Command Palette
Search for a command to run...
TIDE: Proactive Multi-Problem Discovery via Template-Guided Iteration
TIDE: Proactive Multi-Problem Discovery via Template-Guided Iteration
Soyeong Jeong Jinheon Baek Minki Kang Sung Ju Hwang
Abstract
Agents are widely deployed as assistants over documents, tools, and code. However, they typically act only on explicit user requests, which surface only the problems the user has noticed, while many other important problems coexist, hidden in plain sight, within the broader user context, with their total number unknown in advance. We frame this as the task of discovering multiple hidden problems from context, in which coexisting problems should be uncovered, grounded in supporting evidence, and paired with concrete actions. To this end, we introduce TIDE, a template-guided iterative framework with two complementary mechanisms. Specifically, motivated by the observation that single-pass prediction anchors on the most salient cases and yields generic claims, we propose iterative discovery, which surfaces a small batch of candidates per round while conditioning on what has already been found, so subsequent rounds extend coverage; and thought templates, reusable schemas distilled from previously solved cases that specify what contextual signals to attend to and how to connect them, anchoring each prediction in a recognizable problem class. We validate TIDE on two realistic settings, personal workspaces and software repositories, across four model backbones, showing substantial gains over single-shot and parallel multi-agent baselines on task coverage, identification, and resolution.
One-sentence Summary
TIDE proactively uncovers multiple hidden problems within user contexts by combining iterative candidate generation conditioned on prior findings with reusable thought templates distilled from solved cases, effectively mitigating single-pass anchoring bias while surfacing evidence-grounded issues paired with concrete actions.
Key Contributions
- The paper introduces TIDE, a template-guided iterative framework that discovers multiple hidden problems from context without relying on explicit user requests. Each discovery round conditions on previously identified issues to iteratively expand coverage across coexisting challenges.
- The framework repurposes thought templates as discovery schemas that specify which contextual signals to attend to and how to connect them for inferring unstated problems. This design anchors each prediction in a recognizable problem class rather than optimizing a solution for a pre-defined task.
- Empirical evaluations demonstrate consistent performance gains across two realistic settings and four backbones. The framework maintains fixed inference templates that transfer across models while delivering favorable coverage trade-offs against multi-agent baselines at matched computational budgets.
Introduction
Large language model agents are widely deployed as digital assistants, yet they remain fundamentally reactive and dependent on explicit user commands. This limitation matters because real-world workflows contain multiple unarticulated bottlenecks and hidden issues that coexist across documents, emails, and codebases, making single-request interaction models ineffective for comprehensive assistance. Prior proactive agent research has primarily focused on anticipating a single localized need or determining when to intervene, but these approaches still anchor to existing user queries and fail to jointly discover, ground, and resolve multiple coexisting problems within a broad context. To overcome these challenges, the authors present TIDE, a framework that reframes proactive assistance as an iterative discovery process guided by reusable thought templates. The authors leverage iterative rounds to surface small batches of candidates conditioned on cumulative findings, while distilled reasoning schemas anchor each prediction to recognizable problem patterns. This dual mechanism enables the system to systematically identify and resolve multiple hidden issues, consistently outperforming single-shot and parallel multi-agent baselines across personal workspace and software repository environments.
Dataset
-
Dataset Composition and Sources
- The authors construct two evaluation datasets centered on a multi-problem discovery structure, filling a benchmark gap by extending both synthetic and real-world sources.
- One set simulates individual digital workspaces, while the other captures live open-source software repositories.
-
Subset Details
- Personal Workspace: Built using the Pasternak et al. (2025) pipeline, this subset contains 150 problems distributed across 30 workspaces. Each instance includes a user profile and 88 to 113 artifacts such as documents, emails, and calendar entries. Problems require synthesizing evidence across multiple files, while the remaining items serve as plausible distractors. Resolutions follow a predefined action schema paired with specific execution parameters.
