Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Déploiement en un clic de MinerU
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
MinerU is an open-source document content extraction solution that integrates PDF-Extract-Kit models with finely-tuned preprocessing and postprocessing rules to consistently deliver high-precision results across diverse document types, as validated by experimental evaluations demonstrating significantly improved extraction quality and consistency.
Key Contributions
- Introduces MinerU, an open-source framework for high-precision document content extraction that addresses the inconsistent performance of existing open-source solutions.
- Integrates PDF-Extract-Kit models with optimized preprocessing and postprocessing rules to accurately parse diverse document layouts and content types.
- Experimental evaluations across diverse document categories demonstrate that the framework consistently achieves high performance, delivering reliable and accurate content extraction results.
Introduction
Document content analysis remains a foundational computer vision task essential for converting complex papers, reports, and forms into structured, machine-readable formats. Despite significant progress in OCR, layout detection, and formula recognition, existing open-source tools consistently struggle to maintain high extraction quality across highly diverse document layouts. The authors introduce MinerU, an open-source framework that leverages the PDF-Extract-Kit models alongside optimized preprocessing and postprocessing pipelines to deliver reliable, high-precision content extraction across varying document structures. This approach significantly improves both the accuracy and consistency of automated document parsing while remaining fully accessible to the research community.
Dataset
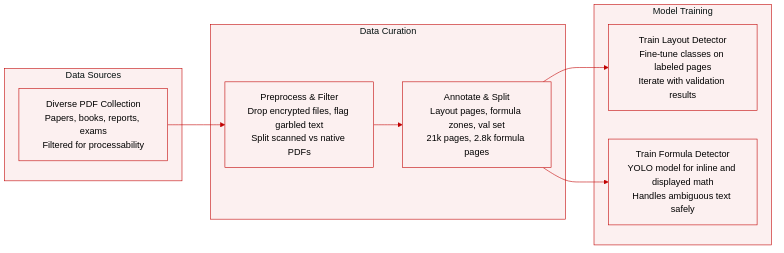
-
Dataset Composition and Sources: The authors compile a highly diverse collection of PDF documents spanning scientific papers, textbooks, exam papers, magazines, presentations, research reports, and financial reports. The initial ingestion pipeline strictly filters out non-PDF files, encrypted documents, and password-protected files to ensure processability.
-
Subset Details and Annotation:
- Layout Analysis Subset: Approximately 21,000 annotated pages covering titles, body paragraphs, images, tables, captions, notes, and discard elements like headers, footers, and page numbers.
- Formula Detection Subset: 2,890 pages extracted from Chinese and English papers, textbooks, and financial reports, containing 24,157 inline formulas and 1,829 displayed formulas. An ignore class captures ambiguous numerical or chemical text that cannot be reliably classified.
- Evaluation Subset: A curated collection of 11 document types designed to benchmark layout and formula detection performance across real-world scenarios.
-
Metadata Construction and Preprocessing: The pipeline extracts essential document metadata including total page count, page dimensions, and language identification, which is restricted to Chinese and English. The system automatically flags garbled text-based PDFs and classifies documents as scanned or native text based on the ratio of image area to text area and near-zero average page text length. Scanned documents trigger OCR, while native text documents bypass it.
-
Training Strategy and Usage: The authors employ an iterative data selection and model training loop. Initial visual clustering guides the sampling of diverse documents, and validation results dynamically adjust sampling weights to prioritize underperforming categories or sources. The layout subset fine-tunes existing detection architectures with customized class parameters, while the formula subset trains a YOLO-based detector optimized for speed and accuracy across varied document layouts.
Method
The authors leverage a multi-module document parsing strategy as the core technical approach in MinerU, designed to address the limitations of existing methods in handling diverse and complex document layouts. The overall framework consists of four sequential stages: document preprocessing, content parsing, content post-processing, and format conversion. As shown in the framework diagram, the process begins with document preprocessing, where PyMuPDF is used to read the input PDF, filter out unprocessable files such as encrypted documents, and extract metadata including parseability, language, and page dimensions. This stage ensures only valid documents proceed to the next phase.
