Command Palette
Search for a command to run...
DEYO: DETR with YOLO for End-to-End Object Detection
DEYO: DETR with YOLO for End-to-End Object Detection
Haodong Ouyang
End-to-End Object Detection with Transformers: DETR
Abstract
The training paradigm of DETRs is heavily contingent upon pre-training their backbone on the ImageNet dataset. However, the limited supervisory signals provided by the image classification task and one-to-one matching strategy result in an inadequately pre-trained neck for DETRs. Additionally, the instability of matching in the early stages of training engenders inconsistencies in the optimization objectives of DETRs. To address these issues, we have devised an innovative training methodology termed step-by-step training. Specifically, in the first stage of training, we employ a classic detector, pre-trained with a one-to-many matching strategy, to initialize the backbone and neck of the end-to-end detector. In the second stage of training, we froze the backbone and neck of the end-to-end detector, necessitating the training of the decoder from scratch. Through the application of step-by-step training, we have introduced the first real-time end-to-end object detection model that utilizes a purely convolutional structure encoder, DETR with YOLO (DEYO). Without reliance on any supplementary training data, DEYO surpasses all existing real-time object detectors in both speed and accuracy. Moreover, the comprehensive DEYO series can complete its second-phase training on the COCO dataset using a single 8GB RTX 4060 GPU, significantly reducing the training expenditure.
One-sentence Summary
DEYO introduces a purely convolutional end-to-end object detector that employs a step-by-step training strategy to initialize its backbone and neck with a classic one-to-many detector before freezing them to train the decoder from scratch, ultimately surpassing existing real-time detectors in speed and accuracy on COCO while completing second-stage training on a single 8GB RTX 4060 GPU.
Key Contributions
- Proposes a step-by-step training paradigm that initializes the backbone and neck using a classic detector with one-to-many matching before freezing these components to train the decoder from scratch. This methodology stabilizes early-stage optimization and eliminates the requirement for supplementary pre-training datasets.
- Introduces DEYO, the first real-time end-to-end object detector employing a purely convolutional encoder architecture. By eliminating non-maximum suppression post-processing, the model delivers lag-free inference while surpassing existing real-time detectors in both speed and accuracy.
- Validates the framework through extensive evaluations on the COCO benchmark, demonstrating that the DEYO series achieves state-of-the-art real-time detection performance. The second training phase completes on a single 8GB RTX 4060 GPU, substantially lowering computational expenses.
Introduction
Object detection serves as a foundational technology for computer vision applications such as autonomous driving and video surveillance. While transformer-based end-to-end detectors streamline pipelines by removing manual tuning steps like non-maximum suppression, they encounter substantial bottlenecks. These models rely heavily on ImageNet pre-training, which restricts backbone flexibility and increases development costs, while their Hungarian matching mechanism introduces query ambiguity and unstable early optimization that degrades pre-trained features. To address these limitations, the authors propose a step-by-step training paradigm that eliminates the need for external datasets. By first training a classic detector to initialize the backbone and neck, then freezing those components to exclusively train the decoder from scratch, they develop DEYO. This first real-time end-to-end detector with a purely convolutional encoder achieves state-of-the-art speed and accuracy without requiring non-maximum suppression.
Method
The authors leverage a two-stage training methodology, referred to as step-by-step training, to construct DEYO, a real-time end-to-end object detection model with a purely convolutional encoder. The overall framework is divided into two distinct phases, each with specific training objectives and architectural configurations. The first stage focuses on pre-training a one-to-many branch to establish a high-quality backbone and neck, while the second stage trains the one-to-one branch's decoder from scratch, utilizing the pre-trained components as a foundation.
