Command Palette
Search for a command to run...
DeepSeek LLM : Mise à l'échelle des modèles de langage open-source avec le long-termisme
DeepSeek LLM : Mise à l'échelle des modèles de langage open-source avec le long-termisme
Déployez DeepSeek R1 avec Ollama et Open WebUI
Résumé
Le développement rapide des grands modèles de langage (LLM) open-source a été véritablement remarquable. Cependant, les lois d’échelle décrites dans la littérature antérieure présentent des conclusions variées, ce qui assombrit la perspective du passage à l’échelle des LLM. Nous approfondissons l’étude des lois d’échelle et présentons nos résultats distinctifs qui facilitent le passage à l’échelle de modèles de grande taille dans deux configurations open-source couramment utilisées, à savoir 7B et 67B. Guidés par ces lois d’échelle, nous introduisons DeepSeek LLM, un projet dédié à l’avancement des modèles de langage open-source dans une perspective à long terme. Pour soutenir la phase de pré-entraînement, nous avons développé un jeu de données qui compte actuellement 2 billions de tokens et qui est en constante expansion. Nous effectuons par ailleurs un ajustement fin supervisé (SFT) et une optimisation directe des préférences (DPO) sur les modèles DeepSeek LLM Base, ce qui aboutit à la création des modèles DeepSeek Chat. Nos résultats d’évaluation montrent que DeepSeek LLM 67B surpasse LLaMA-2 70B sur une série de benchmarks, en particulier dans les domaines du code, des mathématiques et du raisonnement. De plus, les évaluations ouvertes révèlent que notre DeepSeek LLM 67B Chat affiche des performances supérieures à celles de GPT-3.5.
One-sentence Summary
DeepSeek researchers introduce the open-source DeepSeek LLM family (7B and 67B), which leverages scaling laws and a 2-trillion-token corpus before undergoing supervised fine-tuning and direct preference optimization to produce DeepSeek Chat models that surpass LLaMA-2 70B on code, mathematics, and reasoning benchmarks and outperform GPT-3.5 in open-ended evaluations.
Key Contributions
- This work establishes a refined scaling law framework that replaces traditional parameter counts with non-embedding FLOPs per token to optimize compute allocation between model architecture and training data. The framework provides an empirical method for predicting near-optimal batch sizes and learning rates while accurately forecasting generalization loss for large-scale models.
- Analysis reveals that pre-training data quality directly dictates optimal compute allocation, with higher quality data justifying increased compute budgets for model scaling rather than data expansion. These insights guide the training of DeepSeek LLM variants from scratch on a continuously expanding dataset containing two trillion tokens of English and Chinese text.
- The study releases DeepSeek LLM 7B and 67B models, with the larger variant fine-tuned via supervised fine-tuning and direct preference optimization to produce the DeepSeek Chat series. Benchmarks demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B in code, mathematics, and reasoning tasks, while the aligned Chat variant exhibits superior open-ended generation performance compared to GPT-3.5.
Introduction
The rapid advancement of open-source large language models depends on efficiently distributing compute budgets across model size and training data to close the performance gap with proprietary systems. Prior scaling law research, however, has yielded conflicting conclusions about optimal compute allocation and frequently lacks complete hyperparameter documentation, creating uncertainty about how to reliably scale models to higher compute tiers. To resolve these inconsistencies, the authors recalibrate scaling laws by deriving empirical power-law relationships for batch size and learning rate relative to compute budgets and replacing parameter counts with a more precise metric based on non-embedding FLOPs per token. Leveraging these refined scaling principles, they train the DeepSeek LLM series on two trillion tokens and demonstrate that optimized hyperparameter scheduling, accurate compute allocation, and high-quality data collectively enable open-source models to surpass LLaMA-2 70B and GPT-3.5 across core reasoning, code, and conversational benchmarks.
Dataset
-
Dataset Composition and Sources: The authors construct a multilingual training corpus by combining Common Crawl (spanning 91 dumps), two versions of internal data (early and current in-house datasets), and OpenWebText2. The collection strategy references established practices from prior large-scale language model projects.
-
Subset Details and Filtering Rules:
- Common Crawl: Processed across 91 dumps with an aggressive cross-dump deduplication strategy that removes four times more duplicates than single-dump approaches.