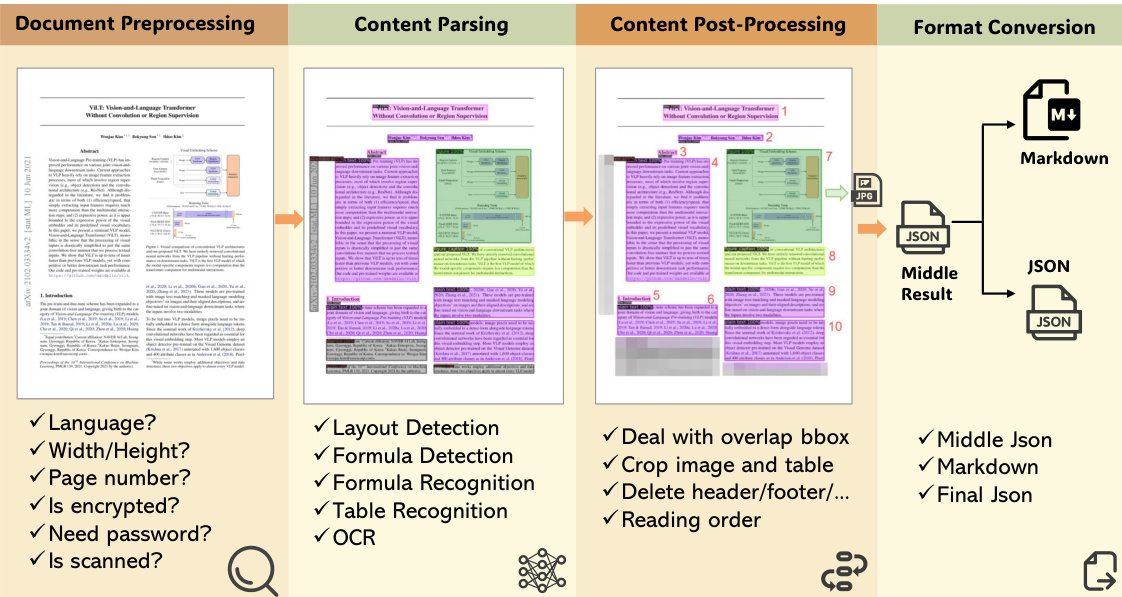
In the content parsing stage, MinerU employs the PDF-Extract-Kit, a library of state-of-the-art open-source models trained on diverse real-world documents. This stage initiates with layout analysis, which detects and classifies various regions including text, formulas, tables, and images. Following layout detection, specialized recognizers are applied to each region: OCR for text and titles, a self-developed UniMERNet model for formula recognition, and TableMaster and StructEqTable for table recognition. The UniMERNet model is trained on the UniMER-1M dataset and achieves performance comparable to commercial tools on various formula types. Table recognition is handled by both TableMaster, trained on PubTabNet, and StructEqTable, trained on DocGenome, with the latter offering end-to-end recognition for complex tables.

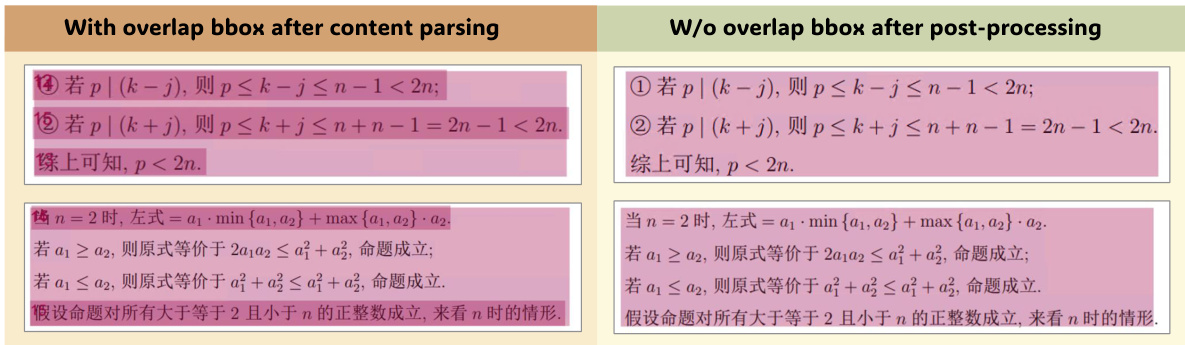
The content post-processing stage addresses the challenges of content ordering arising from overlapping and nested bounding boxes. This stage resolves containment and partial overlap relationships between different elements. For instance, formulas and text blocks contained within images or tables are removed, and partially overlapping text boxes are shrunk to avoid mutual coverage. To maintain reading order, a segmentation algorithm based on the human reading sequence "top to bottom, left to right" is applied, dividing the page into regions that contain at most one column. This ensures that elements are sorted according to their natural reading flow.