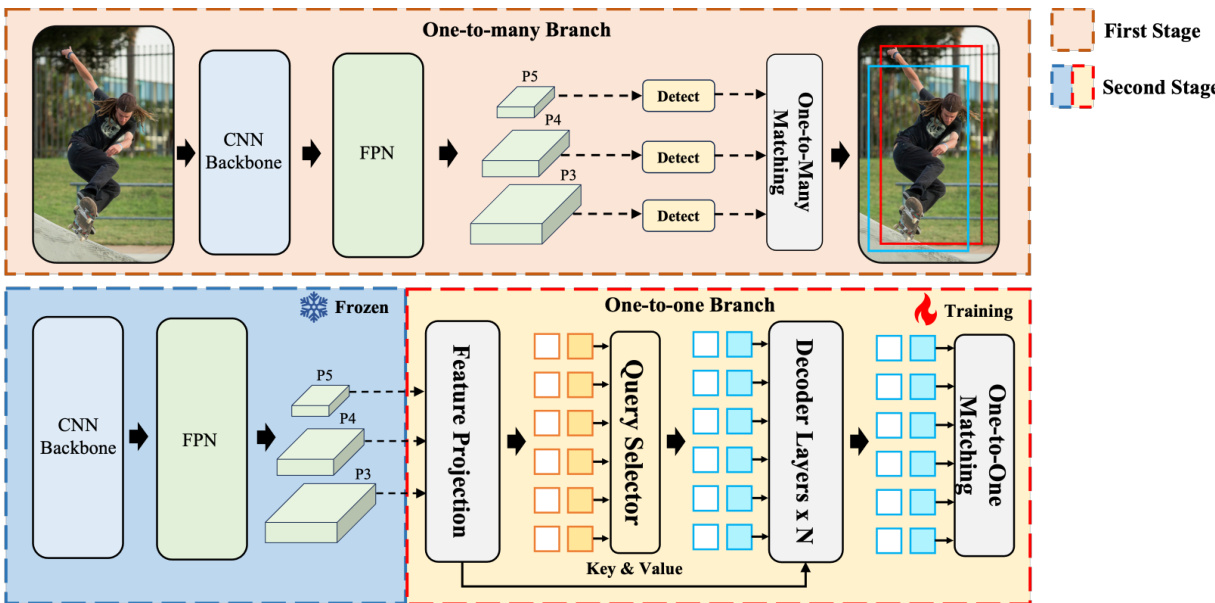
Refer to the framework diagram. The first stage of training employs a classic one-to-many detector, specifically YOLOv8, as the one-to-many branch. This branch consists of a CNN backbone, a Feature Pyramid Network (FPN), and a Path Aggregation Network (PAN) that together form the neck structure, and a head that generates predictions at three different scales. During this phase, the model is trained using a one-to-many label assignment strategy, which provides a larger number of positive samples and more comprehensive supervision, leading to a robustly pre-trained backbone and neck. This pre-trained structure is then used to initialize the corresponding components in the one-to-one branch of the final DEYO model. The outputs from this stage are the multi-scale feature maps from the neck, which are used to generate candidate regions.
The second stage of training, as shown in the framework diagram, involves the one-to-one branch, which is built upon the pre-trained backbone and neck. In this phase, the backbone and neck are frozen, meaning their parameters are not updated during training. This is a critical design choice to prevent the instability of bipartite matching in the early stages, which could otherwise degrade the quality of the pre-trained features. The training is focused solely on the decoder, which is initialized from scratch. The decoder is a Transformer-based module that operates on a set of learnable queries. The process begins with a feature projection module that transforms the multi-scale features from the frozen neck into a unified feature space. The inputs to this module are the feature maps P3, P4, and P5, which are projected into a new space S1. These are then concatenated to form S2, which serves as the key, value, and query input (Q=K=V=S2) for the decoder layers.
