Command Palette
Search for a command to run...
ACC : Compilation des trajectoires d'agents pour l'entraînement à long contexte
ACC : Compilation des trajectoires d'agents pour l'entraînement à long contexte
Résumé
Le développement récent des agents a ravivé la demande pour une capacité de raisonnement sur de longs contextes des grands modèles de langage (LLM). Cependant, l’entraînement des LLM pour cette capacité nécessite une curation coûteuse de longs documents ou une synthèse heuristique du contexte. Nous observons que les agents produisent des trajectoires massives lors de la résolution de problèmes, en invoquant des outils et en recevant des observations de l’environnement sur de nombreux tours. Les éléments de preuve nécessaires pour répondre à la question initiale sont ainsi dispersés tout au long de ces tours, ce qui exige l’intégration de segments de contexte distants. Néanmoins, l’ajustement fin supervisé (SFT) standard des agents masque les réponses des outils et n’entraîne que la sélection d’outils au niveau du tour, créant un angle mort de supervision où ces signaux épars ne sont pas exploités. Nous proposons la Compilation de Contexte des Agents (ACC), qui convertit les trajectoires issues d’agents de recherche, d’ingénierie logicielle et d’interrogation de bases de données en paires de questions-réponses sur longs contextes, combinant la question initiale avec les réponses des outils et les observations de l’environnement recueillies sur plusieurs tours, entraînant le modèle à répondre directement sans utilisation d’outils. Cela rend explicites les dépendances entre la question et les éléments de preuve, permettant une supervision directe du raisonnement sur longs contextes portant sur des segments distants, sans annotation supplémentaire. L’ACC est une approche simple mais efficace qui peut être combinée avec n’importe quelle méthode existante d’extension ou d’entraînement sur longs contextes, fournissant des données d’ajustement fin supervisé évolutives. Nous validons l’ACC sur des tâches de modélisation des dépendances à longue portée à travers MRCR et GraphWalks, des benchmarks exigeants nécessitant une résolution de coréférence inter-tours et une traversal de graphes sur des contextes étendus. L’entraînement de Qwen3-30B-A3B avec l’ACC atteint 68,3 sur MRCR (+18,1) et 77,5 sur GraphWalks (+7,6), des résultats comparables à ceux de Qwen3-235B-A22B, tout en préservant les capacités générales sur GPQA, MMLU-Pro, AIME et IFEval. Une analyse approfondie des mécanismes révèle que le modèle entraîné avec l’ACC présente une restructuration adaptative de l’attention spécifique à la tâche et une spécialisation des experts.
One-sentence Summary
Agent Context Compilation (ACC) converts multi-turn agent trajectories into long-context QA pairs that integrate scattered tool responses and environmental observations across turns, enabling scalable supervised fine-tuning with direct supervision over distant context segments without requiring additional annotation or tool use.
Key Contributions
- Agent Context Compilation (ACC) converts multi-turn trajectories from search, software engineering, and database querying agents into long-context question-answering pairs. This process aggregates scattered tool responses and environment observations to explicitly link distant evidence to original queries, enabling direct supervised fine-tuning without manual annotation.
- Fine-tuning Qwen3-30B-A3B with ACC achieves 68.3 on MRCR and 77.5 on GraphWalks, matching the performance of Qwen3-235B-A22B while preserving general capabilities on GPQA, MMLU-Pro, AIME, and IFEval.
- Mechanistic analysis reveals that ACC training induces task-adaptive attention restructuring and expert specialization, demonstrating that long-range reasoning capacity emerges as flexible, context-specific attention patterns.
Introduction
The rapid adoption of AI agents has intensified the need for large language models to reason effectively over extended contexts, since agents typically gather scattered evidence across dozens of tool calls and environment observations. Prior approaches to building this capability rely on expensive long-document curation, heuristic synthesis, or complex post-training pipelines, while standard agent fine-tuning masks intermediate tool responses and only supervises turn-level decisions. This creates a supervision blind spot that leaves valuable cross-turn signals unused. The authors leverage these overlooked agent trajectories by introducing Agent Context Compilation (ACC), a method that converts multi-turn interactions into long-context question-answering pairs. By explicitly aligning the original query with the full sequence of tool responses and observations, ACC enables direct supervised fine-tuning for long-range reasoning without additional annotation, significantly boosting performance on cross-turn dependency benchmarks while maintaining general model capabilities.
Dataset

-
Dataset Composition and Sources: The authors compile the ACC dataset from autonomous agent trajectories spanning three operational domains: web search, software engineering, and SQL database querying.
