Command Palette
Search for a command to run...
SoCRATES : Vers une évaluation automatisée et fiable de la médiation proactive par LLM à travers les domaines et les variations socio-cognitives
SoCRATES : Vers une évaluation automatisée et fiable de la médiation proactive par LLM à travers les domaines et les variations socio-cognitives
Taewon Yun Hyeonseong Park Jeonghwan Choi Hayoon Park Yeeun Choi Hwanjun Song
Résumé
L'évaluation des médiateurs LLM reste un défi, car la médiation se déploie comme une trajectoire en temps réel façonnée par les émotions fluctuantes, les intentions et le contexte des parties en conflit. Les bancs d'essai existants reposent sur un nombre limité de domaines conçus par des experts, font varier principalement la posture stratégique, et attribuent une note à chaque tour en fonction de chaque sujet, ce qui introduit un bruit hors sujet. Nous présentons SoCRATES, un benchmark visant à évaluer les médiateurs LLM proactifs dans des bancs d'essai réalistes et multi-domaines. Il génère des scénarios à partir de conflits réels au moyen d'un pipeline agentic couvrant huit domaines, explore cinq axes d'adaptation socio-cognitifs (posture stratégique, composition des parties, longueur de l'historique, réactivité émotionnelle et identité culturelle), et évalue chaque sujet uniquement sur les tours qui le font progresser, grâce à un évaluateur localisé par sujet. L'évaluateur atteint un alignement de 0,82 avec les experts humains, dépassant de plus de deux fois la ligne de base par tour. L'évaluation de huit LLM de pointe révèle que même le médiateur le plus performant ne comble qu'environ un tiers de l'écart de consensus non médiatisé dans des bancs d'essai variés et réalistes. Les performances varient considérablement selon l'axe socio-cognitif, ce qui souligne que les progrès futurs résideront dans l'adaptation sociale à des conditions diversifiées.
One-sentence Summary
SoCRATES introduces a benchmark for proactive LLM mediators that constructs scenarios across eight domains via an agentic pipeline, probes five socio-cognitive adaptation axes, and employs a topic-localized evaluator to score only turns that advance each topic, achieving 0.82 alignment with human experts and revealing that even the strongest of eight frontier models closes merely a third of the unmediated consensus gap, underscoring that progress depends on social adaptation to diverse conditions.
Key Contributions
- This work introduces SoCRATES, a unified automated evaluation framework that constructs realistic conflict scenarios through an agentic pipeline across eight domains and probes five socio-cognitive adaptation axes.
- The framework incorporates a topic-localized evaluator that scores mediator trajectories along three real-time metrics by restricting assessments to turns that advance specific topics, achieving 0.82 alignment with human experts.
- Comprehensive benchmarking of eight frontier LLM mediators demonstrates that the strongest models close only approximately one-third of the unmediated consensus gap, with performance varying sharply across socio-cognitive conditions.
Introduction
Deploying large language models as automated mediators holds significant promise for scaling conflict resolution, yet current systems struggle to bridge the consensus gap in dynamic, practical disputes. Prior evaluation frameworks face three major bottlenecks: they rely on a narrow set of expert-authored scenarios, conflate multiple socio-cognitive variables, and score every dialogue turn against every topic, which injects off-topic noise and compounds evaluation errors. To address these gaps, the authors introduce SoCRATES, a unified benchmark that automatically curates realistic conflict scenarios across eight domains and probes mediator performance across five independent socio-cognitive axes. They also develop a topic-localized evaluator that scores only the turns that actively advance a given topic, achieving strong alignment with human experts. This framework reveals that even leading LLM mediators close only about a third of the unmediated consensus gap, demonstrating that future progress depends on robust socio-cognitive adaptation rather than raw conversational fluency.
Dataset

-
Dataset Composition and Sources
- The authors curate conflict scenarios from real-world disputes using an agentic deep research pipeline that synthesizes web evidence across eight canonical domains.
- These domains include transactional, healthcare, environmental, business-to-business, public-policy, international, legal, and intra-organizational categories, all drawn from Harvard teaching materials.
- All scenarios are anonymized by agents to remove references to specific individuals, organizations, or locations, ensuring no real people are involved in the simulation.