- In-house Data: Undergoes multiple iterative refinement cycles. The current version exhibits higher quality than the early version due to more meticulous processing.
- OpenWebText2: Serves as the highest-quality subset, benefiting from a smaller scale and rigorous curation.
- Quality & Diversity Filters: Documents are evaluated using robust linguistic and semantic criteria to maximize information density. A remixing phase adjusts mixture ratios to correct data imbalances, deliberately increasing the proportion of underrepresented domains.
-
Data Usage and Training Configuration: The authors use the curated corpus for both model training and scaling law analysis. They iteratively adjust source proportions to measure how data quality influences compute allocation. Their analysis demonstrates that higher-quality data increases the model scaling exponent while decreasing the data scaling exponent, indicating that compute budgets should prioritize larger model sizes over increased data volume.
-
Processing and Tokenization Details: The pipeline employs a custom Byte-level Byte-Pair Encoding (BBPE) tokenizer. Pre-tokenization isolates newlines, punctuation, and CJK characters to prevent cross-category merging, while numbers are split into individual digits. The base vocabulary contains 100,000 tokens trained on approximately 24 GB of multilingual text, augmented with 15 special tokens. The final configured vocabulary size is set to 102,400 to maintain training efficiency and reserve capacity for future expansions.
Method
The authors leverage a transformer-based architecture for the DeepSeek LLM family, closely following the design principles of LLaMA (Touvron et al., 2023a,b), with a Pre-Norm structure and RMSNorm (Zhang and Sennrich, 2019) as the normalization function. The feed-forward network (FFN) employs SwiGLU (Shazeer, 2020) as the activation function, with an intermediate layer dimension set to 38dmodel. Positional encoding is implemented using Rotary Embedding (Su et al., 2024), which enhances the model’s ability to capture sequential relationships. For inference optimization, the 67B variant adopts Grouped-Query Attention (GQA) (Ainslie et al., 2023) instead of traditional Multi-Head Attention (MHA), reducing computational overhead while maintaining performance.
In terms of macro design, the DeepSeek LLM family exhibits distinct scaling choices. The 7B model consists of 30 layers, while the 67B model extends to 95 layers. This depth-based scaling strategy prioritizes model depth over widening the FFN intermediate layer, differing from common practices and aiming to improve performance. The detailed specifications of the model architectures are provided in Table 2.
To determine optimal scaling strategies, the authors derive a model scale representation based on non-embedding FLOPs per token, denoted as M. This metric accounts for the computational cost of attention operations without including vocabulary-related computations, offering a more accurate approximation of model scale compared to conventional measures such as non-embedding parameters N1 or total parameters N2. The formula for M is defined as:
6N1=72nlayerdmodel26N2=72nlayerdmodel2+6nvocabdmodelM=72nlayerdmodel2+12nlayerdmodellseqwhere nlayer is the number of layers, dmodel is the model width, nvocab is the vocabulary size, and lseq is the sequence length. The differences among these representations are quantitatively analyzed in Table 3, which highlights significant discrepancies between 6N1, 6N2, and M, particularly in smaller models.
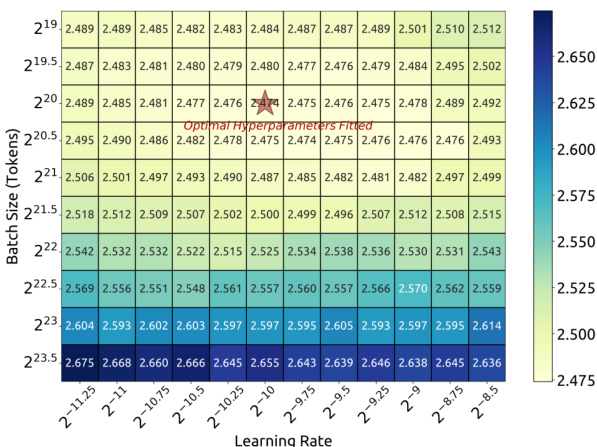
With M as the model scale, the objective becomes finding the optimal model scale Mopt and data scale Dopt that minimize generalization error under a fixed compute budget C=MD. To achieve this, the IsoFLOP profile approach from Chinchilla (Hoffmann et al., 2022) is used to fit scaling curves. Eight compute budgets ranging from 1e17 to 3e20 are selected, with approximately ten model/data scale allocations per budget. Hyperparameters are determined using Formula (1), and generalization error is evaluated on a validation set of 100 million tokens. The resulting optimal scaling exponents are:
Mopt=Mbase⋅Ca,Mbase=0.1715,a=0.5243Dopt=Dbase⋅Cb,Dbase=5.8316,b=0.4757Figure 4 illustrates the IsoFLOP curve and the fitted optimal model/data scaling curves, showing the relationship between compute budget and performance in terms of bits-per-byte on the validation set.