-
Subset Details and Filtering Rules: The final collection contains 10,802 verified trajectories, broken down into 3,369 search samples, 4,368 software engineering samples, and 3,065 SQL samples. Answer verification pass rates differ across domains, stabilizing near 100% for search, 50% for SQL, and 10% for software engineering. Each sample features a compiled context ranging from 2,000 to 128,000 tokens, with length distributions deliberately aligned to each agent type.
-
Processing and Context Construction: For every trajectory, the authors extract self-contained evidence pieces sufficient to answer the original query without further tool use. Search agents yield full text from visited pages alongside unvisited results as distractors. Software engineering agents provide files from the correct patch plus additional debugging context files. SQL agents include complete contents of all queried tables. To eliminate positional bias, the evidence pieces undergo a random permutation and are concatenated until reaching a strict token budget. Candidate reasoning traces are generated using DeepSeek-V3.2-Thinking and strictly filtered to retain only paths that successfully reach the ground truth answer. The final training format is structured as a triple containing the original question, the shuffled compiled context, and the verified reasoning trace.
-
Model Usage and Training Configuration: The authors apply the full compiled mixture for supervised fine-tuning the Qwen3-30B-A3B-Thinking base model. They leverage the entire collection without explicit train-validation splits, using the diverse token distributions and shuffled evidence to strengthen long-range dependency modeling and multi-hop reasoning capabilities across standard long-context benchmarks.
Method
The authors leverage a framework called Agent Context Compilation (ACC) to address the supervision blind spot inherent in standard agent Supervised Fine-Tuning (SFT). In conventional agent SFT, the training objective only supervises the model's reasoning and action tokens at each turn, while all tool responses (observations) are masked and excluded from the loss function. This creates a structural limitation where intermediate evidence gathered across multiple turns is not directly guided by the final answer supervision, leading to suboptimal integration of scattered information. The model learns to optimize local next-tool selection rather than synthesizing a coherent global answer.
To overcome this, ACC reformulates the training data by compiling the entire trajectory of an agent into a single long-context question-answer pair. As shown in the figure below, the process begins with an initial task and proceeds through a sequence of interactions involving LLM reasoning, tool use, and environment responses. Each interaction generates a tool response or environment context, which is collected and aggregated into a unified context C. This compiled context, along with the original question q, forms the input to a retrained model. The model is then trained to generate a reasoning trace r and final answer y directly from this long context, without any intermediate action supervision.
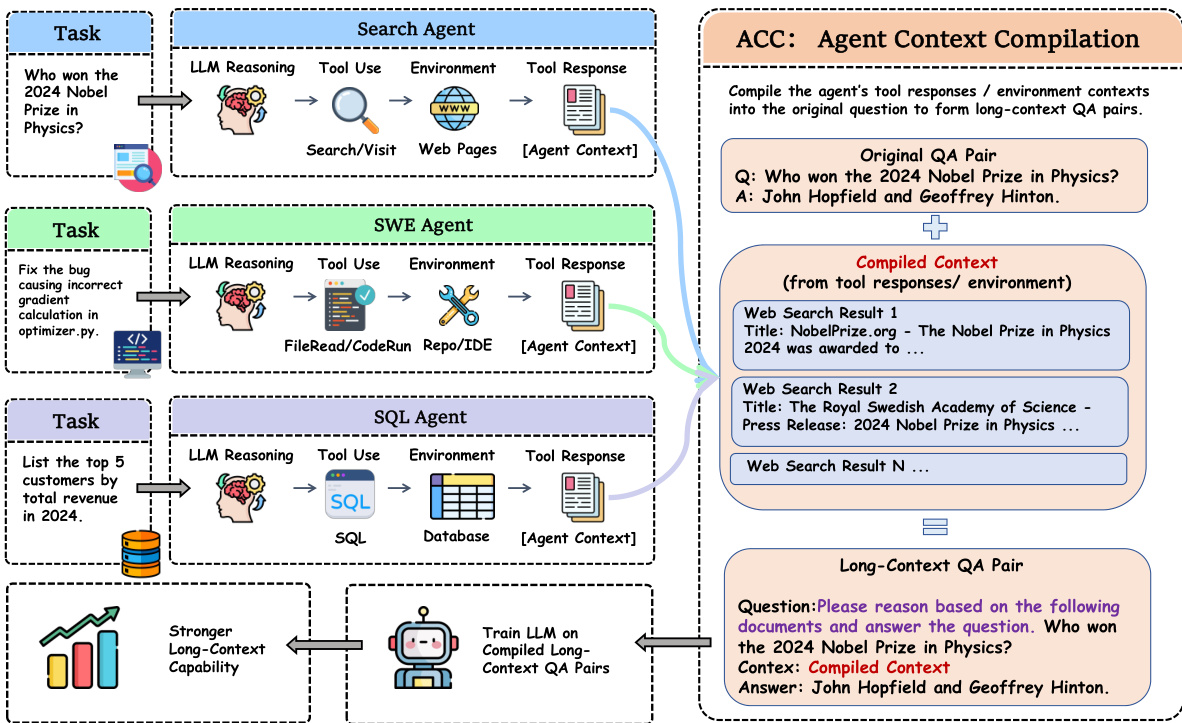
The training objective for ACC is defined as LACC=−∑j∈r∪ylogP(tokenj∣q,C,token<j). This objective directly supervises the generation of the final answer and reasoning trace from the compiled context, ensuring that the gradient for the final answer flows directly to every token in the context C, regardless of its position in the original trajectory. This eliminates the long-chain dependency problem present in standard SFT, where gradients from the final answer are heavily attenuated when propagating back to early-turn tool responses. By grouping all evidence into a single context, ACC enables the model to learn to integrate information across multiple turns and develop stronger long-context capabilities. The resulting dataset consists of compiled QA pairs (xi,yi,ri), where xi is the concatenation of the original query and the compiled context, and yi and ri are the final answer and reasoning trace from the original trajectory. This approach allows the model to learn a more holistic understanding of the task, directly connecting all evidence to the final output.
