Command Palette
Search for a command to run...
Un atelier de diffusion pour initier les jeunes étudiants italiens au TALN
Un atelier de diffusion pour initier les jeunes étudiants italiens au TALN
Lucio Messina Lucia Busso Claudia Roberta Combei Ludovica Pannitto Alessio Miaschi Gabriele Sarti Malvina Nissim
TAL — Introduction aux vecteurs de caractéristiques
Résumé
Nous décrivons et mettons à disposition le matériel basé sur le jeu développé pour un atelier organisé dans plusieurs festivals italiens de la science, afin de vulgariser le traitement automatique des langues (NLP) auprès des jeunes étudiants.
One-sentence Summary
The authors describe and make available a game-based educational toolkit developed for a laboratory run at several Italian science festivals to introduce natural language processing to young Italian students.
Key Contributions
- Introduces a game-based educational toolkit that translates morpho-syntactic tagging and grammar extraction into interactive physical activities for popularizing natural language processing among young students.
- Provides Python scripts that process annotated corpora, extract grammar rules, generate printable card decks, and produce transparent overlays for guided translation exercises.
- Releases all teaching materials and source code under CC BY-NC and GNU GPL v3 licenses, with deployment validated across multiple Italian science festivals and university research workshops.
Introduction
The source text is empty. Please provide the abstract or body snippet so I can summarize the technical context, prior limitations, and the authors’ main contribution as requested.
Dataset
- Dataset composition and sources: The authors compiled a specialized Italian language corpus tailored for educational NLP workshops, drawing from manually curated linguistic resources and materials developed specifically for science festival and classroom activities.
- Subset details and organization: Instead of conventional machine learning splits, the material is divided into functional components: an annotated corpus with morpho-syntactic and syntactic tags, printable vocabulary card decks, clear-text corpora, and a reference dictionary for sentence translation exercises.
- Usage and processing workflow: The authors do not use this data for model training. Instead, they apply it to create interactive teaching games for young students. Automated scripts extract bigram co-occurrences and grammar rules to propose sentences, which educators then manually select and refine before generating the final teaching assets.
- Physical and digital processing: The pipeline converts annotated text into clear formats, then requires manual cutting and mounting of sentences onto transparent overlays that align with printed corpora. The authors also produce tactile learning aids like color-coded felt strips and button-loop cards, with all digital assets and preprocessing scripts packaged under open licenses for reproducible distribution.
Method
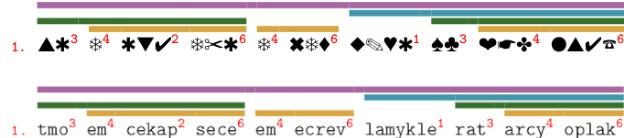
The authors leverage a modular, interactive workshop framework designed to introduce natural language processing (NLP) and computational linguistics to young students and the general public through hands-on, game-based learning. The core of the approach centers on simulating how machines process language without relying on semantic understanding, using a fictional language constructed from a well-known fairy tale, "Snow White." This method enables participants to engage with fundamental NLP tasks—such as sentence ordering and grammatical rule extraction—by treating language as a sequence of symbols rather than meaningful units.
The framework begins with a brief theoretical introduction to computational linguistics, addressing common misconceptions and highlighting practical applications such as vocal assistants to illustrate the differences between human and machine language processing. The main instructional component is structured as a series of games that guide participants through the process of sentence generation and grammatical analysis using masked linguistic data. To simulate machine-like processing, the original text is transformed into a symbolic representation: each word is replaced either by a sequence of random symbols (referred to as DINGs) or by a non-word (e.g., "croto" for "morning"). The grammatical structure of each sentence is visually encoded using horizontal lines indicating phrases (e.g., noun or verb phrases) and superscript numbers from 0 to 9 denoting parts of speech. This encoding allows participants to focus on syntactic patterns rather than semantics.
Participants are divided into two teams, each working with a version of the masked corpus in either Italian or English. The first activity involves constructing valid sentences by rearranging physical cards, each representing a token from the corpus. These cards are equipped with button loops, enabling participants to physically thread them into sequences based on bigram distributions observed in the corpus, thereby mimicking a probabilistic language model. This tactile method, referred to as the bracelet method, supports intuitive learning of statistical language patterns.
The second activity shifts focus to rule-based sentence generation. Participants analyze the annotated corpus to extract grammatical rules, using felt strips to represent phrase types and numbered cards to denote parts of speech. These rules are then applied to generate new sentences using a new set of uncorpus words, emphasizing the role of syntax in language modeling. The process reinforces the idea that language structure can be learned from data without semantic knowledge.
As the final step, the true nature of the corpus is revealed by superimposing a plexiglass frame over the A3-sized corpus pages, allowing participants to see the original text and translate their generated sentences. This moment serves as a reflective conclusion, bridging the gap between the symbolic exercise and real-world language. The workshop concludes with a discussion on current NLP technologies and the skills required to become a computational linguist.



