Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Génération de texte de niveau humain dans les transformateurs à l'aide de la recherche contrastive
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
An extensive evaluation of representation isotropy across sixteen languages reveals that anisotropy is restricted to specific English GPT-2-small and GPT-2-medium models, demonstrating that contrastive search decoding operates effectively without the representation calibration proposed in SimCTG.
Key Contributions
- Extensive evaluation of 38 off-the-shelf autoregressive language models across 16 languages demonstrates that isotropic representations are standard, with anisotropy restricted exclusively to English GPT-2-small and GPT-2-medium variants.
- Systematic assessment of contrastive search decoding across four generation tasks confirms that the method utilizes intrinsic representation geometry to generate high-quality text without requiring additional training.
- Comprehensive human and automatic evaluations establish that contrastive search significantly outperforms existing decoding strategies and achieves performance comparable to human annotators on 12 of the 16 tested languages.
Introduction
Autoregressive language models serve as the backbone for critical natural language processing applications, making reliable text generation a fundamental challenge. Traditional decoding approaches consistently struggle to balance fluency and coherence, often yielding repetitive sequences or semantically inconsistent outputs. While contrastive search was recently proposed to solve this issue, it relied on the unverified assumption that model representations are intrinsically anisotropic, necessitating computationally expensive additional training. The authors systematically test this assumption across 38 models spanning 16 languages and discover that anisotropy is actually rare, with most modern architectures exhibiting isotropic properties. By leveraging this finding, the authors demonstrate that contrastive search can be applied directly to off-the-shelf models without any calibration, significantly outperforming prior decoding strategies and achieving human-level generation quality across multiple tasks and languages.
Dataset

Dataset composition and sources: The authors do not disclose dataset composition or sources in the provided text. Key details for each subset: The authors provide no information on subset sizes, sources, or filtering rules. How the paper uses the data: The authors do not describe training splits, mixture ratios, or data usage. Processing details: The authors omit any cropping strategies, metadata construction, or processing steps.
Method
The authors leverage a framework that integrates the analysis of language model isotropy with a novel decoding strategy to improve generation quality. To evaluate isotropy, they define the self-similarity of token representations within a text sequence x as:
self-similarity(θ;x)=∣x∣×(∣x∣−1)1i=1∑∣x∣j=1,i=j∑∣x∣∥hxi∥⋅∥hxj∥hxi⊤hxj,where x={x1,…,x∣x∣} is a variable-length text sequence, and hxi, hxj are the representations of tokens xi and xj produced by the language model θ. This metric quantifies how similar the representations of distinct tokens are; lower values indicate more discriminative representations. The isotropy of the model θ over a corpus D is then defined as:
isotropy(θ)=1−∣D∣1x∈D∑self-similarity(θ;x).A higher isotropy value reflects a more uniform distribution of representations in the embedding space, indicating better adherence to an isotropic structure.
Experiment
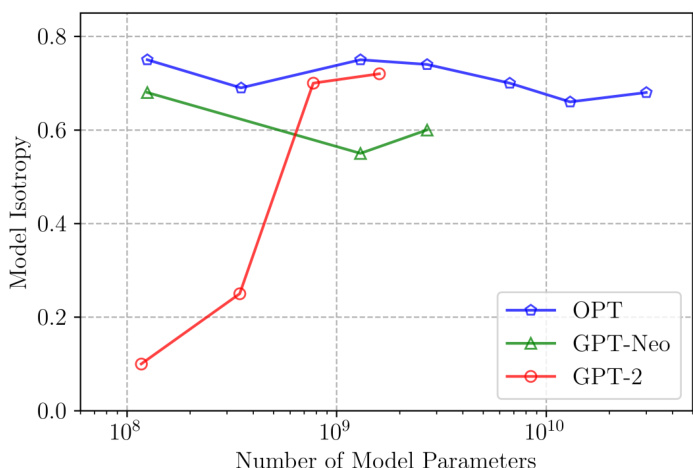
The experiments evaluate the isotropy of modern autoregressive language models across various scales and languages, revealing that most contemporary models exhibit isotropic representation spaces while smaller variants remain anisotropic. Subsequent evaluations on open-ended text generation, document summarization, code generation, and machine translation validate that contrastive search consistently outperforms traditional decoding strategies by effectively balancing semantic coherence with linguistic diversity. Further analysis demonstrates that an isotropic representation space is essential for contrastive search to maintain optimal degeneration penalty variance and avoid degenerating into greedy decoding. Collectively, these findings establish contrastive search as a robust decoding method that fully leverages the intrinsic capabilities of pre-trained language models across diverse multilingual and specialized tasks.