The performance scaling curve, shown in Figure 5, further validates the accuracy of the scaling predictions. The authors demonstrate that results from small-scale experiments can reliably predict the performance of models with up to 1000 times the compute budget, providing confidence for large-scale model training.
The alignment process consists of two stages. First, Supervised Fine-Tuning (SFT) is applied to the 7B and 67B models using approximately 1.5 million instruction data instances in English and Chinese, covering helpfulness and harmlessness topics. The helpful data includes 1.2 million instances, with distributions of 31.2% general language tasks, 46.6% mathematical problems, and 22.2% coding exercises, while the safety data comprises 300K instances covering sensitive topics. The 7B model is fine-tuned for 4 epochs, and the 67B model for 2 epochs, due to observed overfitting. Learning rates of 1e−5 and 5e−6 are used for the 7B and 67B models, respectively. During SFT, the authors monitor benchmark accuracy and repetition ratio, noting that increasing math SFT data can lead to higher repetition in weaker models. To mitigate this, two-stage fine-tuning and DPO (Rafailov et al., 2023) are employed, both reducing repetition without compromising benchmark performance.
For the second stage, Direct Preference Optimization (DPO) is applied to further enhance the model. Preference data is constructed based on helpfulness and harmlessness, using multilingual prompts covering creative writing, question answering, and instruction following. Responses are generated using DeepSeek Chat models as candidates. The DPO training proceeds for one epoch with a learning rate of 5e−6, batch size of 512, and a cosine learning rate scheduler with warmup. The results show that DPO strengthens open-ended generation capabilities with minimal impact on standard benchmark performance.
Experiment
The evaluation setup spans public bilingual benchmarks, open-ended generation tests, held-out real-world datasets, and expert-curated safety assessments to systematically validate the base and chat models across different scales. These experiments confirm that the multi-step training schedule and hyperparameter scaling laws are robust and predictable, while model scaling substantially improves reasoning, coding, and generalization to unseen tasks. Alignment procedures, including staged supervised fine-tuning and direct preference optimization, effectively enhance instruction following, conversational quality, and safety guardrails without degrading core knowledge. Collectively, the findings demonstrate that the proposed pipeline yields a highly capable, bilingual language model with advanced logical reasoning and reliable safety mechanisms that compete with top-tier proprietary systems.
The authors present a the the table detailing the architectural and training parameters for two model sizes, 7B and 67B, highlighting differences in their configurations. The results show that the larger model has more layers, a larger model dimension, and a greater number of attention heads, which are accompanied by a longer context length and a larger batch size, while both models were trained on the same number of tokens. The 67B model has significantly more layers, model dimension, and attention heads compared to the 7B model. The 67B model uses a longer context length and a larger batch size during training. Both models were trained on the same number of tokens, indicating a consistent training scale.

