Command Palette
Search for a command to run...
Perception ou préjugé : les MLLMs peuvent-ils aller au-delà des premières impressions de personnalité ?
Perception ou préjugé : les MLLMs peuvent-ils aller au-delà des premières impressions de personnalité ?
Résumé
Les modèles de langage multimodaux à grande échelle (MLLM) sont de plus en plus déployés dans des rôles en interaction directe avec les humains, où la perception de la personnalité est cruciale. Pourtant, les benchmarks existants évaluent cette capacité uniquement par la prédiction numérique des scores du Big Five, laissant ouverte la question de savoir si les modèles perçoivent véritablement la personnalité par la compréhension comportementale ou s’ils se contentent de préjugés fondés sur la reconnaissance de motifs superficiels. Nous comblons cette lacune grâce à trois contributions. (i) Une nouvelle tâche : nous formalisons le Raisonnement ancré sur la personnalité (Grounded Personality Reasoning, GPR), qui exige des MLLM qu’ils ancrent chaque évaluation du Big Five dans des preuves observables, à travers une chaîne d’évaluation, de raisonnement et d’ancrage. (ii) Un nouvel ensemble de données : nous publions MM-OCEAN (1 104 vidéos, 5 320 questions à choix multiples), produit par un pipeline multi-agent avec vérification humaine, incluant des observations comportementales horodatées, des analyses de traits ancrées dans les preuves, et sept catégories de questions à choix multiples ancrées sur des indices. (iii) Benchmark et analyse : nous concevons une évaluation à trois niveaux (évaluation, raisonnement, ancrage) ainsi que quatre métriques de modes d’échec au niveau des échantillons : Taux de préjugé (PR), Taux de confabulation (CR), Taux d’échec d’intégration (IR) et Taux d’ancrage holistique (HR), et nous évaluons 27 MLLM (13 fermés, 14 ouverts). L’analyse met en évidence un écart de préjugé frappant : à l’échelle du domaine, 51 % des évaluations correctes ne sont pas ancrées dans les indices récupérés, et le Taux d’ancrage holistique varie de 0 à 33,5 %. Ces résultats révèlent une déconnexion entre l’obtention du bon score et la formulation d’un raisonnement fondé sur les bonnes raisons, traçant une feuille de route pour une cognition sociale ancrée dans les MLLM.
One-sentence Summary
This study introduces Grounded Personality Reasoning (GPR) and the MM-OCEAN dataset of 1,104 videos and 5,320 multiple-choice questions to shift multimodal large language model evaluation from superficial Big Five score prediction to a three-tier evaluation that benchmarks 27 models on evidence-anchored trait analysis, ultimately exposing a prejudice gap wherein 51 percent of accurate personality ratings lack observable behavioral justification.
Key Contributions
- Formalize Grounded Personality Reasoning (GPR), a task requiring models to anchor Big Five trait predictions in observable behavioral evidence through a structured rating, reasoning, and grounding chain. This approach explicitly distinguishes genuine psychological perception from superficial pattern matching by moving beyond numerical score prediction.
- Introduce MM-OCEAN, a dataset comprising 1,104 videos and 5,320 multiple-choice questions generated via a human-verified multi-agent pipeline. The resource supplies timestamped behavioral observations, evidence-grounded trait analyses, and seven categories of cue-grounding questions for detailed assessment.
- Establish a three-tier evaluation framework with four sample-level failure-mode metrics (Prejudice, Confabulation, Integration-failure, and Holistic-grounding rates) and benchmark 27 multimodal large language models (13 closed, 14 open) across rating, reasoning, and grounding stages. Analysis reveals a Prejudice Gap where 51% of correct ratings lack grounded cue retrieval and Holistic-grounding rates span only 0–33.5%.
