Command Palette
Search for a command to run...
Code2LoRA:软件演化下代码语言模型的超网络生成适配器
Code2LoRA:软件演化下代码语言模型的超网络生成适配器
Liliana Hotsko Yinxi Li Yuntian Deng Pengyu Nie
摘要
代码语言模型需要仓库级别的上下文以解析导入、API及项目规范。现有方法将此类知识作为长输入注入(通过RAG或依赖分析检索),或通过对各仓库进行微调及LoRA实现——在仓库规模下成本高昂,且对不断演进的代码库缺乏鲁棒性。我们提出Code2LoRA,这是一种超网络框架,可生成特定于仓库的LoRA适配器,从而在零推理时间token开销的情况下有效注入仓库知识。Code2LoRA支持两种使用场景:Code2LoRA-Static将单个仓库快照转换为适配器,适用于对稳定代码库的理解;而Code2LoRA-Evo维护一个由GRU隐藏状态支持的适配器,该状态随每次代码差异(diff)进行更新,适用于对演进中代码库的活跃开发。为将Code2LoRA与参数高效微调基线进行对比评估,我们构建了RepoPeftBench,这是一个包含604个Python仓库的基准测试,设有两个赛道:静态赛道包含40K训练任务与12K测试断言补全任务,演进赛道包含215K基于提交(commit)的训练任务与87K基于提交的测试任务。在静态赛道上,Code2LoRA-Static实现了63.8%的跨仓库与66.2%的仓库内精确匹配,达到了单仓库LoRA上限;在演进赛道上,Code2LoRA-Evo实现了60.3%的跨仓库精确匹配(相较于单一共享LoRA提升5.2个百分点)。Code2LoRA的代码托管于https://anonymous.4open.science/r/code2lora-6857;模型检查点及RepoPeftBench数据集托管于https://huggingface.co/code2lora。
一句话总结
Code2LoRA 是一个超网络框架,用于生成仓库特定的 LoRA 适配器,以零推理时间 token 开销注入代码库上下文。该框架通过 Code2LoRA-Static 动态适配稳定快照,或通过 GRU 更新的 Code2LoRA-Evo 处理持续演进的差异提交,从而规避了高昂的微调成本与脆弱的检索流水线。在 RepoPeftBench 基准测试中,其在静态轨道上实现了 66.2% 的仓库内精确匹配率,在演进轨道上实现了 60.3% 的跨仓库精确匹配率。