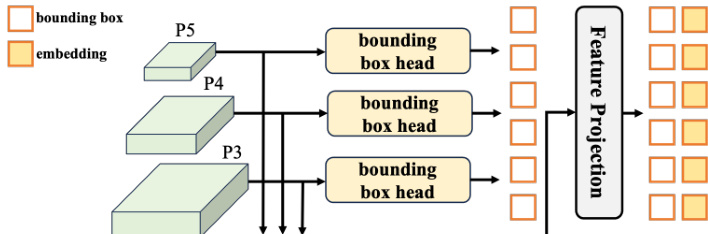
As shown in the figure below, the query generation process in DEYO is decoupled. The model separates the generation of bounding boxes from the generation of embeddings. This allows for more effective compression of multiscale information from the neck through enhanced feature projection. The one-to-many branch's pre-trained bounding box head is inherited and used to initialize the query generation process. This strategy transitions the learning of the bounding box head from a dense, many-to-one assignment to a sparse, one-to-one assignment, avoiding the need to train from scratch. The decoder layers then progressively refine the queries through self-attention mechanisms, which capture inter-query relationships and suppress redundant predictions. This design enables a consistent inference speed and eliminates the need for Non-Maximum Suppression (NMS), as the final predictions are inherently one-to-one. The entire architecture is designed to be lightweight and efficient, allowing the model to achieve high performance with significantly reduced training costs.
Experiment
The evaluation setup benchmarks the DEYO architecture on the COCO and CrowdHuman datasets against leading real-time and end-to-end detectors, utilizing a step-by-step training strategy to validate its effectiveness in both standard and dense object detection scenarios. Qualitative analysis confirms that this progressive training approach, combined with a pre-trained neck and stabilized second-stage optimization, effectively overcomes the supervisory signal limitations typical of transformer-based models while enabling robust data augmentation without performance degradation. Overall, the experiments demonstrate that DEYO achieves a superior accuracy-speed trade-off and significantly reduces computational overhead compared to existing methods, highlighting its plug-and-play compatibility and strong potential for resource-constrained or custom dataset applications.
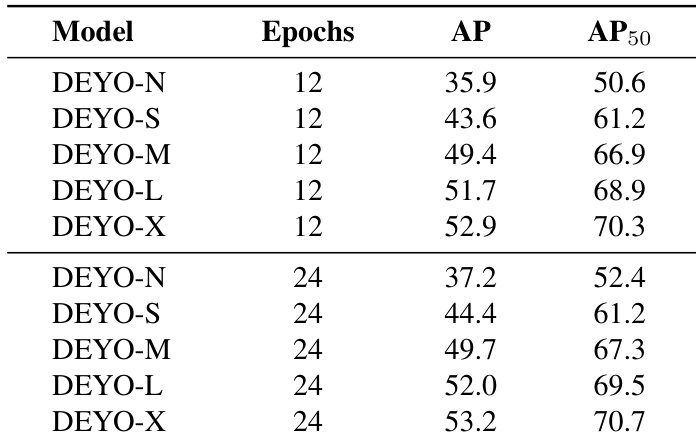
The authors present experimental results comparing the performance of DEYO models at different scales trained for varying numbers of epochs. Results show that increasing the training epochs from 12 to 24 leads to consistent improvements in both AP and AP50 across all model scales, with larger models generally achieving higher performance metrics. The authors use these results to analyze the impact of training duration on model accuracy. Increasing training epochs from 12 to 24 consistently improves AP and AP50 across all DEYO model scales. DEYO-X achieves the highest AP and AP50 values among all evaluated models. Larger models like DEYO-L and DEYO-X show better performance compared to smaller variants like DEYO-N and DEYO-S.