Introduction
Multimodal Large Language Models are rapidly entering high-stakes human-facing applications like AI interview screening and mental health triage, where accurately perceiving personality traits is essential for system trustworthiness and regulatory compliance. Prior benchmarks, however, frame this capability as a simple numerical regression task, which allows models to achieve correct scores through superficial pattern matching rather than genuine behavioral understanding. The authors formalize Grounded Personality Reasoning to address this limitation, requiring models to anchor trait predictions in observable multimodal evidence through a structured rating, reasoning, and grounding pipeline. They support this framework with the MM-OCEAN dataset and a multi-tier evaluation system that exposes a widespread prejudice gap, revealing that most current models predict traits correctly without actually understanding the underlying behavioral cues.
Dataset

-
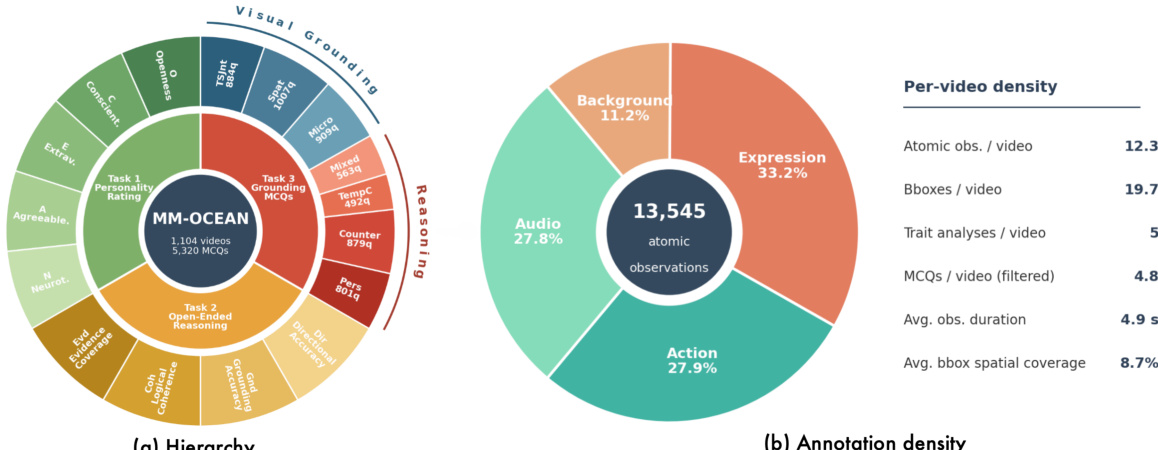
Dataset Source and Composition: The authors construct MM-OCEAN by selecting 1,104 test videos from the ChaLearn First Impressions V2 dataset, which provides approximately 10,000 fifteen-second clips of single-person speech along with crowd-sourced Big Five personality scores and automatic speech recognition transcriptions.
-
Atomic Behavioral Observations: The benchmark includes roughly 13,500 human-verified atomic cues categorized into four perceptual channels: Expression, Action, Audio, and Background. Each observation carries a unique identifier, frame-accurate timestamps, tight bounding boxes for visual events, factual descriptions, and body-part labels.
-
Trait-Level Analyses: The dataset contains 5,520 structured personality analyses that discretize the original continuous Big Five scores into five ordinal levels. Each analysis provides a trait assessment, a confidence-weighted rationale, and a reasoning chain that explicitly cites specific behavioral cue identifiers as evidence.
-
Cue-Grounding Questions: The release features 5,320 multiple-choice questions, averaging 4.8 per video, designed to test seven categories of social cognition such as personality attribution, counterfactual reasoning, and spatial-temporal grounding. Each question presents six options with distractors tailored to probe specific failure modes including text derivation and near-miss errors.
-
Annotation Pipeline and Filtering: Data construction utilizes a five-stage multi-agent pipeline that interleaves LLM agents with human verification. An Observer agent drafts initial cues that 24 human annotators review, correct, or delete while refining spatial-temporal annotations. An Aligner agent performs automated quality assurance, and a final text-leakage filter discards any question that two text-only language models can answer correctly using only the transcript, ensuring all retained items require multimodal grounding.