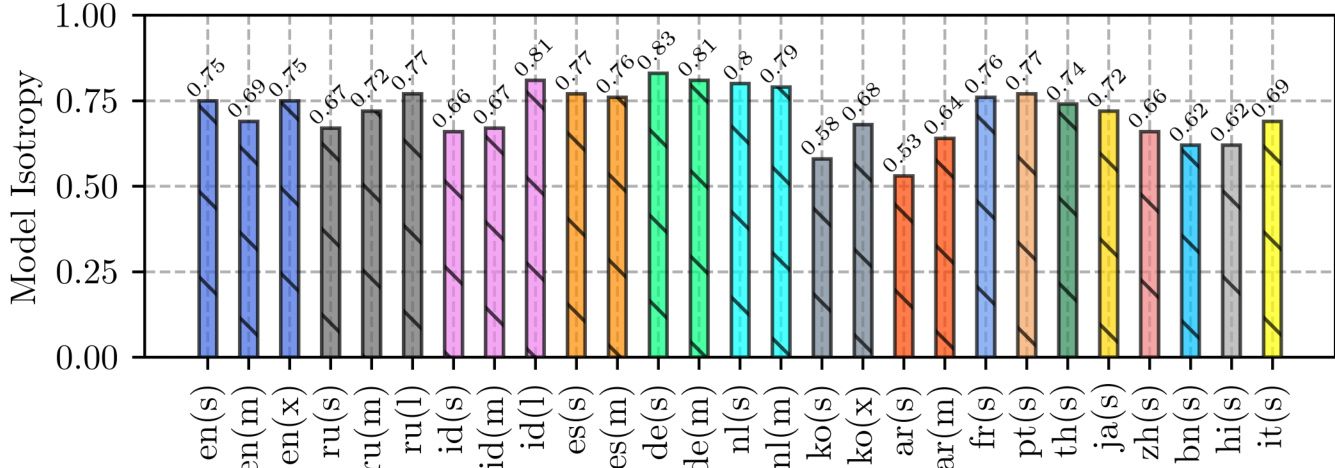
The authors evaluate the isotropy of language models across multiple languages and model scales, finding that most models exhibit high isotropy except for smaller models. The results indicate that isotropy is a common property in larger language models and is essential for the effectiveness of contrastive search, as models with higher isotropy show greater variance in degeneration penalties during decoding. Most evaluated language models exhibit high isotropy, with only smaller models showing low isotropy. Isotropy is crucial for contrastive search, as models with higher isotropy demonstrate greater variance in degeneration penalties. The findings suggest that intrinsic isotropy in language models reduces the need for additional training methods like SimCTG.
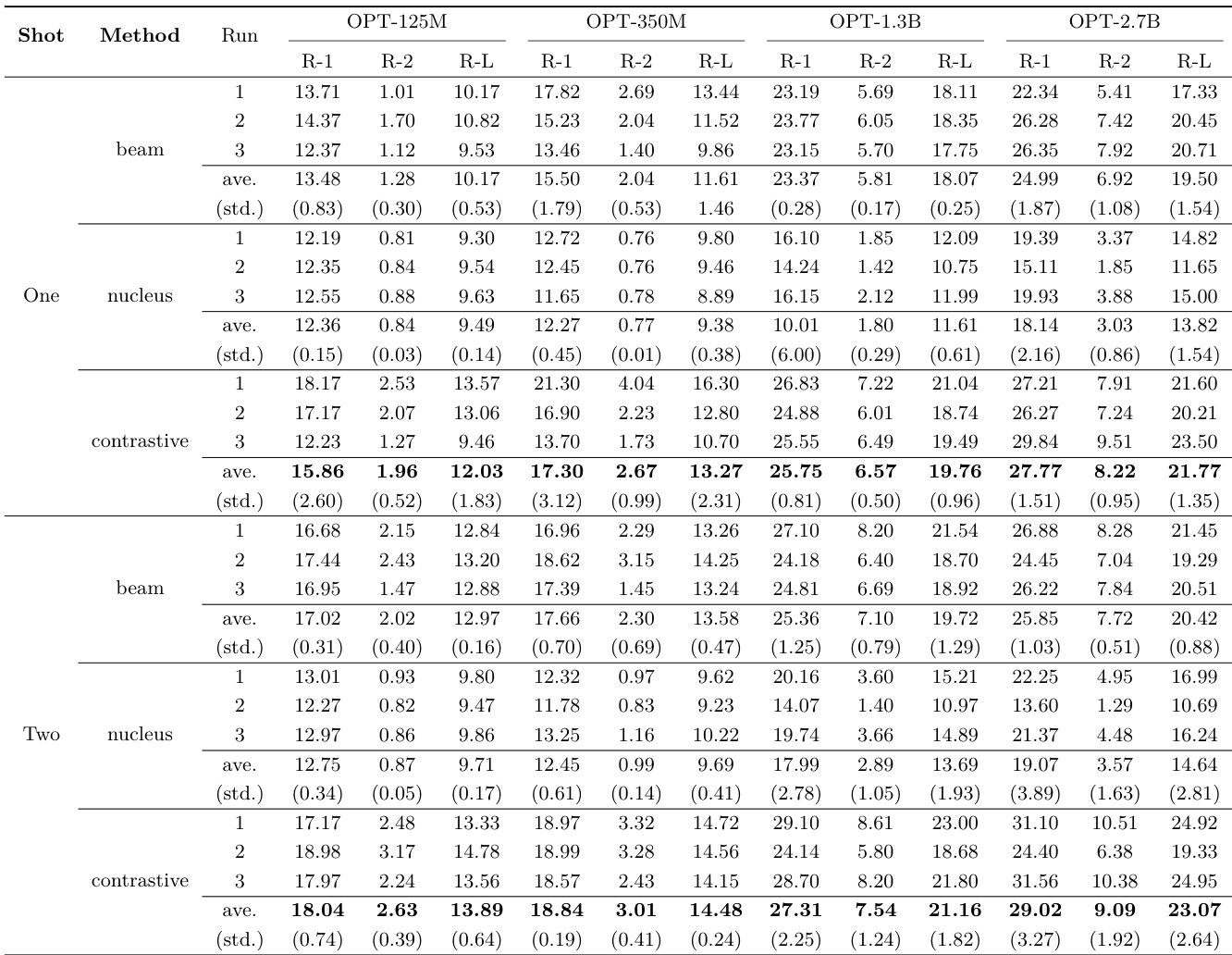
The authors evaluate the performance of different decoding methods on document summarization using OPT models with varying scales. The results show that contrastive search consistently outperforms other methods across all model sizes and evaluation metrics, particularly in terms of coherence and overall quality. The experiments also highlight the importance of model scale, with larger models achieving significantly better results. Contrastive search achieves the best results across all evaluation metrics compared to beam search and nucleus sampling. Larger model scales consistently yield better performance than smaller ones across all decoding methods. Contrastive search demonstrates strong coherence and maintains high-quality outputs across different model sizes and settings.
The authors evaluate contrastive search against various decoding methods in open-ended text generation tasks, comparing both automatic and human evaluation results. The experiments show that contrastive search achieves superior performance in coherence and overall quality compared to other methods, with results indicating it maintains semantic consistency better than alternatives. The findings are consistent across different language models and evaluation metrics, highlighting the robustness of contrastive search. Contrastive search outperforms other decoding methods in coherence and overall quality according to human evaluation. Contrastive search achieves higher scores in maintaining semantic consistency with the prefix text compared to baseline methods. The results demonstrate the effectiveness of contrastive search across different decoding strategies and evaluation metrics.
The authors compare the performance of SimCTG and off-the-shelf language models using contrastive search for text generation. Results show that both models achieve similar diversity and MAUVE scores, with the off-the-shelf model having a slightly higher gen-length. The coherence metric indicates that the off-the-shelf model performs better, though both models show low coherence values. Both SimCTG and off-the-shelf models achieve comparable diversity and MAUVE scores. The off-the-shelf model generates slightly longer texts than SimCTG. The off-the-shelf model demonstrates better coherence compared to SimCTG.