核心贡献
- Code2LoRA 是一个超网络框架,用于生成仓库特定的 LoRA 适配器,以零推理时间 token 开销将项目上下文注入代码语言模型。它包含一个静态变体,用于映射单一仓库快照;以及一个演进变体,通过维护按代码差异更新的 GRU 隐藏状态来支持活跃开发。
- 引入 RepoPeftBench 作为包含 604 个 Python 仓库的基准测试,其具备独立的静态与演进轨道,涵盖数千个基于断言补全和提交派生的任务。该数据集包含一个 92 个仓库的时序保留划分,用于评估在演进代码库上的分布外泛化能力。
- 评估结果表明,该框架在静态轨道上比现有的上下文注入和参数高效微调基线高出 9.9 个百分点,在演进轨道上高出 5.2 个百分点。演进变体在仓库内任务上达到了每仓库 LoRA 的上限性能,同时在时序分布外保留集上保持了较高的准确率。
引言
代码语言模型需要深入的仓库级上下文以准确解析导入语句、API 和项目特定规范,因此有效的知识注入对于可靠的代码辅助至关重要。先前的方法通常依赖检索增强生成或依赖分析来填充海量上下文窗口,这会消耗大量计算资源并影响检索准确率,而针对每个仓库进行微调或 LoRA 适配在代码库演进时显得成本高昂且脆弱。作者利用超网络生成仓库特定的 LoRA 适配器,将知识直接注入模型参数中,推理时不产生额外 token 开销。作者提出了 Code2LoRA,该框架包含用于稳定仓库的静态模式和用于代码差异到达时通过 GRU 隐藏状态更新适配器的演进模式,并引入名为 RepoPeftBench 的新基准测试,以严格评估软件演进下的参数高效适配能力。
数据集

-
数据集构成与来源 作者构建了 RepoPeftBench,这是一个包含 604 个来自 GitHub 的 Python 仓库的仓库级基准测试。所有仓库均遵循共享的质量过滤标准,要求使用
pytest或unittest、采用宽松许可证且具有近期活跃度。语料库以 2025 年 4 月 1 日为时间截断点划分为分布内与分布外子集,数据收集同时捕获最终仓库快照与完整提交历史。 -