-
Key Details for Each Subset
- The curation process produces 40 hard conflict scenarios, maintaining five scenarios per domain as the general condition baseline.
- Each scenario is structured with a background, a party set containing roles and per-topic stances, a topic set with options, and a preference allocation for each party.
- The base scenarios are expanded into 15 distinct socio-cognitive conditions by applying five independent axes to fresh copies of each scenario.
- Context axes include strategic posture with Thomas-Kilmann modes, party composition that adds a third disputant, and history length expanded to five times the default.
- Persona axes vary emotional reactivity between composed and reactive endpoints and assign cultural identities based on US, CN, and KR Hofstede profiles.
- Cultural conditions generate three intra-cultural and three cross-cultural pairings, with all parties prompted to interact in English to isolate identity from language.
-
Data Usage and Processing
- The authors employ a three-step pipeline where a Searcher agent collects conflict cases, a Scenario Writer agent recasts them into structured formats, and a Simulation agent filters the data.
- Filtering retains only scenarios that fail to resolve in unmediated multi-turn dialogues, requiring three independent replays to end in an impasse for inclusion.
- Impasses are defined as consensus failure, a party walking away, or reaching a 100-turn budget, with rejected scenarios feeding back to the Searcher to generate new seeds.
- The Searcher uses o4-mini-deep-research for seed collection, the Writer uses GPT-5.4 for recasting, and the Simulator uses DeepSeek-V3.2 agents that maintain fixed cyclic turns and private inner thoughts.
-
Metadata and Validation Details
- Cultural metadata is constructed by appending deterministic statements summarizing Hofstede dimension scores to party profiles, while emotional reactivity uses a fixed parameterized template.
- The dataset supports topic-localized evaluation where consensus is annotated at the snippet level, capturing one back-and-forth exchange per data point for granular scoring.
- The authors validate persona fidelity and consensus alignment using crowd-sourced annotators and expert reviewers, ensuring role consistency and accurate tracking of negotiation progress.
Method
The SoCRATES framework operates through a three-stage pipeline designed to simulate and evaluate mediation in social conflicts. The first stage, agentic scenario curation, constructs a diverse set of conflict scenarios by leveraging real-world public disputes. This process begins with a search agent that identifies relevant conflict cases from public sources, generating seed reports that encapsulate the timeline, stakeholders, core issues, and institutional tensions of each dispute. These seeds are then processed by a scenario writer agent, which reformats them into a structured negotiation simulation format. This recasting ensures that all real-world identifiers are replaced with fictional names, while preserving the core dynamics of the conflict, including the number of topics, their discrete options, and the divergent stances of the parties involved. The resulting scenario is represented as a tuple s=(B,P,T,W), where B denotes the background information, P the set of disputing parties, T the topics of conflict, and W the preference weights for each party.
The second stage, socio-cognitive probing, expands the initial scenario along five distinct axes—personality, background, context, emotional regulation, and strategic adaptation—to generate a rich set of conditions. Each axis perturbs a specific component of the scenario: party profiles, background, or the party set. This expansion results in 15 conditions per scenario, with the general condition serving as the baseline. The perturbations are designed to test how different socio-cognitive factors influence conflict dynamics. Within each scenario, the parties are modeled as large language model (LLM) agents, each equipped with a private profile that includes an objective, a fallback position, a per-topic starting stance, a persona, and a weight vector over topics. The mediator, also an LLM agent, observes only the shared inputs—background, topics, and dialogue—and must infer the hidden states of the parties to intervene effectively.
The final stage, topic-localized evaluation, assesses the mediator's performance using three metrics: consensus gain, intervention timeliness, and intervention effectiveness. The evaluation framework compares the mediated trajectory against a matched unmediated run, tracking the cumulative consensus state S≤t at each turn t. Consensus gain measures the overall contribution of the mediator by quantifying the fraction of the unmediated consensus gap closed at the end state. Intervention timeliness rewards prompt responses, measuring the delay between a drop in consensus and the mediator's intervention within a 10-turn window. Intervention effectiveness evaluates the consensus lift produced by each intervention, normalized to account for ceiling effects. The evaluation is conducted using a topic-localized scoring approach, where the agreement score for each topic is determined only during turns when it is actively discussed, reducing noise from irrelevant content and improving accuracy.
