Command Palette
Search for a command to run...
One-click Deployment of MedGemma-4b-it Multimodal Medical AI Model
Abstract
One-sentence Summary
MIRAGE is a multimodal retrieval and generation system that maps medical text and images to a shared latent space using a fine-tuned MedICaT-ROCO model, the Prompt2MedImage diffusion network, and the Dolly-v2-3b language model to retrieve and synthesize clinically relevant visuals, providing medical students with a free, Kaggle-hosted educational platform that relies exclusively on publicly available pretrained models.
Key Contributions
- The paper introduces MIRAGE, a unified multimodal system that integrates medical image retrieval, synthetic image generation, and concept-level comparison via latent space arithmetic. By mapping textual and visual inputs into a shared embedding space, the architecture enables semantically aligned queries and supports dual-search functionality for visualizing clinical differences.
- The processing pipeline relies exclusively on publicly available pretrained models, including a fine-tuned MedICaT-ROCO vision-language encoder, the Prompt2MedImage diffusion generator, and the Dolly-v2-3b large language model. Trained on the ROCO dataset, this transparent stack guarantees full reproducibility without requiring specialized computational infrastructure.
- The platform is deployed on Kaggle and validated through quantitative and qualitative analyses that confirm its semantic consistency in realistic educational scenarios. This accessible interface enables interactive medical training for students without programming expertise.
Introduction
Medical education fundamentally depends on interactive access to high-quality, annotated visual data to train diagnostic skills and anatomical understanding. While traditional atlases offer clinical reliability, they are cumbersome and static, and general web searches frequently yield unverified or poorly labeled content. Existing AI-driven educational tools remain largely text-focused and fail to integrate reliable image retrieval, synthetic generation, and validated clinical grounding into a single workflow. To bridge this gap, the authors leverage a fine-tuned medical vision-language model, a domain-specific diffusion generator, and a large language model to build MIRAGE, a unified platform that retrieves relevant medical images, produces synthetic visuals, and generates enriched clinical descriptions from user prompts. The system also enables comparative analysis through latent space manipulation and runs entirely on publicly available pretrained models, ensuring full reproducibility and straightforward deployment for medical students without technical expertise.
Dataset
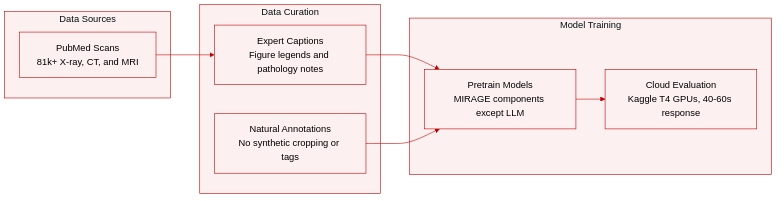
- Dataset Composition and Sources: The authors use the ROCO dataset, a large-scale multimodal medical imaging collection comprising over 81,000 images extracted from the Open Access subset of PubMed Central.
- Subset Details: The collection features diverse imaging modalities such as X-ray, CT, and MRI. Each image is paired with an expert-written caption drawn from figure legends or article content, which typically identifies the imaging type and specific pathology.
- Data Usage: All MIRAGE components except the underlying large language model are pretrained on this dataset to support multimodal research and interactive medical query processing.
- Processing and Metadata: The dataset relies on naturally occurring clinical annotations rather than synthetic metadata or cropping strategies. Captions function as the primary textual grounding, preserving diagnostic context while enabling reproducible training and cloud-based inference.
Method
The authors leverage a multimodal framework centered around a shared latent space to enable semantic retrieval and generation of medical images and descriptions. The system, MIRAGE, operates through three primary modules: a system encoder, query processing, and synthetic image generation. The overall architecture is designed to support educational use cases in medical imaging, allowing users to retrieve relevant images, obtain enriched textual descriptions, and generate synthetic images based on user queries.
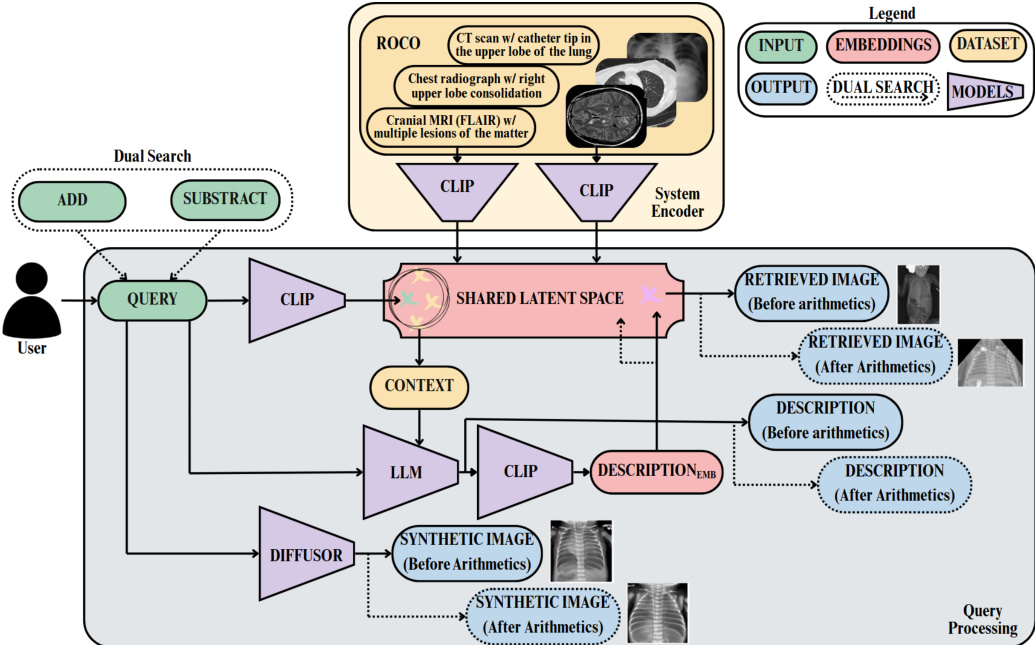
Refer to the framework diagram to understand the end-to-end workflow. The system begins with the ROCO dataset, which serves as a reference atlas of medical images and their corresponding captions. Both images and captions are embedded into a shared latent space using a CLIP-based model fine-tuned for medical content, CLIP-ViT-L-14-448px-MedICaT-ROCO. This model employs separate text and visual encoders to produce normalized embeddings, enabling direct semantic comparison between textual queries and image representations. These embeddings are precomputed and stored for efficient cosine similarity retrieval.