子集详情
- 分布内子集包含 512 个在截断点之前收集的仓库。这些仓库必须拥有至少 300 个星标,并经过 MIT 许可证的硬性过滤。该子集提供所有训练与验证数据,提交历史截断至截断日期。
- 分布外子集由 92 个严格在截断点之后创建的仓库组成。这些仓库不受星标数量要求限制,候选仓库从 6 个星标开始搜索,且可能采用 MIT 或 Apache-2.0 许可证。该集合专门用于保留的测试期评估。
-
数据使用与划分
- 作者将 512 个分布内仓库划分为跨仓库与仓库内集合。跨仓库集合在训练期间完全保留 103 个仓库,划分为 51 个验证仓库和 52 个测试仓库,以评估对未见代码库的泛化能力。仓库内集合使用剩余的 409 个仓库进行训练,并支持每仓库 LoRA 适配。
- 两个评估轨道共享这些仓库划分,但在实例索引上有所不同。静态轨道从每个仓库的单一快照中提取实例,生成 62,294 个任务。对于仓库内划分,实例以 8:1:1 的比例随机划分。演进轨道重播提交历史,并在提交添加或修改断言时生成任务。对于仓库内划分,提交按时间顺序划分,以确保训练示例严格早于验证和测试数据。
- 演进轨道在训练期间应用智能上限,将每个提交的限制为最多八个任务,每个测试文件限制为四个任务,以防止主导性提交扭曲反向传播窗口。
-
处理与元数据
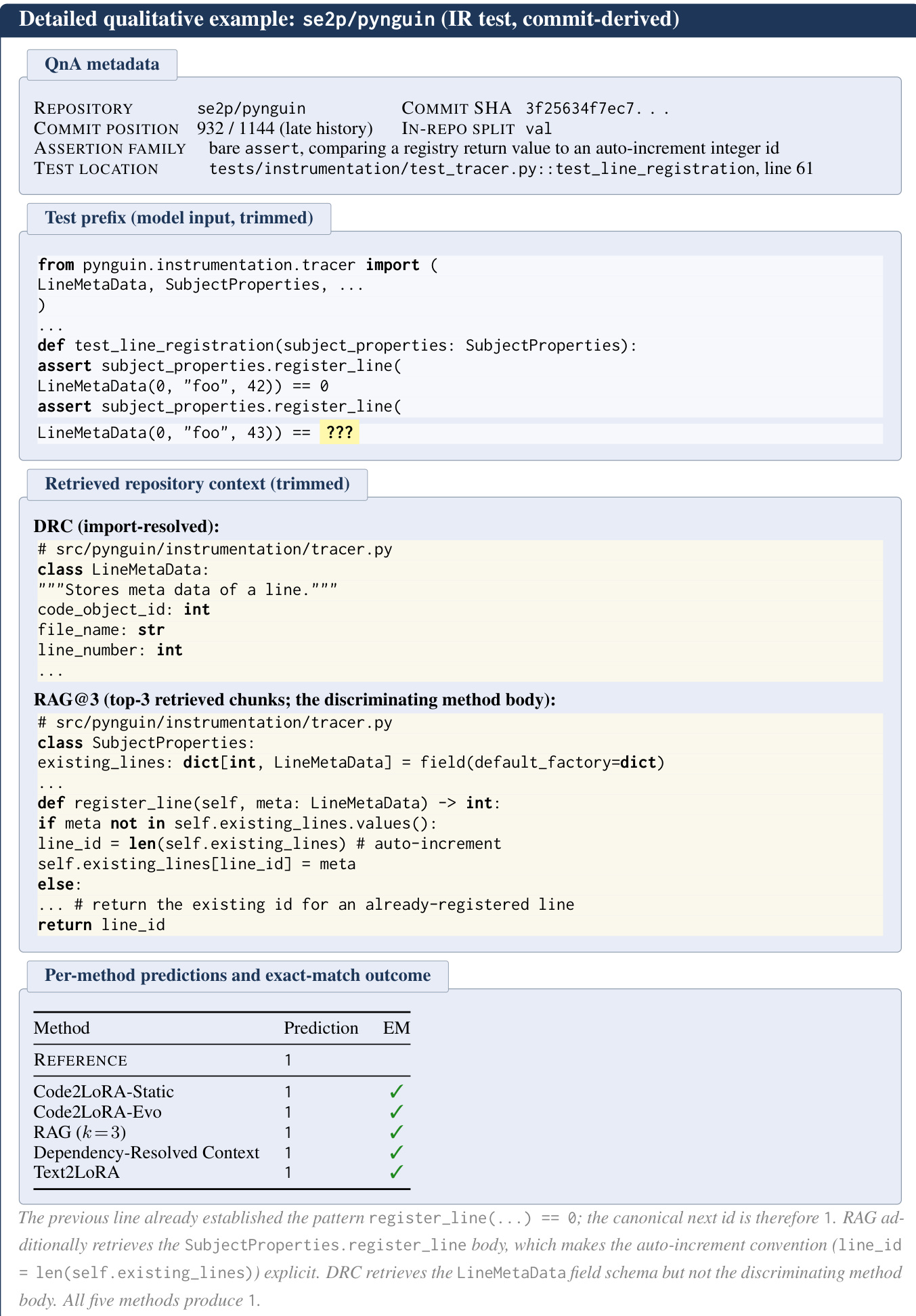
- 每个实例代表一个断言补全任务,模型根据结构化前缀预测断言的预期值。输入拼接了导入语句、封闭类、辅助方法以及断言截断点之前的测试函数体。输出对应于比较运算符的右侧或断言函数的最后一个参数。
- 实例从五个断言家族中挖掘:
bare assert、self.assert*、unittest.raises、unittest.assert*和NumPy-style assert_*。 - 流水线应用过滤规则以排除格式错误的目标,包括以逗号开头、位于函数体之外、为空、在函数内重复或仅包含标点符号的情况。
- 元数据统计显示,中位仓库大小为 165K token,中位前缀长度为 224 token,中位目标长度为三个 token。64.1% 的配对拥有依赖解析上下文。数据集发布保留了 LICENSE 文件和源代码原文,未进行个人信息脱敏,以保留预测任务所需的关键标识符。