- Software Repository: Sourced from Python projects in SWE-BENCH and TESTEXPLORA, this subset features 146 problems across 20 multi-bug instances from 11 repositories. Each instance captures a repository snapshot at a shared commit containing 2 to 41 unresolved issues and 6 to 646 candidate functions. The authors group issues at a common anchor commit where all target bugs remain unfixed, retaining only groups with at least two coexisting bugs that affect multiple functions. Gold resolutions are the original pull request patches.
-
Data Usage and Processing
- The authors reserve both subsets strictly for evaluation and inference rather than model training, constructing dedicated test splits to measure multi-problem discovery from context.
- During inference, the model processes curated context windows to isolate concurrent problems, generate resolutions, or extract reasoning patterns.
- The pipeline leverages few-shot template generation, where solved examples are processed to build a reusable pattern pool that guides agent decision-making across new instances.
-
Metadata and Structural Processing
- Context windows are deliberately balanced with signal and noise, with distractor artifacts or functions carefully selected to mimic project relevance without containing actual problems.
- For the code subset, the authors extract diff-based metadata by treating pre-patch code as the bug shape, post-patch code as the fix shape, and the diff itself as the repair intent.
- A structured JSON template pool is generated via a prompt that extracts repo-agnostic bottleneck patterns and step-by-step evidence flows. Only the pattern description and evidence flow are exposed to the agent at inference, while the full template structure remains internal.
Method
The authors leverage a template-guided iterative framework, TIDE, to address the challenge of uncovering multiple hidden problems within a given context, where the total number of problems is unknown and many are obscured by more salient issues. The framework is designed to improve both coverage and fidelity compared to single-shot approaches. It combines two complementary mechanisms: thought templates and iterative discovery.
Thought templates are reusable schemas distilled from previously solved cases, which serve as priors to guide the agent in identifying specific problem classes. Each template is structured as a tuple containing a name for the problem class, a pattern describing its structural form, and an evidence flow that outlines the sequence of contextual signals to attend to and how they should be connected to infer an instance of the class. These templates are constructed once from a set of training instances and are held fixed during inference. By supplying the agent with this library of discovery schemas, predictions are anchored in recognizable problem classes rather than being inferred from scratch, thereby enhancing fidelity.
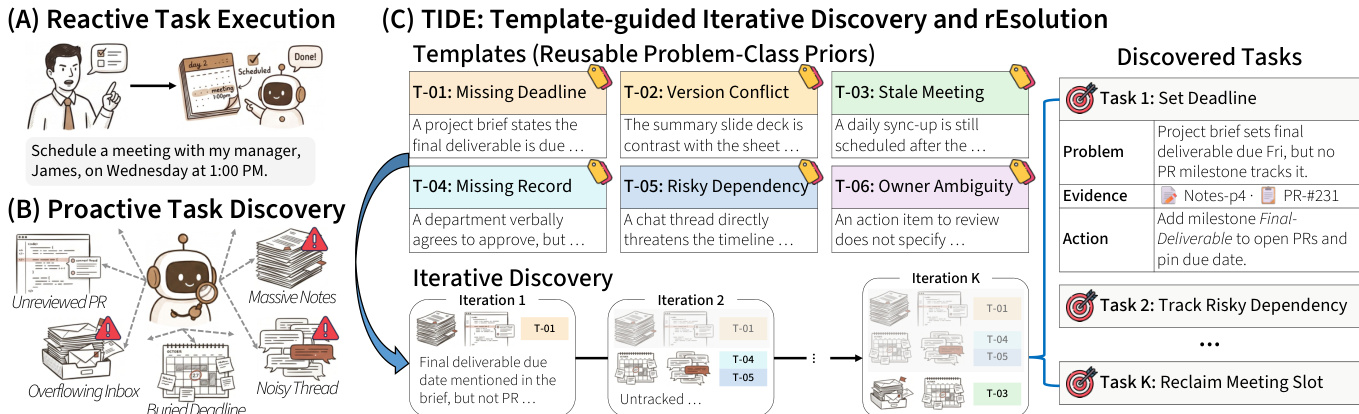
As shown in the figure below, the framework operates in an iterative manner. The process begins with an initial state of no discovered tasks. In each round t, the agent generates a small batch of up to k new candidate predictions, each in the form of a triple consisting of a natural-language problem description b, a supporting subset of documents D^, and a concrete action a. This generation is conditioned on the full document collection D, the fixed template set T, and the cumulative prediction state P^(t−1) from the previous round. The cumulative state is updated by merging the new predictions, and the process repeats for a predefined number of rounds T or until a round yields no new predictions. This iterative conditioning ensures that subsequent rounds are pushed beyond the previously discovered problems, thereby broadening coverage. Each round produces an actionable plan that simultaneously identifies, grounds, and proposes a resolution for each surfaced problem, integrating identification, retrieval, and action into a single step.