-
Metadata and Cropping Strategy: Annotators draw tight bounding boxes and snap start and end timestamps to the closest perceptually meaningful frames for all retained Expression and Action observations. The metadata enforces strict grounding constraints, requiring that personality analyses reference valid cue IDs and that questions utilize exact timestamp anchors and bounding box coordinates from the verified annotation pool.
-
Intended Usage: The authors employ this dataset exclusively as a held-out evaluation benchmark to assess the ability of multimodal models to ground personality judgments in observable behavioral evidence. The resource is intended for academic research on grounded reasoning, and the authors explicitly discourage its use for automated personality screening or hiring applications without explicit consent and fairness audits.
Method
The authors design MM-OCEAN as a multi-stage framework for grounded personality reasoning, structured around three core tasks that progressively evaluate a model's ability to reason about personality traits from multimodal video data. The overall process begins with the input of a video sequence V=(Vvis,Vaud,Vtxt), which includes visual frames, audio, and speech transcription, and proceeds through a pipeline that generates personality ratings, open-ended reasoning, and structured cue grounding. The framework is built upon a human-collaborative annotation process that ensures high-quality, evidence-grounded outputs.
The first stage, Atomic-Cue Annotation, involves an Observer and an Annotator who identify and label atomic perceptual cues from the video. These cues are categorized into four dimensions: Expression, Action, Audio, and Background, each annotated with start and end timestamps, a textual description, and, where applicable, bounding-box coordinates. This stage produces a set of atomic observations, which are then used in subsequent reasoning tasks. The annotations are refined through a filtering and expert review process, where a text-only large language model (LLM) evaluates the quality of the generated multiple-choice questions (MCQs), and expert human annotators review the rationales and MCQs to ensure coherence and grounding.
