Command Palette
Search for a command to run...
MultiActor-Audiobook: Zero-Shot Audiobook Generation with Faces and Voices of Multiple Speakers
MultiActor-Audiobook: Zero-Shot Audiobook Generation with Faces and Voices of Multiple Speakers
Kyeongman Park Seongho Joo Kyomin Jung
One-click Deployment of Ebook2Audiobook: eBook to Audiobook
Abstract
We introduce MultiActor-Audiobook, a zero-shot approach for generating audiobooks that automatically produces consistent, expressive, and speaker-appropriate prosody, including intonation and emotion. Previous audiobook systems have several limitations: they require users to manually configure the speaker's prosody, read each sentence with a monotonic tone compared to voice actors, or rely on costly training. However, our MultiActor-Audiobook addresses these issues by introducing two novel processes: (1) MSP (Multimodal Speaker Persona Generation) and (2) LSI (LLM-based Script Instruction Generation). With these two processes, MultiActor-Audiobook can generate more emotionally expressive audiobooks with a consistent speaker prosody without additional training. We compare our system with commercial products, through human and MLLM evaluations, achieving competitive results. Furthermore, we demonstrate the effectiveness of MSP and LSI through ablation studies.
One-sentence Summary
MultiActor-Audiobook is a zero-shot framework that automatically generates consistent, expressive, and speaker-appropriate audiobook narration for multiple speakers by integrating Multimodal Speaker Persona Generation and LLM-based Script Instruction Generation, eliminating the need for manual prosody configuration or costly training while achieving competitive performance in human and MLLM evaluations against commercial products.
Key Contributions
- MultiActor-Audiobook is a zero-shot framework that eliminates manual prosody configuration and costly training by automatically generating consistent, character-appropriate narration. The system anchors speaker identity through Multimodal Speaker Persona Generation, which extracts textual traits, synthesizes AI face images, and maps them to unique voice samples using a pretrained Face-to-Voice model.
- The LLM-based Script Instruction Generation process employs GPT-4o to dynamically produce sentence-level emotional, tonal, and pitch instructions conditioned on narrative context and character personas. These structured prompts enable a standard text-to-speech model to deliver contextually appropriate and expressive audiobook narration.
- Human and MLLM evaluations demonstrate that the framework achieves competitive mean opinion scores against commercial audiobook products and yields a 0.225-point average improvement in automated assessments. Ablation studies validate that both the persona generation and instruction modules independently contribute to the observed gains in prosodic consistency and emotional expressiveness.
Introduction
Audiobook generation requires converting multi-character literary texts into speech that dynamically matches emotional context and distinct speaker traits. Prior systems struggle with either the high cost of collecting large-scale training datasets or the labor-intensive process of manually annotating prosody and emotion for every sentence. The authors address these bottlenecks with MultiActor-Audiobook, a zero-shot framework that automates expressive speech synthesis without additional training. They leverage a multimodal speaker persona pipeline to generate unique character voices from textual descriptions and AI-generated faces, while an LLM-based script instruction module dynamically assigns context-aware emotional and tonal cues to each sentence. This combination enables consistent, actor-like delivery across diverse characters while eliminating manual configuration and costly data collection.
Dataset
- Dataset Composition and Sources: The authors combine narrative text and AI-generated visuals to create a multimodal training corpus. The textual foundation comes from ReedsyPrompts, selected for its capacity to feature multiple distinct speakers within a single narrative. Visual personas are generated using a photorealistic variant of Stable Diffusion.
- Key Subset Details: Due to high computational costs during audio synthesis, only a curated subset of stories was retained. Each selected story averages 4.3 speakers, 175 sentences, and 749.56 seconds of audio. For the visual component, the team applies a strict filtering rule to discard any generated outputs that do not clearly depict a human face.
- Data Usage and Processing: The filtered narratives and corresponding personas are prepared to train the backbone text-to-speech model. The authors specifically prioritize photorealistic generation to maintain domain consistency with the real human speech data used in the primary training set. The curated subset is used directly for training without additional mixture ratios.
- Metadata and Generation Strategy: The pipeline tracks narrative metrics such as speaker counts and sentence lengths to ensure diverse character representation. Facial generation relies on captions produced in a prior step, with the human face filter serving as the primary quality control mechanism. While explicit cropping is not detailed, the filtering process ensures only valid human facial regions are retained for model integration.