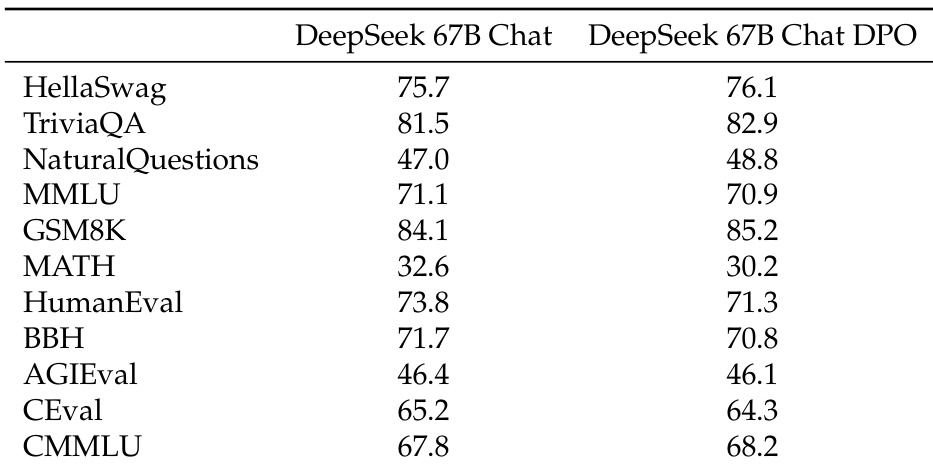
The the the table compares the performance of DeepSeek 67B Chat and DeepSeek 67B Chat DPO across various benchmarks, showing that the DPO stage leads to improvements in most tasks. The results indicate that the DPO model outperforms the base model on most evaluation metrics, with notable gains in math and reasoning tasks, while performance on some language understanding tasks remains stable or slightly decreases. The DPO stage improves performance on most benchmarks, particularly in math and reasoning tasks. The model shows consistent gains across multiple evaluation categories, with the DPO version achieving higher scores than the base model. Some tasks like TriviaQA and HellaSwag show minor performance declines after the DPO stage, indicating potential trade-offs in specific evaluation types.
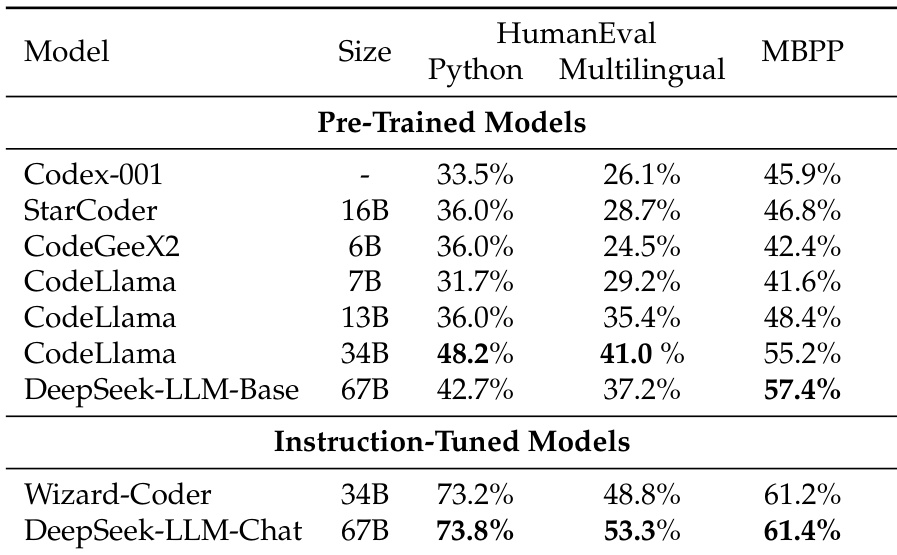
The the the table compares the performance of various pre-trained and instruction-tuned models on code-related tasks, showing that DeepSeek-LLM-Base and DeepSeek-LLM-Chat achieve competitive results, particularly in multilingual and MBPP benchmarks. The instruction-tuned model outperforms others in most categories, indicating the effectiveness of fine-tuning for code generation tasks. DeepSeek-LLM-Chat achieves the highest scores across all evaluated tasks compared to other instruction-tuned models. DeepSeek-LLM-Base shows strong performance in multilingual and MBPP benchmarks, outperforming several code-specific models. The instruction-tuned models generally achieve higher scores than pre-trained models, highlighting the benefits of fine-tuning for code generation tasks.