The entire process is implemented using a series of LLM-based agents, each with specific roles and prompts. The scenario writer uses a structured prompt to ensure the simulation adheres to the required format. The preference weighting agent generates positive integer weights summing to 100 for each party, ensuring a clear priority ordering. The party agents, operating at a temperature of 0.6, produce both private inner thoughts and public utterances, with the former contributing to their private history and the latter forming the dialogue. The mediator agent, also running at temperature 0.6, first decides whether to intervene based on a predefined condition and, if so, generates a strategic utterance to guide the parties toward agreement. This modular design enables the systematic exploration of mediation strategies under diverse socio-cognitive conditions.
Experiment
The study evaluates eight LLM mediators across diverse conflict domains and socio-cognitive conditions using the SoCRATES benchmark, which relies on controlled persona simulators and a topic-localized evaluation framework. Initial validation confirms that the simulated disputants reliably follow prescribed behavioral variations and that the automated scoring system closely aligns with human expert judgments. Qualitative analysis reveals that social conflict resolution remains highly challenging for current models, with performance driven by contextual adaptation rather than model scale or intervention frequency. Ultimately, effective mediation requires dynamically adjusting both the timing and content of interventions to match evolving strategic, emotional, and cultural demands, as rigid or overly eager mediation strategies consistently fail to advance consensus.
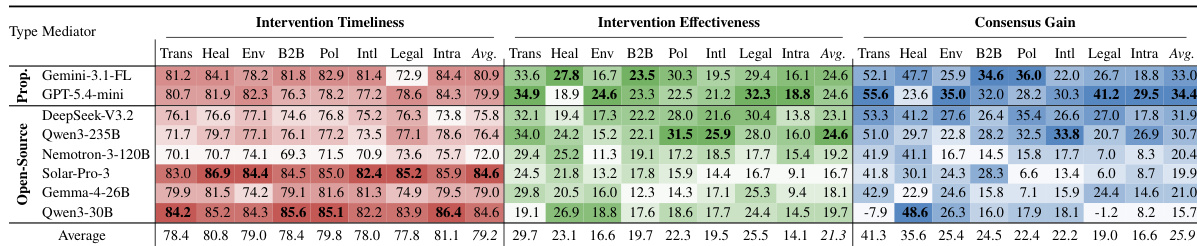
The authors evaluate LLM mediators across multiple conflict domains and socio-cognitive axes, assessing their performance through consensus gain, intervention timeliness, and effectiveness. The results show that mediator performance varies significantly across domains and conditions, with strong mediators adapting their intervention timing to match the evolving socio-cognitive demands of the conflict. Performance is not consistently linked to model size or proprietary status, and mediators that intervene too frequently without meaningful impact achieve high timeliness but low consensus gain. Mediator performance varies widely across conflict domains, with significant differences in consensus gain depending on the type of conflict. Intervention effectiveness depends on timing adaptation; strong mediators peak at the right moments based on the conflict's socio-cognitive demands. Mediators that intervene too early or too often achieve high timeliness but fail to improve consensus, indicating that frequency does not equate to effectiveness.

The authors evaluate the performance of LLM mediators using a benchmark that measures intervention timeliness, intervention effectiveness, and consensus gain. Results show that the benchmark captures meaningful differences in mediator behavior, with strong mediators adapting their intervention timing to the socio-cognitive demands of the conflict. The evaluation demonstrates that effective mediation requires both timely and substantive interventions, as early and frequent intervention does not guarantee improved outcomes. Intervention timeliness and effectiveness show distinct trends, with strong mediators adapting their timing to the conflict's socio-cognitive demands. Consensus gain varies significantly across conflict domains, indicating that mediators perform differently depending on the context. Intervention effectiveness correlates more strongly with consensus gain than with intervention frequency, suggesting that the quality of intervention matters more than the quantity.