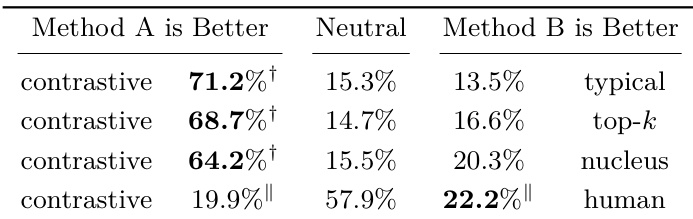
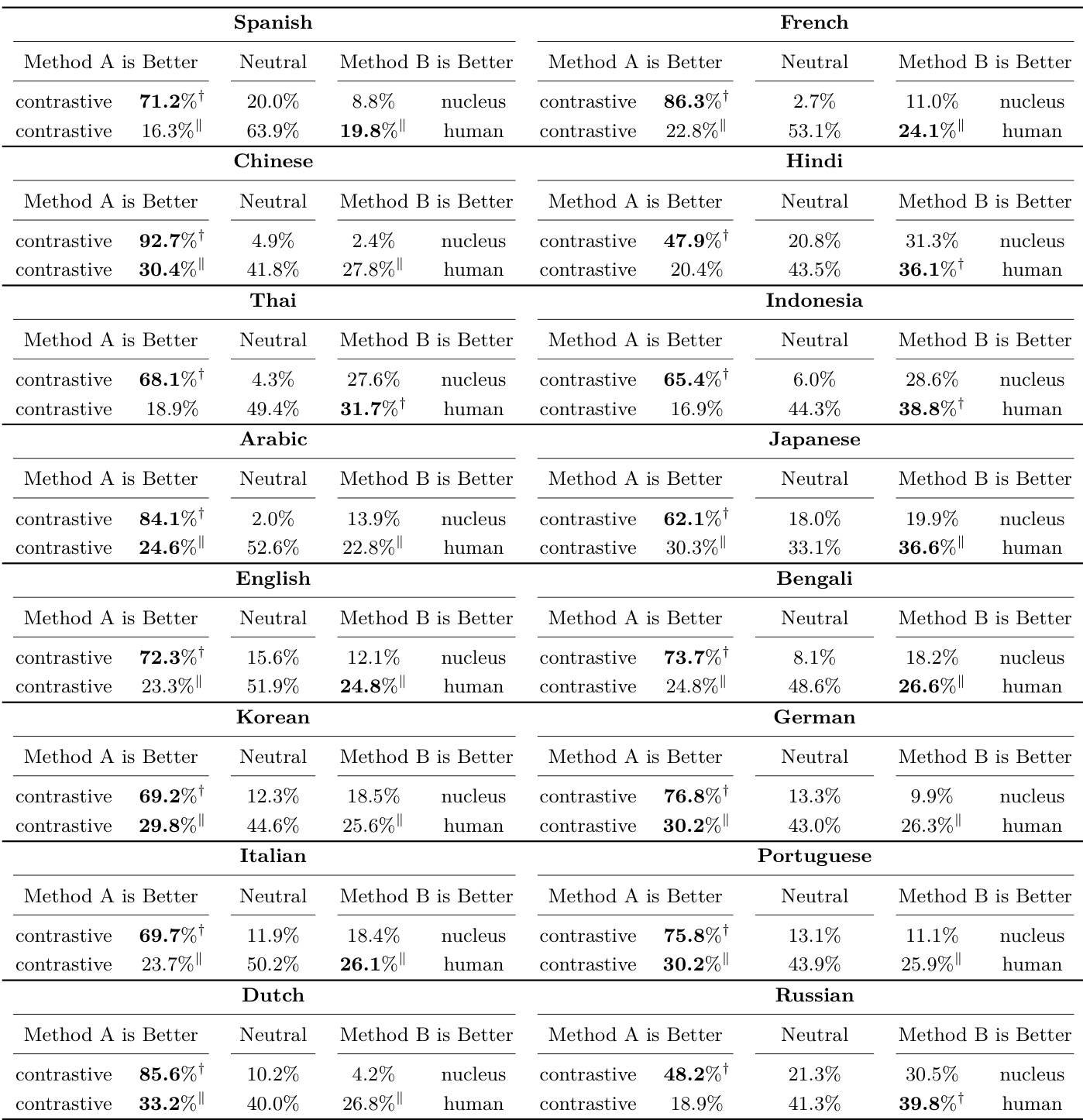
The authors conduct human evaluations comparing contrastive search against nucleus sampling across multiple languages, showing that contrastive search significantly outperforms nucleus sampling in most cases. The results indicate that contrastive search maintains semantic coherence and produces higher-quality text, with performance comparable to human-written text in many languages. The evaluation is consistent across diverse language pairs and supports the robustness of contrastive search in multilingual settings. Contrastive search significantly outperforms nucleus sampling in most languages, as validated by human evaluation. Contrastive search achieves performance comparable to human-written text in many languages, indicating high-quality generation. The results are consistent across diverse languages, demonstrating the generalization of contrastive search in multilingual settings.
The experiments evaluate language models across multiple scales, languages, and generation tasks to assess the role of intrinsic isotropy and the effectiveness of contrastive search against standard decoding strategies. Results consistently demonstrate that larger models naturally exhibit high isotropy, which enhances contrastive search by improving penalty variance and reducing the need for specialized training methods. Across summarization, open-ended generation, and multilingual settings, contrastive search consistently outperforms baseline approaches in coherence, semantic consistency, and overall text quality, often matching human-written standards. These findings collectively establish contrastive search as a robust decoding strategy that leverages natural model properties to produce high-quality, coherent outputs without additional fine-tuning.