Method
The authors leverage a two-stage framework to generate speaker-aligned and emotionally expressive audiobooks, as illustrated in the overall architecture. The process begins with the input story, which undergoes Multimodal Speaker Persona Generation to establish distinct character identities. This stage involves extracting all speakers from the narrative using GPT-4, including the narrator, and generating descriptive captions that detail each character’s physical appearance and personality traits. These captions are used to synthesize facial images via Stable Diffusion, resulting in visual representations of each character. Concurrently, the same textual descriptions and facial images are fed into FleSpeech to generate voice samples that align with each character’s persona.

As shown in the figure below, the second stage employs LLM-Based Script Instruction Generation to annotate each sentence with appropriate emotional delivery instructions. The LLM identifies the speaker of each sentence by analyzing the full story context and dialogue markers, then assigns the correct speaker ID and persona. For every sentence, the model generates a concise emotional instruction—such as tone, pitch, and pacing—based on the narrative context and the speaker’s established persona, ensuring natural emotional transitions. These instructions, along with the target text, are then integrated with the pre-generated facial images, voice samples, and captions.
The final multimodal input is processed by FleSpeech, the backbone text-to-speech model, which incorporates a unified multimodal prompt encoder. This encoder uses query-based MLPs and a diffusion process to map text, audio, and visual inputs into a shared representation. For each sentence, the system inputs the target text, the corresponding emotional instruction, the speaker’s face image, voice sample, and caption. The face images and voice samples remain fixed per character throughout the story, while only the text and emotional instruction are updated per sentence. This design enables the system to generate a natural audiobook with speaker-aligned voices and coherent emotional expression.
Experiment
The evaluation setup utilizes human listening tests and an MLLM to validate character-voice consistency, audio quality, emotional conveyance, and speaker identification, while quantitative analysis verifies voice stability and emotional fluency. While commercial platforms achieve strong human-rated consistency through extensive training or manually matched voices, the proposed system secures top automated scores by effectively leveraging multimodal speaker personas and script instructions. The quantitative results further confirm that the approach maintains robust voice consistency and generates diverse pitch variations, indicating strong emotional expressiveness. Overall, the system demonstrates effective dynamic audiobook generation, though future improvements will require training the backbone TTS model on larger datasets with more diverse visual inputs.
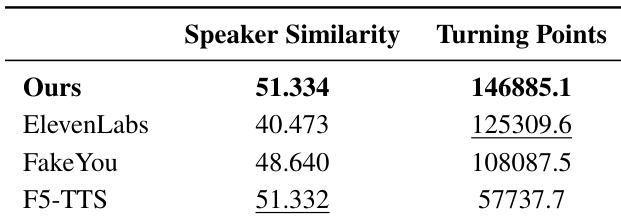
The authors conduct a quantitative analysis comparing their system with several baselines, focusing on speaker embedding similarity and pitch turning points as measures of voice consistency and emotional expressiveness. Results show that their system achieves the highest values in both metrics, indicating strong voice consistency and rich emotional variation across the audio samples. While ElevenLabs performs well in human evaluations for character-voice consistency, the proposed system demonstrates superior performance in maintaining speaker identity and expressing emotional nuances. The system achieves the highest speaker embedding similarity and number of pitch turning points, indicating strong voice consistency and emotional expressiveness. ElevenLabs shows high human evaluation scores for character-voice consistency but performs lower in quantitative measures of speaker similarity and pitch variation. The proposed system outperforms baselines in maintaining consistent speaker identity and generating emotionally varied speech patterns.
The authors evaluate their system against several baselines using human and MLLM evaluations, focusing on character-voice consistency, audio quality, emotion, and speaker identification. The results show that their system performs well in maintaining voice consistency and emotional expressiveness, with strong performance in speaker embedding similarity and pitch variation, though some baselines achieve higher scores in specific human evaluations. the system achieves the highest speaker embedding similarity and number of pitch turning points, indicating strong voice consistency and emotional expressiveness. ElevenLabs receives the highest human evaluation for character-voice consistency, while the system scores highest in MLLM evaluation for the same metric. the system outperforms baselines in speaker identification and maintains high audio quality across evaluations.

The proposed system was evaluated against several baselines through quantitative analysis, human assessments, and machine learning model evaluations to validate voice consistency, emotional expressiveness, and character alignment. Results indicate that the system excels in maintaining a stable speaker identity while generating highly nuanced emotional speech patterns, consistently outperforming competitors in automated and model-based assessments. Although certain baselines received higher human ratings for character-voice consistency, the proposed approach demonstrates superior capabilities in speaker identification and overall audio quality. Ultimately, the findings confirm that the system effectively balances consistent vocal identity with rich emotional variation across diverse speech samples.