The authors evaluate LLM mediators across multiple conflict domains and socio-cognitive axes using a benchmark that measures intervention timeliness, effectiveness, and consensus gain. Results show that mediator performance varies significantly across domains and conditions, with no single model excelling across all metrics, and that effective mediation requires adapting timing and content to the specific conflict context. Mediator performance varies widely across conflict domains, with consensus gain showing significant differences between domains and no model achieving high resolution across all settings. Intervention timeliness does not correlate with effectiveness; some models intervene frequently but fail to improve outcomes, indicating that timing alone is insufficient for successful mediation. Mediators exhibit distinct adaptation profiles across socio-cognitive axes, with performance degrading differently depending on strategic, emotional, or cultural factors.
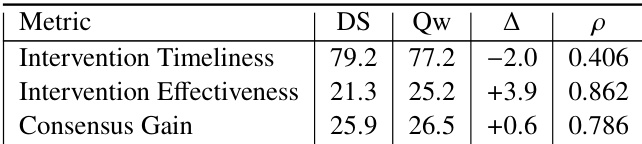
The authors evaluate the fidelity of persona simulation in SoCRATES by measuring how well different simulators maintain intended emotional reactivity levels across varying intensity scales. Results show that DeepSeek-V3.2 achieves the highest alignment with human judgments, indicating the most reliable translation of float-valued persona parameters into behavioral outcomes. DeepSeek-V3.2 demonstrates the highest simulation fidelity among the tested simulators. The evaluation reveals a clear hierarchy in how well different simulators preserve intended persona intensity levels. Human annotator agreement supports the reliability of the observed differences in simulation fidelity.

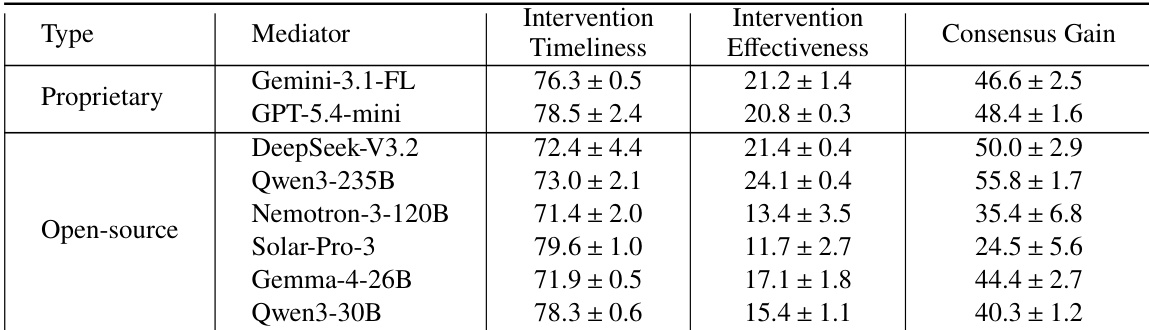
The authors evaluate eight LLM mediators across three metrics: intervention timeliness, intervention effectiveness, and consensus gain. Results show that proprietary models achieve higher consensus gain than open-source models, with the best-performing open-source model still falling short of the top proprietary mediator. Intervention timeliness does not correlate with consensus gain, as some models intervene frequently but with low effectiveness. The performance gap between models is consistent across different conflict domains and socio-cognitive conditions, indicating that effective mediation requires adaptation rather than uniform capability. Proprietary models achieve higher consensus gain than open-source models, with the top proprietary mediator outperforming the best open-source model. Intervention timeliness does not predict consensus gain, as models that intervene earlier or more frequently do not necessarily achieve better outcomes. Mediator performance varies significantly across conflict domains and socio-cognitive axes, highlighting the need for adaptive strategies rather than uniform mediation approaches.
The experiments evaluate LLM mediators across diverse conflict domains and socio-cognitive conditions while separately assessing persona simulation fidelity across varying emotional intensity scales. Results indicate that successful mediation relies on context-aware adaptation rather than frequent or early interventions, with performance varying substantially across conflict types and proprietary models generally achieving higher consensus than open-source alternatives. Additionally, the simulation fidelity assessment validates a clear hierarchy in behavioral translation capabilities, demonstrating that DeepSeek-V3.2 most reliably preserves intended persona parameters according to human judgment.