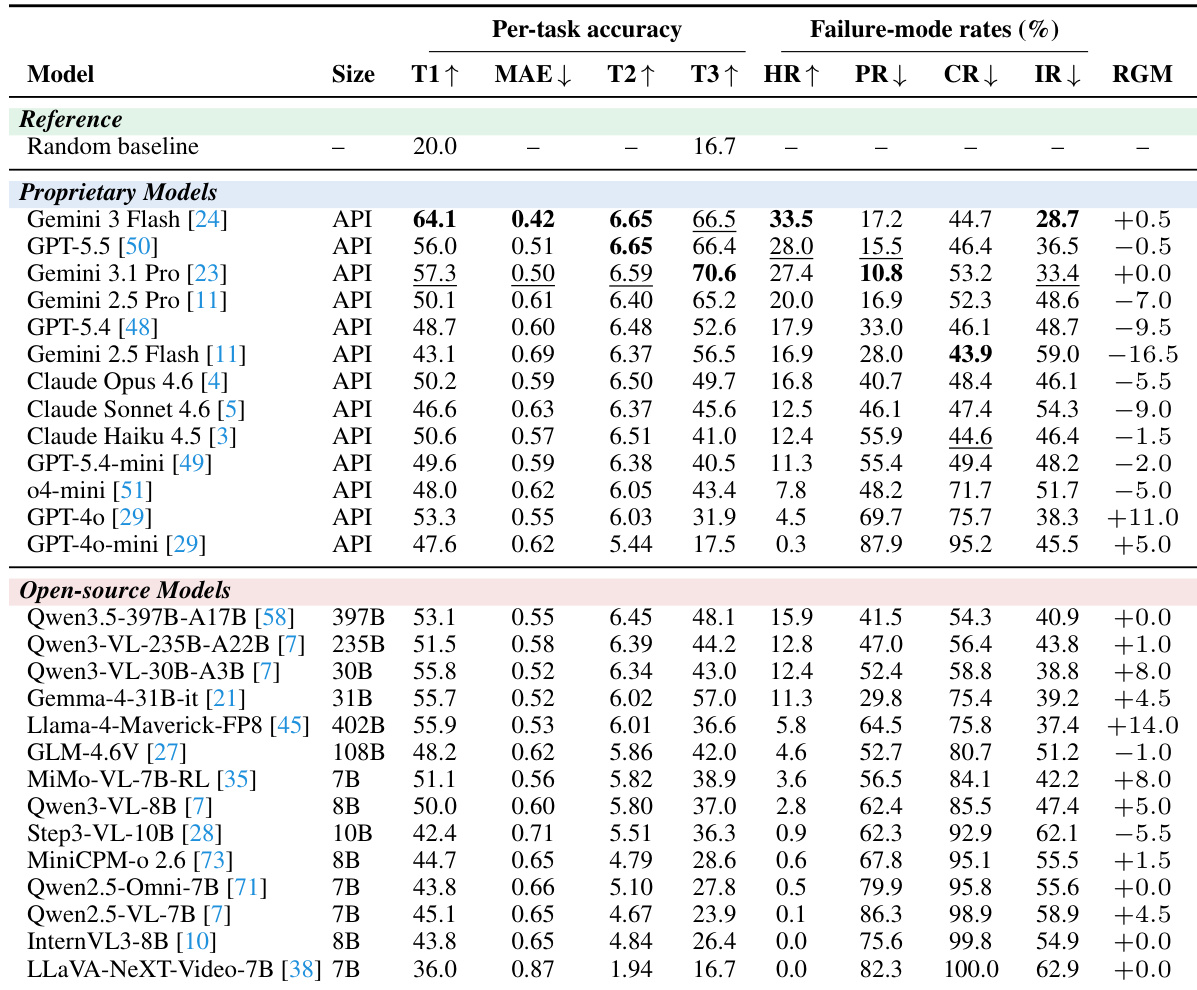
As shown in the figure below, the seven cue-grounding MCQ categories are organized into two clusters: Reasoning, which involves semantic and causal inference, and Visual Grounding, which focuses on pixel- and time-level localization. These categories are systematically applied across the three tasks to ensure a comprehensive evaluation of the model's reasoning capabilities.
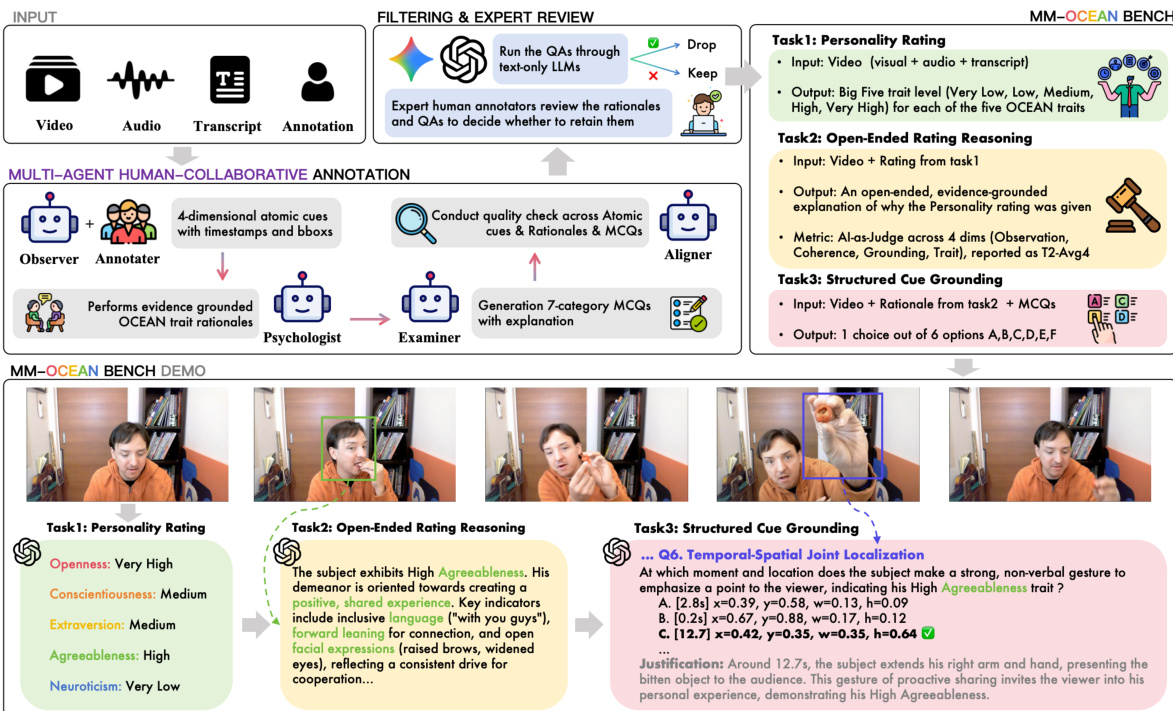
The second stage, Trait Reasoning, involves a Psychologist agent that generates open-ended explanations for the personality ratings. This agent uses the atomic observations to produce a rationale for each of the five Big Five traits, ensuring that the reasoning is grounded in the observed cues. The third stage, MCQ Generation, involves an Examiner agent that creates multiple-choice questions based on the reasoning and observations, with a focus on ensuring that the questions are logically consistent and aligned with the observed data. The final stage, Quality Assurance, involves an Aligner agent that performs a quality check across the atomic cues, rationales, and MCQs to ensure that the outputs are coherent and accurate.
The framework is designed to evaluate models across three distinct tasks: Task 1 (Personality Rating), which requires predicting the Big Five trait levels; Task 2 (Open-Ended Rating Reasoning), which requires generating a grounded explanation for the rating; and Task 3 (Structured Cue Grounding), which requires selecting the correct option from a set of multiple-choice questions based on the video and rationale. Each task is designed to assess a different aspect of the model's reasoning capabilities, with a focus on ensuring that the predictions are grounded in the observed data.

The atomic observations are distributed across the four perceptual channels, with a significant density in expression and action observations, as shown in the figure below. The annotation density is further detailed in the per-video statistics, which indicate that each video contains an average of 13,545 atomic observations, with a high proportion of expression and action observations. This distribution reflects the importance of visual and auditory cues in personality reasoning, and the framework is designed to capture and leverage these cues effectively.
