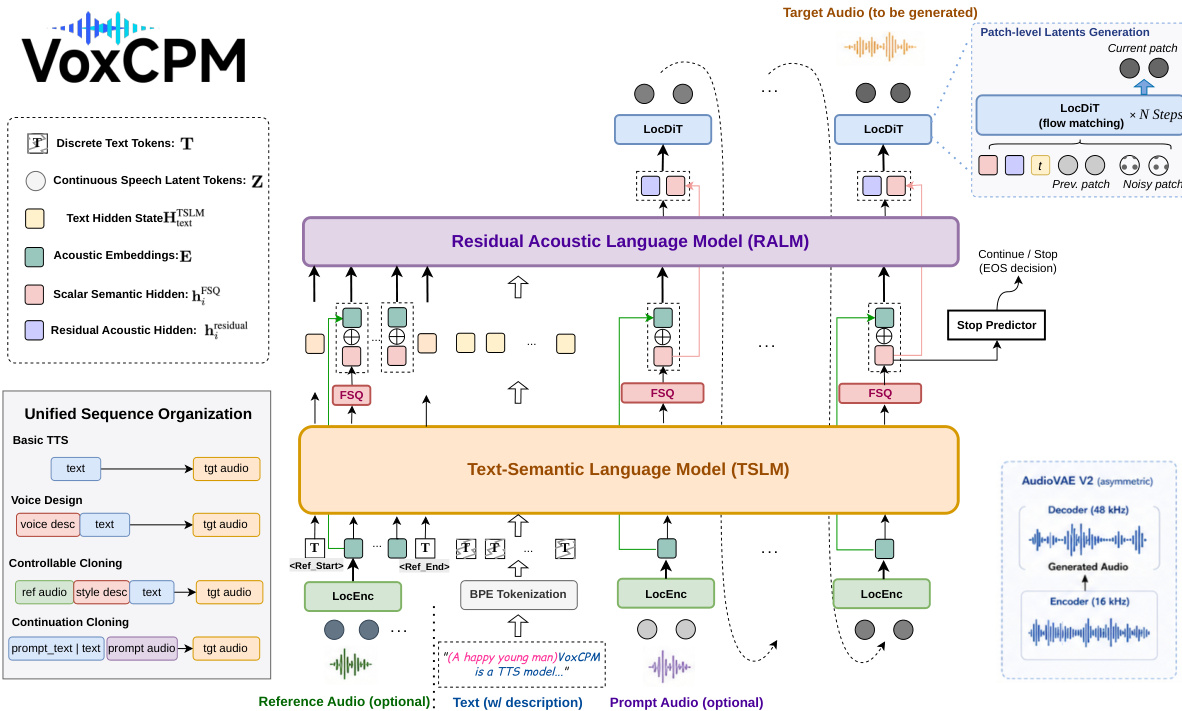
The generation process at the i-th patch is formulated as predicting the latent zi conditioned on the previous history and text input:
zi∼LocDiT(hiFSQ, hiresidual, zi−1; t)The TSLM first processes the input text tokens T and acoustic history embeddings E<i produced by the LocEnc. The hidden states from the TSLM are passed through a Finite Scalar Quantization (FSQ) layer to create a semi-discrete semantic skeleton hiFSQ. Simultaneously, the RALM recovers fine-grained acoustic details. It conditions on the TSLM text-side hidden states and a fusion of the FSQ-quantized audio history and LocEnc embeddings. In VoxCPM2, this fusion is implemented via a learnable concatenation-projection rather than simple summation:
hires_in=Wfuse[ hiFSQ∥Ei]This design preserves richer information from both streams. The resulting residual hidden states hiresidual are then fed into the LocDiT. Unlike previous iterations, the LocDiT receives hiFSQ and hiresidual as separate conditioning tokens alongside the diffusion timestep t and the previous latent patch zi−1. This multi-token conditioning prefix prevents early information collapse and provides higher-bandwidth guidance for the diffusion decoder.
The underlying representation is handled by AudioVAE V2, an asymmetric codec that encodes 16 kHz waveforms into 64-dimensional latent frames at 25 Hz and reconstructs them at 48 kHz. The backbone groups every P=4 frames into a single patch, resulting in a compact 6.25 Hz autoregressive sequence. This asymmetric design enables implicit super-resolution while maintaining a low token rate for efficient generation.
To support diverse capabilities such as basic TTS, voice design, and controllable cloning, VoxCPM2 employs a unified sequence organization. All generation modes are expressed through different arrangements of the same input building blocks: text tokens, reference audio segments (bracketed by REF_START/REF_END), and target audio segments. During training, only the target audio contributes to the loss, while the other blocks serve as conditioning context. The model is trained end-to-end using a two-term objective consisting of a patch-level conditional flow-matching loss on the target latent patches and a binary stop-prediction loss on the TSLM-FSQ hidden states. A three-stage progressive curriculum is utilized, starting with multilingual TTS pretraining, followed by joint training with controllable data, and concluding with high-quality annealing on a curated subset.
Experiment
VoxCPM2 was evaluated on diverse public and internal benchmarks to assess zero-shot voice cloning, multilingual synthesis, and natural-language controllability. The experiments demonstrate that the unified model achieves competitive speaker similarity and intelligibility across numerous languages, while subjective tests confirm high naturalness and instruction adherence alongside efficient inference on consumer-grade hardware. These findings validate the effectiveness of the hierarchical continuous-latent paradigm in balancing scalability, voice fidelity, and controllability within a single foundation model.
The provided the the table displays subjective listening test results for controllable generation, evaluating systems on naturalness and instruction-following. VoxCPM2 achieves the highest score for instruction adherence while maintaining a naturalness rating that is competitive with the leading system. These results indicate that VoxCPM2 offers a strong balance between following text-based voice design instructions and producing natural-sounding speech. VoxCPM2 achieves the highest instruction-following score among the compared systems. The model maintains competitive naturalness, ranking just behind the top performer. VoxCPM2 outperforms other open-source baselines like VoiceSculptor and MOSS-VoiceGenerator in both metrics.