As shown in the figure below, the query processing module accepts a user input describing a medical concept or condition. The query is encoded into an embedding using the same CLIP model, which is then compared against the precomputed image embeddings in the shared latent space. The top-k most similar images are retrieved, and their corresponding captions are used as context for a general-purpose instruction-following language model, Dolly-v2-3b. This model generates an enriched caption that provides a more detailed and contextually relevant description of the queried concept. The enriched caption is then re-encoded using CLIP, and a second retrieval step compares it against the image embeddings to return the most semantically aligned image, along with the enriched description.
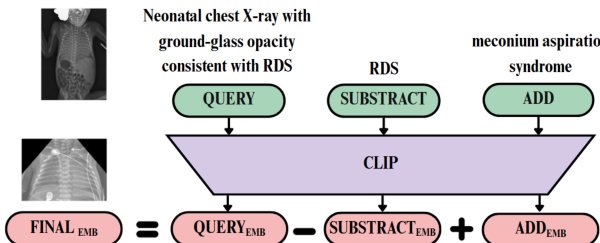
The system further supports a dual search module designed to facilitate the comparison of two related medical concepts. This feature enables users to explore the differences between clinically distinct conditions by performing latent space arithmetic. When a user specifies a base query and two terms—one to subtract and one to add—the system embeds all textual inputs into the shared semantic space. The modified query embedding is computed as the difference between the original query embedding and the subtracted term's embedding, plus the added term's embedding, as defined in Equation 1. This transformation shifts the semantic representation toward the new concept. Both the original and modified embeddings are used to retrieve their respective top-1 most similar images, enabling side-by-side visual comparison.
In addition to retrieval, the system generates synthetic medical images using a diffusion-based model, Prompt2MedImage, which is trained on medical content and supports various modalities such as MRI, CT, and X-ray. The original user prompt is used for image generation, as longer descriptions do not improve synthetic output quality. The synthetic image generation process is integrated into the pipeline, allowing users to compare real and synthetic images, which enhances conceptual understanding and interpretation. The entire pipeline is designed with human-AI collaboration in mind, encouraging active learning through interactive exploration and contextualized visual and textual feedback.
Experiment
The evaluation combines quantitative embedding analysis to verify semantic alignment across textual and multimodal pairs with qualitative visual inspection to assess retrieval accuracy and generative fidelity in medical contexts. Experimental results demonstrate that the latent space reliably preserves clinical relationships, ensuring semantically related inputs are consistently distinguished from unrelated ones. Qualitative assessments further confirm that the system retrieves real images closely aligned with user queries and generates synthetic visuals that accurately capture specified anatomical and pathological features. Additionally, latent space operations successfully drive predictable semantic and visual shifts, highlighting the model's practical utility for interactive medical education and concept exploration.
The authors evaluate the semantic consistency of their multimodal system by analyzing cosine similarity scores and classification accuracy across different input types, including text-text, real image-caption, and synthetic image-caption pairs. Results show that semantically similar inputs consistently achieve higher similarity scores than dissimilar ones, with high classification accuracy across all setups. The system demonstrates strong alignment between textual and visual representations, particularly for real image-caption pairs, while synthetic image-caption pairs also show significant but lower similarity. The authors further illustrate the system's capabilities through qualitative examples, highlighting the ability to retrieve relevant images and generate synthetic images that capture key medical features, with visual and semantic shifts in response to query modifications. Text-text and real image-caption pairs exhibit higher similarity scores and classification accuracy compared to synthetic image-caption pairs. The system achieves high classification accuracy for separating similar from dissimilar pairs across all evaluated types. Qualitative results demonstrate that the system can generate synthetic images that reflect key medical features and respond to query modifications with appropriate visual and semantic changes.

The evaluation assesses semantic consistency by testing the system across text-text, real image-caption, and synthetic image-caption pairs to validate representational alignment and classification reliability. Results indicate that the model consistently distinguishes between similar and dissimilar inputs, with real-world pairs exhibiting stronger visual-textual coherence than synthetic alternatives. Qualitative assessments further demonstrate the system's ability to retrieve relevant medical imagery and generate accurate synthetic visuals that adapt appropriately to query modifications. Overall, the framework successfully maintains semantic integrity and delivers contextually appropriate multimodal outputs across all evaluated configurations.