Finally, the format conversion stage transforms the processed data into user-requested formats. The intermediate structure, stored as a JSON file, holds the positioning, content, and sorting information for all document regions. From this structure, MinerU generates outputs such as Markdown and a custom JSON format. The system supports cropping of images and tables and ensures the correct reading order in the final output. The entire workflow is designed to handle diverse document types, including academic papers, textbooks, and reports, while maintaining high extraction quality and low inference costs.
Experiment
The evaluation assesses MinerU’s PDF extraction quality through both standalone module testing and end-to-end visualization across academic and diverse document types. Layout detection, formula detection, and formula recognition experiments validate that MinerU’s specialized models accurately localize regions, identify mathematical content, and transcribe formulas with robustness that matches or exceeds commercial alternatives. Subsequent post-processing and stitching steps further ensure the final Markdown outputs maintain high readability and structural accuracy. Collectively, these findings demonstrate that training on heterogeneous document sources significantly outperforms single-domain open-source models, delivering reliable and precise content extraction.
The authors evaluate the performance of their formula detection model against existing open-source models using two validation sets, one focused on academic papers and another on multi-source documents. Results show that their model achieves higher performance across both datasets compared to the baseline model. The proposed model outperforms the baseline model on both academic papers and multi-source validation sets. The model demonstrates consistent performance improvements across different types of document sources. The evaluation highlights the effectiveness of fine-tuning on diverse data for formula detection.

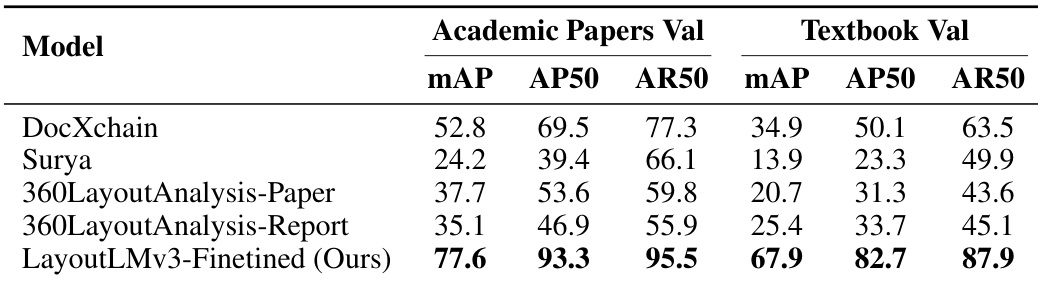
The authors evaluate the layout detection performance of MinerU's model compared to several open-source models using validation sets from academic papers and textbooks. The results show that the proposed model outperforms other models across multiple metrics on both datasets. The proposed model achieves the highest performance on both academic papers and textbook validation sets compared to other models. The model shows consistent improvements across different evaluation metrics, indicating robust performance. The results demonstrate that the fine-tuned model significantly outperforms existing open-source models in layout detection tasks.
The authors evaluate the formula recognition performance of MinerU's UniMERNNet model against other open-source models using multiple metrics. Results show that UniMERNNet significantly outperforms other models, particularly on the CDM metric, and achieves performance comparable to commercial tools. The evaluation demonstrates the effectiveness of training on diverse data for robust formula recognition. UniMERNNet outperforms other open-source models in formula recognition, especially on the CDM metric. UniMERNNet's performance is comparable to commercial software in formula recognition. The model achieves high recognition accuracy across diverse formula representations, as indicated by strong CDM scores.
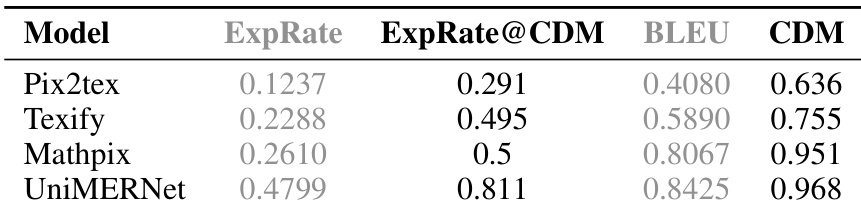
The authors evaluate their models for formula detection, layout detection, and formula recognition against open-source baselines and commercial tools using validation sets from academic papers, textbooks, and multi-source documents. The formula detection and layout detection experiments validate the models' robust generalization across diverse document structures, while the formula recognition task confirms the system's ability to achieve accuracy comparable to established commercial software. Collectively, these findings highlight the effectiveness of training on heterogeneous data and demonstrate consistent superiority over existing open-source alternatives.