Experiment
The MM-OCEAN benchmark evaluates twenty-seven multimodal large language models across three progressively complex tasks that validate basic personality prediction, the coherence of open-ended explanations, and the precise localization of behavioral evidence. This multi-task framework exposes a pervasive prejudice gap where the majority of correct ratings lack verifiable grounding, demonstrating that traditional rating-focused assessments systematically overestimate model competence. While proprietary and open-source systems perform comparably on initial predictions and verbal reasoning, a substantial divide emerges in fine-grained spatiotemporal cue retrieval. Ultimately, holistic grounding metrics effectively differentiate model reasoning patterns and indicate that prioritizing evidence-based post-training is essential for developing trustworthy personality-aware AI.
{"summary": "The experiment evaluates 27 multimodal models across three tasks: ordinal personality rating, open-ended reasoning, and structured cue grounding. Results show that while models perform similarly on rating and reasoning, a significant gap exists in cue retrieval, with proprietary models outperforming open-source ones. The evaluation reveals a widespread Prejudice Gap, where many correct ratings lack grounded evidence, highlighting the need for more reliable grounding in personality reasoning.", "highlights": ["Proprietary models show a substantial advantage in cue retrieval compared to open-source models, while performance is similar on rating and reasoning tasks.", "A significant Prejudice Gap exists across all models, with many correct ratings lacking grounded evidence, indicating a need for improved grounding in personality reasoning.", "The evaluation identifies a strong disconnect between rating success and trustworthy reasoning, with some models excelling in rating but failing in grounding, and vice versa."]