Experiment
The evaluation spans general capability benchmarks, comparative baselines, component ablations, and internal mechanism analysis to validate the model's long-context reasoning enhancements. Results confirm that the approach preserves general abilities without data leakage while outperforming complex multi-stage pipelines through standard supervised fine-tuning. Ablation studies further demonstrate that integrating diverse agent trajectories and strategic distractors provides complementary benefits for evidence localization and cross-domain reasoning. Finally, mechanistic analysis reveals that the training induces flexible, task-specific restructuring of attention spans and expert routing, confirming that the model adaptively optimizes its internal processing for long-range dependencies.
The authors evaluate their method, ACC, on general capability benchmarks and compare it to a strong baseline. Results show that ACC achieves slight improvements across most metrics while maintaining performance on others, indicating no significant degradation in general abilities. The model also outperforms the baseline on all evaluated tasks, with consistent gains observed in both the base and strong baseline settings. ACC achieves consistent improvements across multiple general capability benchmarks compared to the base model. The performance gains from ACC are stable and do not indicate negative transfer to general abilities. ACC outperforms the strong baseline across all evaluated tasks, demonstrating its effectiveness.
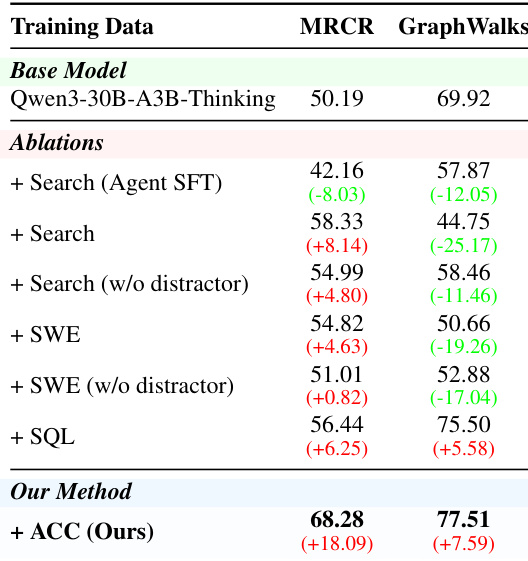
The authors present an ablation study comparing different training configurations against a base model and their proposed method. Results show that their method achieves the highest performance on both MRCR and GraphWalks, outperforming all individual agent-type variants and ablated versions. The full method demonstrates consistent improvements across both tasks, indicating that combining diverse trajectory types and retaining distractors enhances overall capability. The proposed method achieves the best performance on both MRCR and GraphWalks compared to all ablated variants. Training with individual agent types improves performance over the base model, but the full mixture outperforms all single-agent variants. Removing distractors negatively impacts MRCR performance, while it improves results on GraphWalks, suggesting task-specific benefits of distractors.
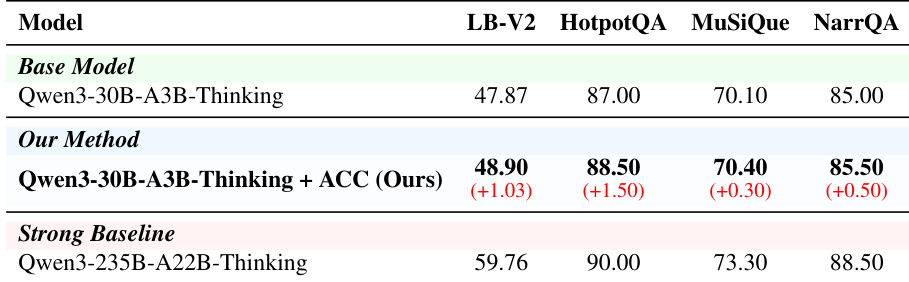
The authors evaluate their method against a base model on general capability benchmarks, showing improvements on most tasks with minimal degradation on others. Results indicate that the proposed approach enhances performance without introducing significant negative transfer, and the improvements are attributed to better reasoning rather than data leakage. The method achieves improvements on most general capability benchmarks while maintaining stability on others. The gains are attributed to improved reasoning rather than test-set leakage, as confirmed by semantic distribution analysis. The approach does not introduce noticeable degradation to general abilities, indicating effective preservation of baseline capabilities.