The the the table compares the reconstruction quality of the Audio VAE components across three model versions on VCTK and Song Descriptor datasets. It highlights that while VoxCPM1.5 achieves the best full-band mel-distance by operating natively at high sample rates, VoxCPM2 delivers competitive performance across both low- and full-band metrics despite utilizing a more challenging super-resolution architecture. VoxCPM2 demonstrates competitive reconstruction quality across both low-band and full-band metrics despite employing a super-resolution setup. VoxCPM1.5 achieves the strongest full-band mel-distance performance, attributed to its native operation at a higher sample rate. VoxCPM maintains highly competitive results on 16 kHz-band speech metrics such as mel-distance and perceptual quality.

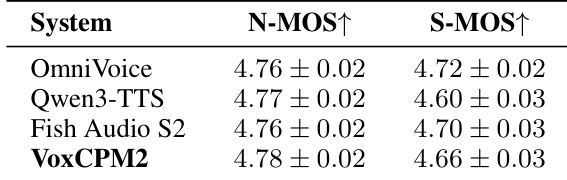
The authors present subjective listening test results comparing the naturalness and speaker similarity of VoxCPM2 against other state-of-the-art systems. The data indicates that VoxCPM2 achieves the highest perceived naturalness while maintaining speaker similarity scores that are competitive with the leading baselines. VoxCPM2 secures the top position for naturalness ratings among the compared systems. OmniVoice demonstrates the highest speaker similarity score. Qwen3-TTS records the lowest speaker similarity rating in this evaluation.
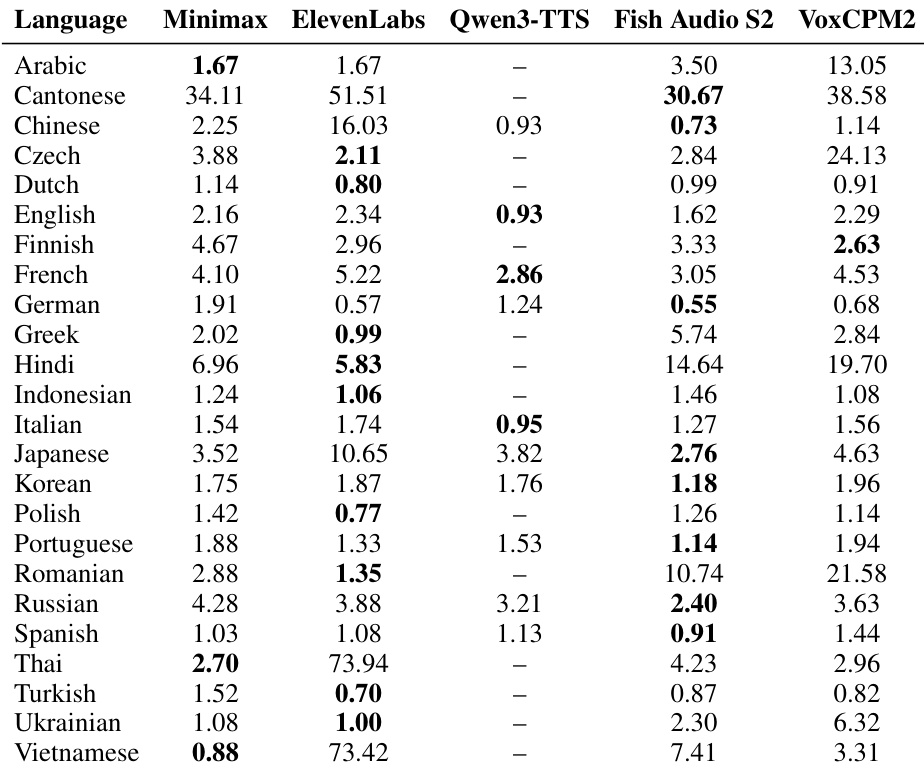
The the the table displays multilingual zero-shot voice cloning results on the CV3-Eval benchmark, comparing VoxCPM2 against CosyVoice variants and Fish Audio S2. While Fish Audio S2 generally achieves the lowest error rates across most standard language subsets, VoxCPM2 outperforms all models on the challenging hard subset for Chinese. Additionally, VoxCPM2 reports results for a wider variety of languages compared to the CosyVoice models, which lack data for several European languages. VoxCPM2 achieves the best performance on the challenging hard Chinese subset. Fish Audio S2 generally outperforms other models on standard language subsets and the hard English subset. VoxCPM2 provides broader language coverage than the CosyVoice variants, including results for German, Spanish, and Russian.

The the the table compares intelligibility performance across 24 languages, showing that Fish Audio S2 and ElevenLabs generally achieve the lowest error rates. VoxCPM2 demonstrates competitive results, notably achieving the best score on Finnish, though it lags behind on Arabic and Hindi. VoxCPM2 achieves the best intelligibility on Finnish, outperforming all other compared systems. Fish Audio S2 and ElevenLabs secure the lowest error rates on the majority of the tested languages. VoxCPM2 exhibits higher error rates on Arabic and Hindi compared to its performance on other languages.
Subjective listening tests reveal that VoxCPM2 achieves the highest instruction adherence and naturalness ratings while maintaining competitive speaker similarity against top-performing baselines. Audio reconstruction assessments demonstrate that the model sustains high quality across frequency bands despite utilizing a challenging super-resolution architecture. Furthermore, multilingual evaluations highlight the system's strength on specific challenging subsets like Chinese and Finnish while offering broader language coverage than comparable models.