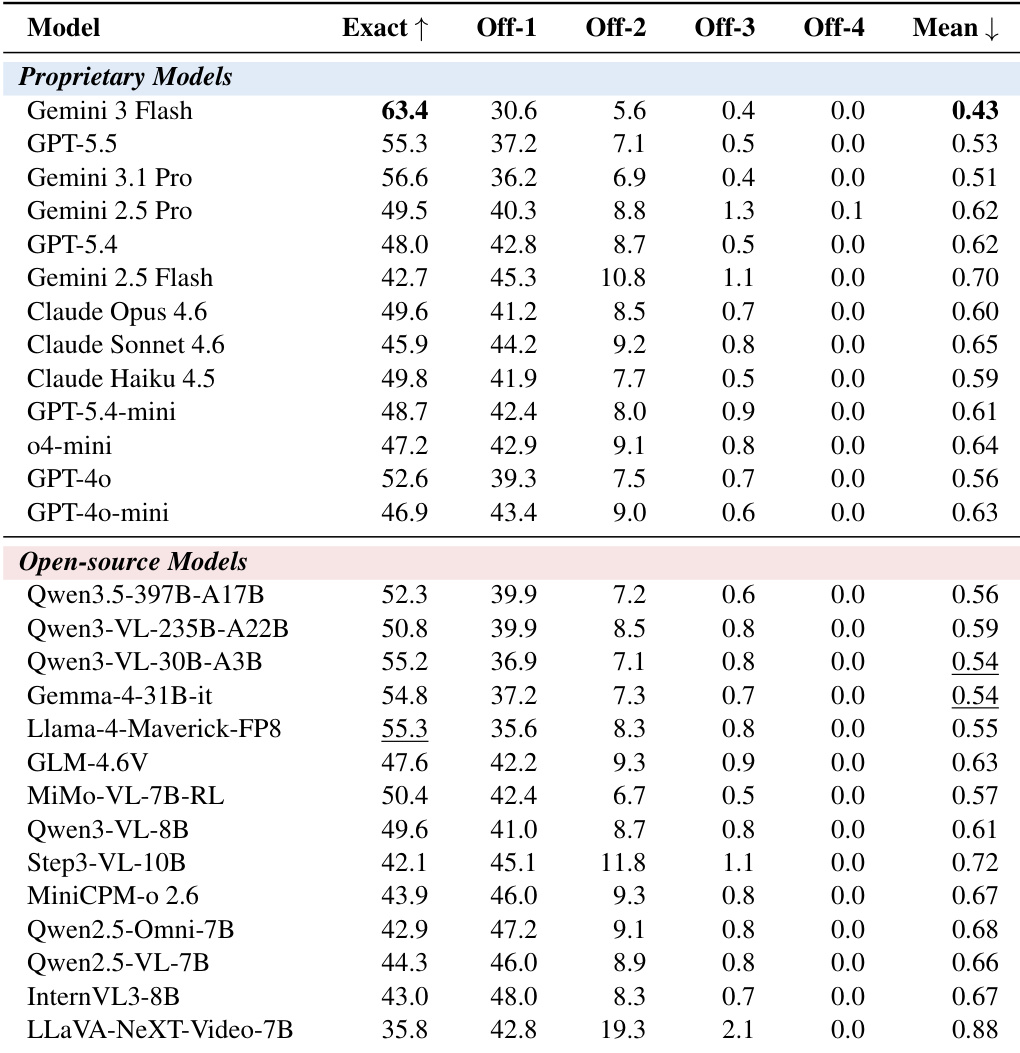
The authors evaluate 27 multimodal language models across three tasks assessing personality rating, reasoning, and cue grounding, revealing a widespread Prejudice Gap where many correct ratings lack grounded evidence. The results show that while models perform similarly on rating and explanation tasks, a significant performance gap exists in cue retrieval, with proprietary models outperforming open-source ones. Holistic-Grounding Rate emerges as a highly discriminative metric that exposes differences in trustworthy reasoning beyond individual task accuracy. Models exhibit a pervasive Prejudice Gap where a majority of correct personality ratings lack grounded evidence. Proprietary models significantly outperform open-source models in cue retrieval, but not in rating or reasoning tasks. Holistic-Grounding Rate is a highly discriminative metric that reveals model differences more effectively than individual task scores.