The authors compare their method with existing long-context post-training approaches, showing that their model achieves competitive performance on MRCR and GraphWalks. Results indicate that their approach outperforms several baselines, particularly in terms of long-context reasoning capabilities, while maintaining general capability preservation. The proposed method achieves higher performance on MRCR and GraphWalks compared to several existing long-context post-training methods. The model surpasses QwenLong-L1.5-30B and other LongRLVR variants in both MRCR and GraphWalks evaluations. The results demonstrate that the approach maintains strong long-context reasoning abilities while improving on key benchmarks.
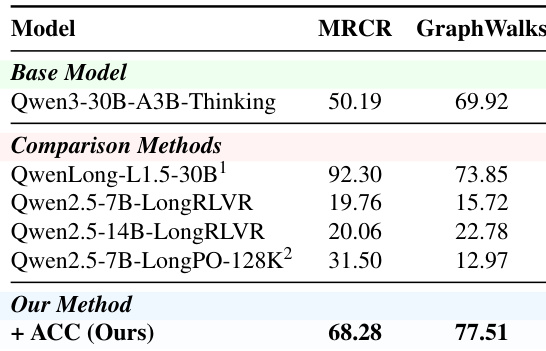
The authors compare their method, Qwen3-30B-A3B-Thinking + ACC, against several strong baselines on two tasks, MRCR and GraphWalks. Results show that their method achieves substantial improvements over the base model and outperforms all listed baselines on both tasks, with particularly large gains on MRCR and a significant overall improvement on GraphWalks. the method achieves the highest performance on both MRCR and GraphWalks compared to all listed baselines. The model shows the largest improvement on MRCR, with a significant boost in the 2-needle and 4-needle subtasks. On GraphWalks, the model achieves a substantial overall improvement, with notable gains in both Parents and BFS subtasks.
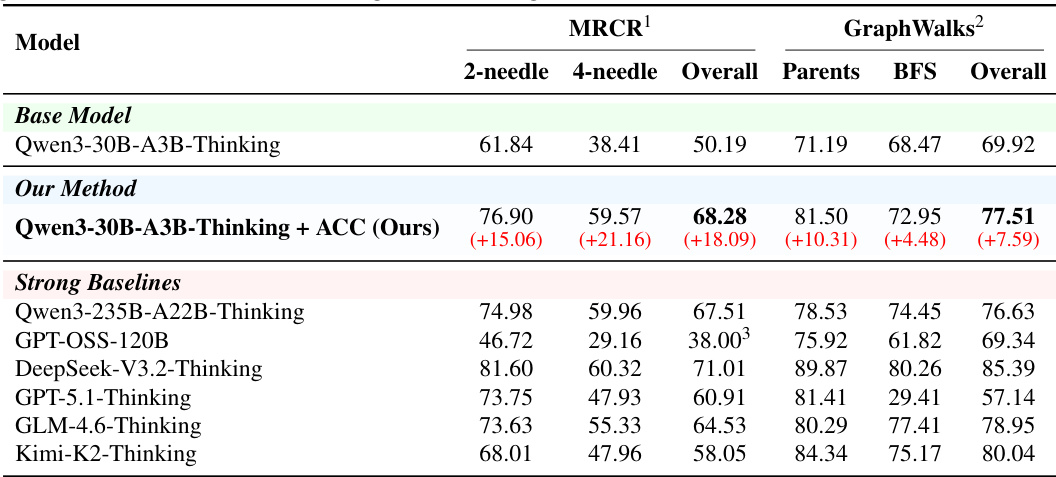
The proposed ACC method is evaluated against base models, strong baselines, ablated variants, and existing long-context approaches across general capability benchmarks and long-context reasoning tasks. The experiments validate that combining diverse training trajectories and retaining distractors consistently yields superior performance while preserving baseline capabilities. Analysis confirms that these gains stem from enhanced reasoning rather than data leakage, demonstrating the method's robustness across different configurations. Ultimately, the approach establishes a reliable framework for advancing long-context understanding without compromising general model competencies.