Experiment
The evaluation compares TIDE against single-pass and parallel multi-agent baselines across personal workspace and software repository contexts to assess multi-problem discovery. Ablation studies validate that iterative conditioning on cumulative findings prevents redundant predictions and systematically uncovers hidden issues, while template comparisons demonstrate that structured reasoning patterns significantly enhance prediction accuracy and generalize across different LLM backbones. Qualitative case studies further confirm that this combined approach successfully identifies complex, interrelated defects that baseline methods either miss or oversimplify. Ultimately, the findings establish that iterative discovery and reusable templates work synergistically to transform proactive assistance into a robust, multi-step investigative process.
The authors evaluate a framework that combines iterative discovery with thought templates for multi-problem detection, comparing it against single-agent and multi-agent baselines across different language models. Results show that the iterative approach consistently outperforms parallel methods in retrieving, identifying, and resolving problems, with templates enhancing prediction accuracy and contributing to improved performance. The framework achieves higher coverage and F1 scores across retrieval, identification, and resolution tasks, particularly when leveraging iterative discovery and reusable reasoning patterns. Iterative discovery with thought templates consistently outperforms single-pass and parallel-agent methods in multi-problem detection. The framework achieves higher coverage and F1 scores across retrieval, identification, and resolution compared to baselines. Thought templates enhance prediction accuracy, with complementary gains when combined with iterative discovery.
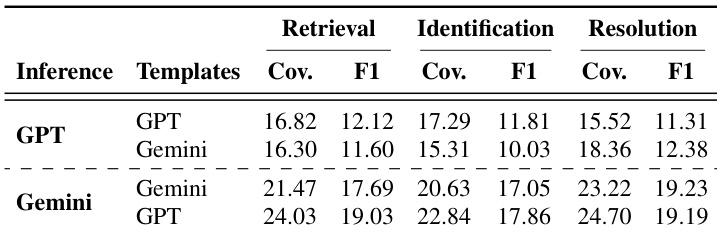
The authors compare their iterative discovery framework, TIDE, against single-agent and multi-agent baselines across multiple LLMs and two evaluation settings. Results show that TIDE consistently outperforms the baselines in retrieving, identifying, and resolving multiple hidden problems, with the gap widening as the number of gold problems increases. The framework's effectiveness is attributed to iterative discovery and thought templates, which enable it to surface new problems across rounds and improve prediction accuracy. TIDE consistently achieves the highest performance across retrieval, identification, and resolution compared to single-agent and multi-agent baselines. TIDE scales better with increased LLM-call budgets, while multi-agent methods plateau and fail to match its performance. The combination of iterative discovery and thought templates drives both coverage and precision, with templates improving prediction accuracy and iteration enabling the discovery of additional problems.