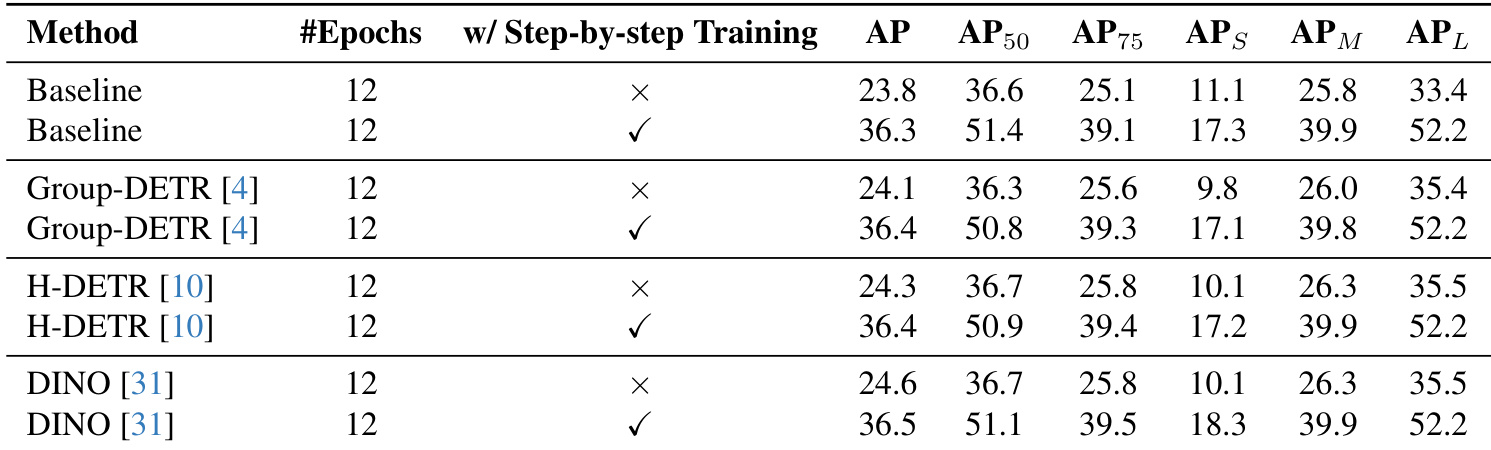
The authors compare different training strategies and methods on the CrowdHuman dataset, focusing on the impact of step-by-step training. Results show that using step-by-step training consistently improves performance across all methods, with the largest gains observed in the DINO and H-DETR models. The Baseline method without step-by-step training performs significantly worse, highlighting the importance of this training strategy for achieving high accuracy. Step-by-step training significantly improves performance across all evaluated methods. The Baseline method without step-by-step training shows the lowest accuracy, indicating its importance. DINO and H-DETR benefit the most from step-by-step training, showing substantial performance improvements.
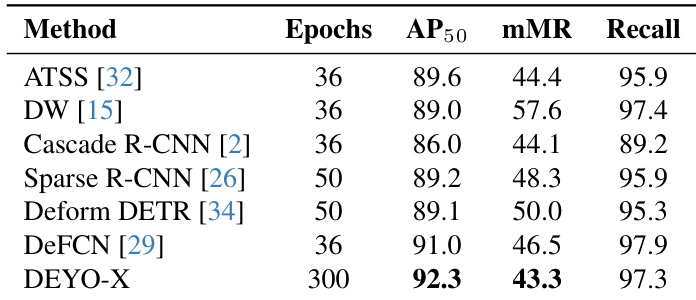
The authors compare DEYO-X with several existing methods on a benchmark, showing that DEYO-X achieves higher AP50 and recall while using more epochs than the other methods. Results show that DEYO-X outperforms the competitors in terms of AP50 and recall, with a notable improvement in AP50 compared to methods like Deform DETR and DW. DEYO-X achieves the highest AP50 and recall among the compared methods. DEYO-X uses significantly more epochs than the other methods, indicating a longer training process. DEYO-X shows a substantial improvement in AP50 over methods like Deform DETR and DW.