The experiment evaluates 27 multimodal models across three tasks assessing personality rating, reasoning, and cue grounding, revealing a widespread Prejudice Gap where most correct ratings lack grounded evidence. The evaluation highlights a significant disparity between proprietary and open-source models in cue retrieval, with the former outperforming the latter by a large margin. Holistic-Grounding Rate emerges as a highly discriminative metric that identifies models capable of trustworthy reasoning, exposing performance gaps not evident in traditional rating-only evaluations. A pervasive Prejudice Gap exists, with over half of correct personality ratings lacking grounded evidence. Proprietary models significantly outperform open-source models in cue retrieval, while performance is similar in rating and reasoning tasks. Holistic-Grounding Rate effectively distinguishes models by revealing those that combine accurate ratings with grounded reasoning.
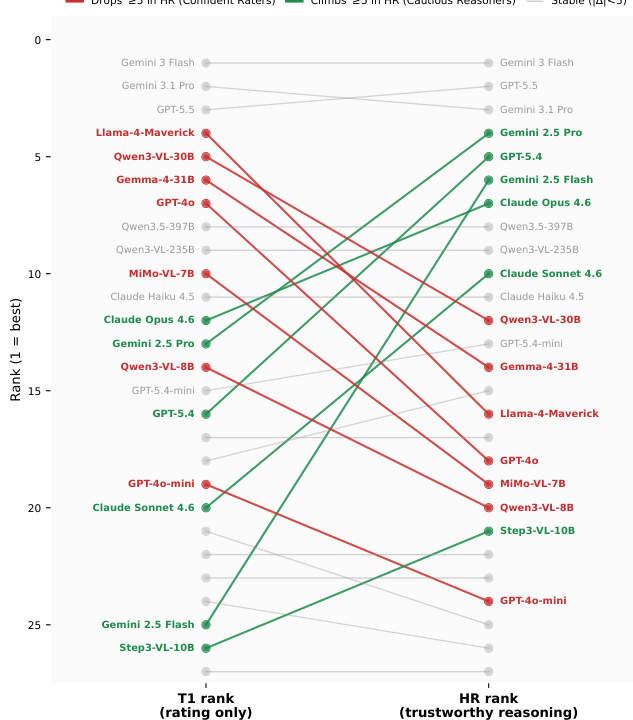
The authors evaluate the robustness of the AI-as-Judge protocol by comparing its rankings across different judge models and assessing consistency in performance. Results show high Spearman correlations between the primary judge and alternative judges, indicating stable and reliable evaluations. The within-family check reveals minor calibration shifts but no significant disruption to the relative ranking of models. High rank correlation between the primary judge and alternative judges indicates robust and stable evaluation results. The AI-as-Judge protocol shows consistent performance across different judge families, with minimal impact on model rankings. Minor calibration differences exist between judges, but these do not affect the relative ranking of models.