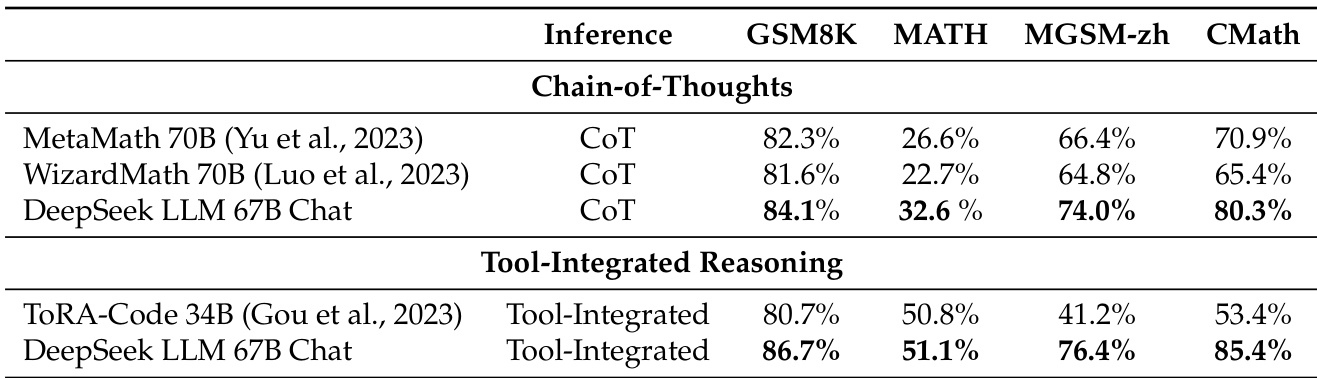
The the the table compares the performance of different models on math-related tasks using two reasoning methods: Chain-of-Thoughts and Tool-Integrated Reasoning. DeepSeek LLM 67B Chat achieves high scores in both methods, outperforming other models in several benchmarks, particularly in Tool-Integrated Reasoning where it shows significant improvements over ToRA-Code 34B. The results indicate that DeepSeek LLM 67B Chat is competitive with state-of-the-art models, especially in handling math problems through tool integration. DeepSeek LLM 67B Chat outperforms MetaMath 70B and WizardMath 70B in Chain-of-Thoughts on GSM8K and MATH benchmarks. DeepSeek LLM 67B Chat achieves the highest score in Tool-Integrated Reasoning on MGSZ-zh and CMath, surpassing ToRA-Code 34B. The model demonstrates strong performance in both reasoning methods, with notable improvements in Tool-Integrated Reasoning compared to other models.
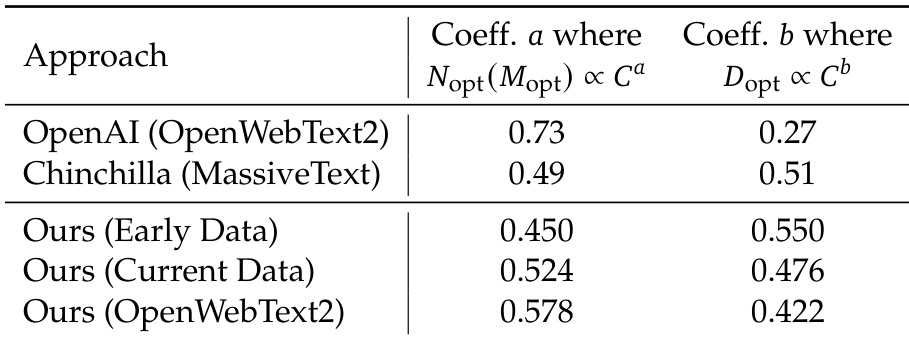
The authors compare their model's scaling behavior with existing approaches, showing that their current data and OpenWebText2-based approaches exhibit different scaling coefficients for optimal model size and data allocation relative to compute budget. The results indicate that their current data leads to a higher coefficient for model size scaling and a lower coefficient for data allocation scaling compared to OpenAI's approach. The authors' current data approach results in a higher scaling coefficient for optimal model size compared to OpenAI's approach. The authors' current data approach results in a lower scaling coefficient for optimal data allocation compared to OpenAI's approach. The OpenWebText2-based approach shows a higher scaling coefficient for data allocation than the current data approach.
The experiments evaluate architectural scaling, alignment fine-tuning, code generation, mathematical reasoning, and data allocation strategies to validate the model's performance across diverse domains. Scaling to larger parameters and applying direct preference optimization substantially enhance reasoning and alignment capabilities, while instruction tuning specifically validates the effectiveness of targeted fine-tuning for multilingual code tasks. The architecture also demonstrates superior proficiency in both standard and tool-augmented mathematical reasoning compared to existing systems. Finally, the training data strategy reveals distinct scaling behaviors that prioritize model size over data volume relative to compute, collectively confirming a highly efficient pathway for large language model development.