{"summary": "The authors compare DEYO, a query-based object detector, with classic YOLOv8 models on the COCO dataset, highlighting DEYO's superior accuracy and speed across various scales. The results show that DEYO achieves higher average precision and recall while maintaining faster inference speeds compared to YOLOv8, with performance improvements increasing as model scale grows.", "highlights": ["DEYO achieves higher accuracy and recall than YOLOv8 across all scales while maintaining faster inference speeds.", "DEYO shows improved performance with increasing model scale, particularly in accuracy and recall metrics.", "DEYO demonstrates a better trade-off between accuracy and speed compared to YOLOv8, especially in larger model variants."]
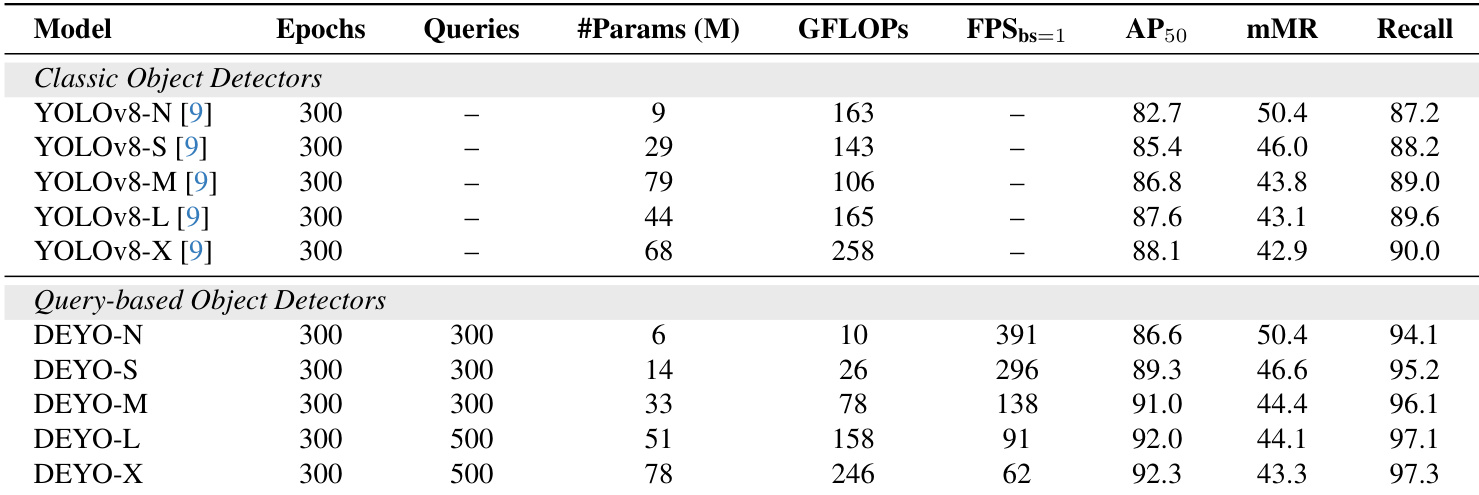
The authors conduct experiments on COCO and CrowdHuman datasets to evaluate the performance of DEYO in object detection tasks, comparing it with YOLOv8 and RT-DETR. The results show that DEYO achieves higher accuracy and speed, particularly in dense detection scenarios, and demonstrates strong performance with a consistent input size. The ablation study highlights the importance of the pre-trained Neck and step-by-step training strategy in improving model performance. DEYO achieves higher AP50 compared to the baseline model when using a pre-trained Neck. The use of a pre-trained Neck significantly improves the performance of DEYO. DEYO demonstrates strong performance in dense detection scenarios with real-time speed.

The experiments evaluate DEYO across multiple model scales and training configurations, validating that extended training durations and larger architectures consistently enhance detection accuracy. Comparative analyses against established methods on standard benchmarks demonstrate that DEYO achieves superior accuracy and real-time inference speed, particularly in dense object detection scenarios. Ablation studies further confirm that structured training protocols and a pre-trained neck module are critical drivers of this performance gain. Overall, the results establish DEYO as a scalable and efficient detector that outperforms existing baselines while maintaining a favorable balance between precision and computational efficiency.