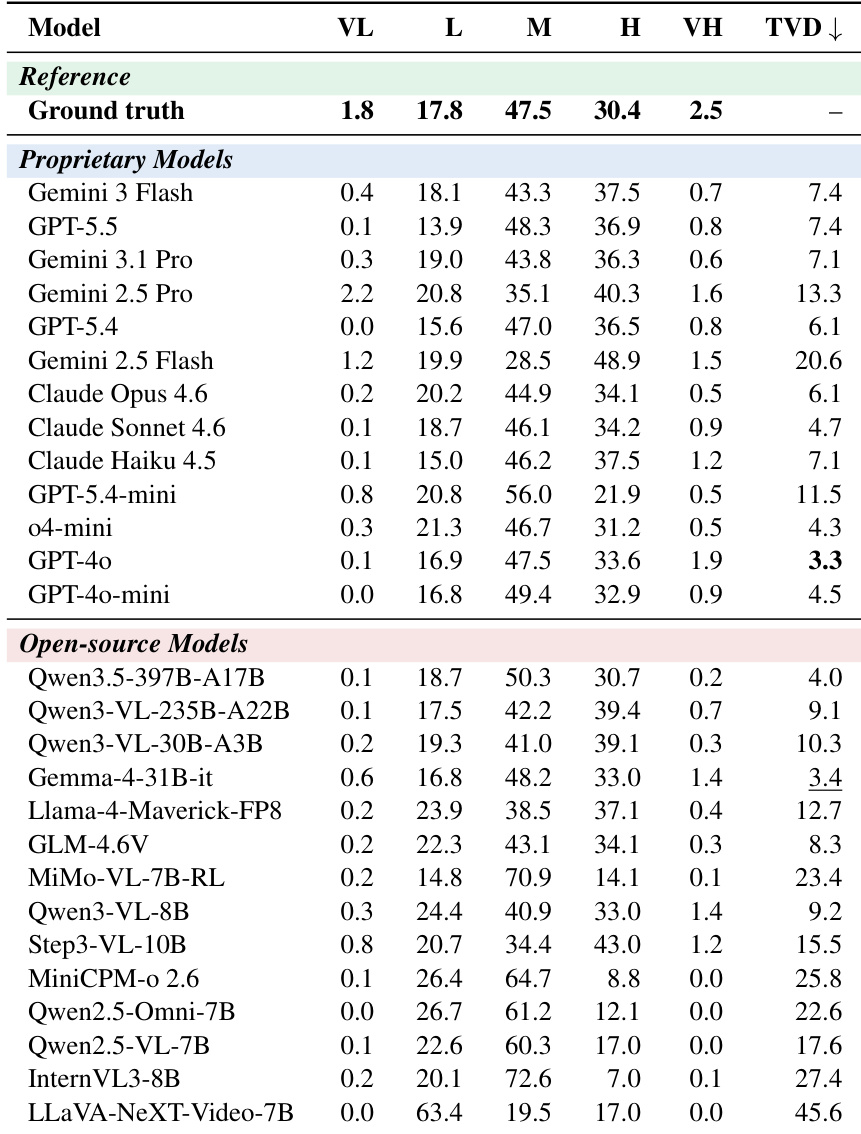
The the the table presents a comparison of model performance across different personality traits and prediction distributions, highlighting the gap between proprietary and open-source models. Proprietary models generally show higher accuracy in predicting specific traits, while open-source models exhibit higher variability and lower confidence in their predictions, particularly in the Very Low and Very High categories. The Total Variation Distance (TVD) indicates how closely model predictions align with ground truth, with lower values suggesting better alignment. Proprietary models demonstrate higher accuracy in predicting personality traits compared to open-source models. Open-source models show greater variability in predictions, especially in the Very Low and Very High categories. The Total Variation Distance (TVD) reflects the alignment between model predictions and ground truth, with lower values indicating better performance.
The evaluation assesses twenty-seven multimodal models across personality rating, reasoning, and cue grounding tasks, while a separate validation confirms the stability of the AI-as-Judge protocol. The primary experiments reveal a pervasive disconnect between accurate personality ratings and trustworthy reasoning, as most correct predictions lack properly grounded evidence. They also demonstrate that proprietary models hold a clear advantage in cue retrieval and prediction consistency, whereas open-source systems exhibit greater variability. Finally, the holistic grounding metric successfully isolates models capable of reliable reasoning, and the evaluation framework proves robust across different judge implementations without altering relative rankings.