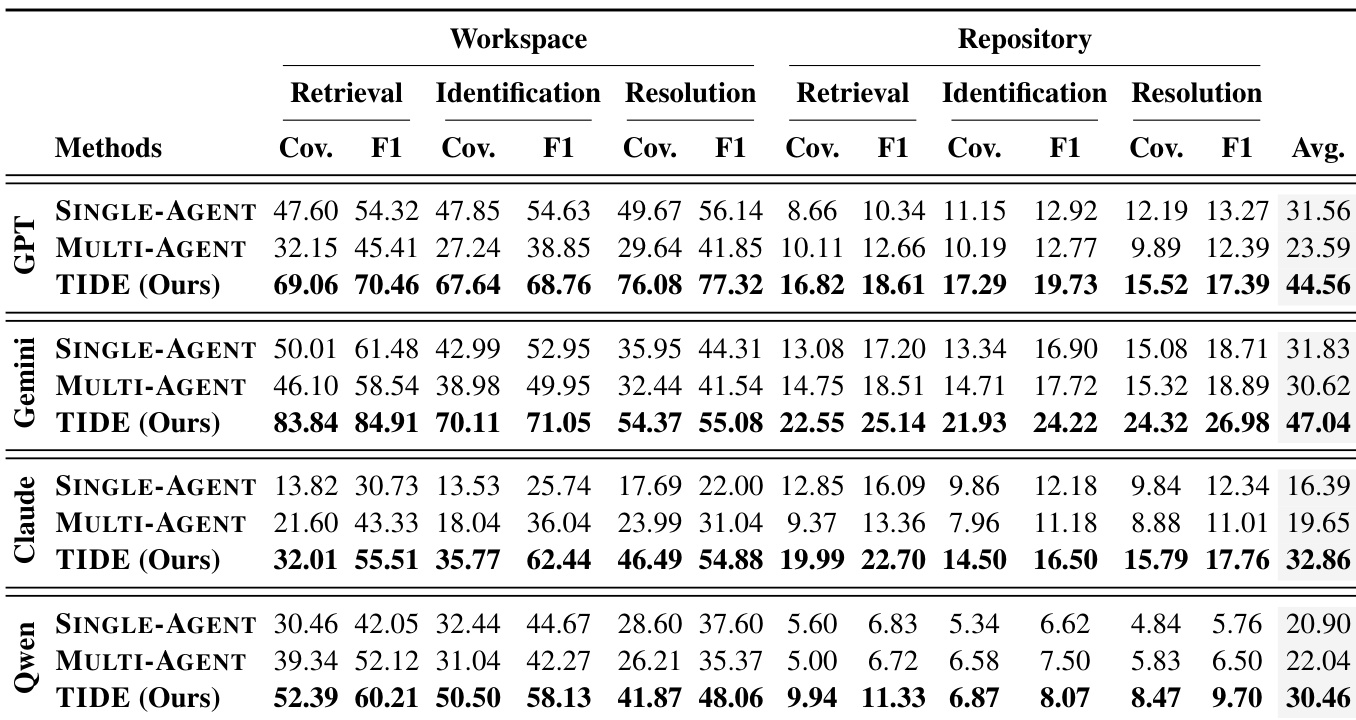
The authors evaluate their framework TIDE against baseline methods on multi-problem discovery tasks, comparing performance across retrieval, identification, and resolution. Results show that TIDE consistently outperforms both single-pass and multi-agent baselines, with iterative discovery and thought templates contributing complementary improvements in coverage and precision. TIDE achieves higher coverage and F1 scores than baseline methods across retrieval, identification, and resolution. Iterative discovery enables TIDE to continuously discover new problems, while baseline methods rely increasingly on re-discovering the same items. Thought templates improve prediction accuracy, working alongside iteration to enhance overall performance.
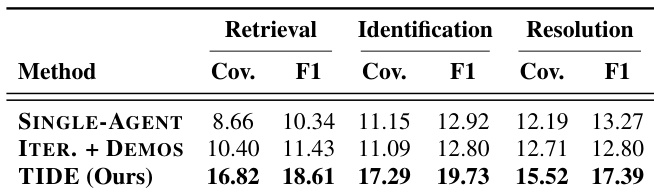
The authors evaluate their iterative discovery framework, TIDE, against single-agent and multi-agent baselines across multiple language models to assess its effectiveness in retrieving, identifying, and resolving multiple hidden problems. Experimental results demonstrate that the iterative approach consistently outperforms parallel methods by continuously surfacing new issues rather than repeating previous findings, with performance advantages becoming more pronounced as problem complexity increases. Furthermore, thought templates significantly enhance prediction accuracy, and their integration with iterative discovery yields superior overall detection coverage and reasoning reliability across all evaluation stages.