方法
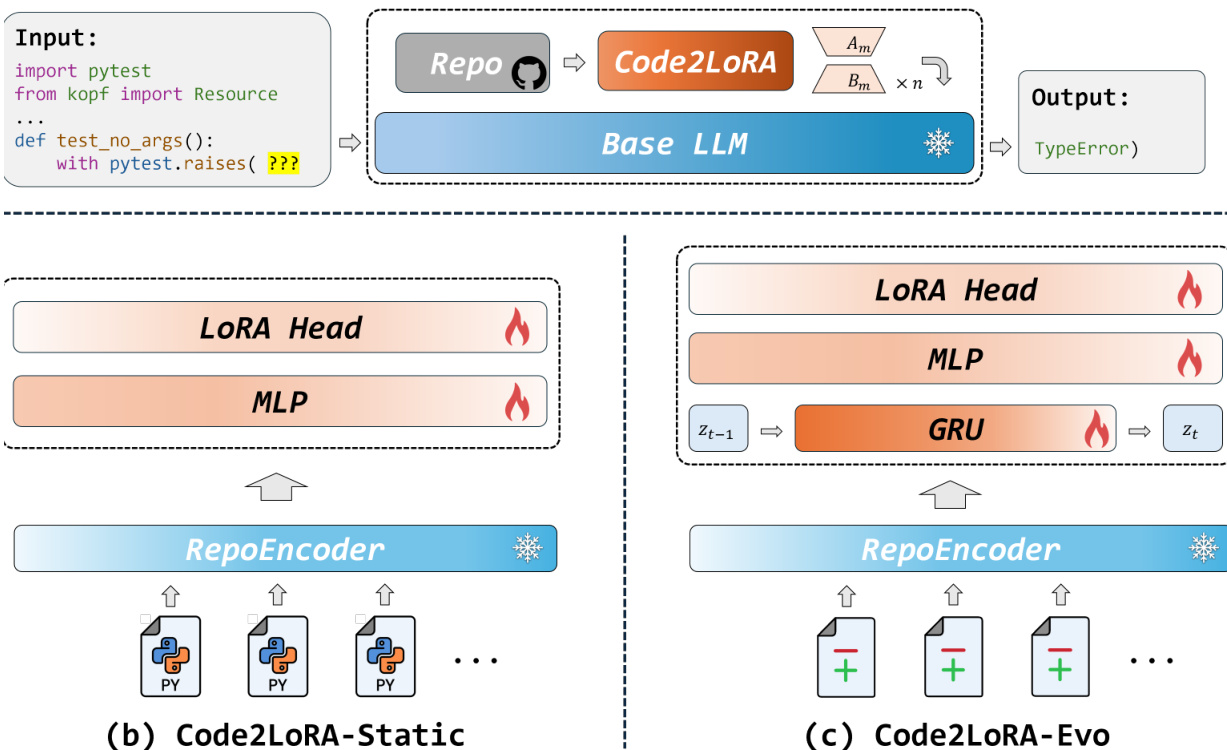
Code2LoRA 框架是一种基于超网络的方法,旨在为冻结的代码语言模型生成仓库特定的 LoRA 适配器,从而实现以零推理时间 token 开销注入仓库级知识。整体架构如图 1a 所示,包含三个主要组件:处理仓库级上下文为密集嵌入的共享仓库编码器、将这些嵌入映射为 LoRA 权重的超网络,以及接收生成的适配器进行推理的冻结基础 LLM。仅训练超网络,而仓库编码器和基础 LLM 在整个过程中保持冻结。该框架支持两种不同的使用场景:Code2LoRA-Static,从静态仓库快照生成单一适配器;以及 Code2LoRA-Evo,通过顺序代码差异维护仓库演进过程中的动态适配器轨迹。
仓库编码器详见 3.1 节,通过一个两步且无需训练的过程,利用冻结的 Qwen3-Embedding-0.6B 模型将仓库级上下文压缩为固定大小的向量。首先,将仓库中的每个文件划分为 4096-token 块(重叠 512-token),进行嵌入并执行均值池化以生成文件级向量。其次,通过计算加权均值和最大池化将这些文件向量聚合为仓库级嵌入,以捕捉代码库的平均特征与最显著特征。聚合权重基于内容独特性、文件大小和路径重要性综合确定。生成的仓库嵌入,e,在离线阶段预计算并存储,供训练和推理使用。
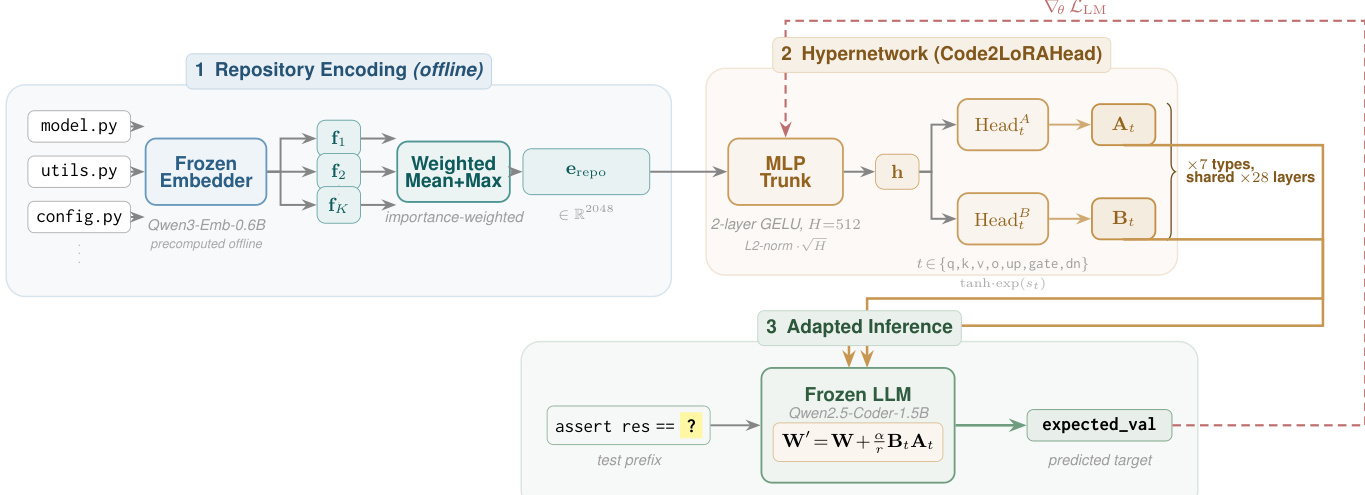
对于 Code2LoRA-Static 变体,超网络如图 1b 所示,将单一仓库嵌入 e 作为输入,并通过单次前向传播生成 LoRA 适配器。该过程通过一个共享的 2 层 MLP(带 GELU 激活函数)实现,后接针对七种模块类型(query、key、value、output、gate、up、down)的专用输出头。MLP 主干的隐藏表示 h 经过 L2 归一化并乘以 dh 进行缩放。每种模块类型 m 的 LoRA 矩阵 Am 和 Bm 随后通过 tanh(HeadmA(h))⋅exp(smA) 和 tanh(HeadmB(h))⋅exp(smB) 生成,其中 smA/B 为控制适配器幅度的可学习对数缩放参数。生成的 LoRA 权重通过标准 LoRA 更新规则 W′=W+rαBmAm 注入基础 LLM。
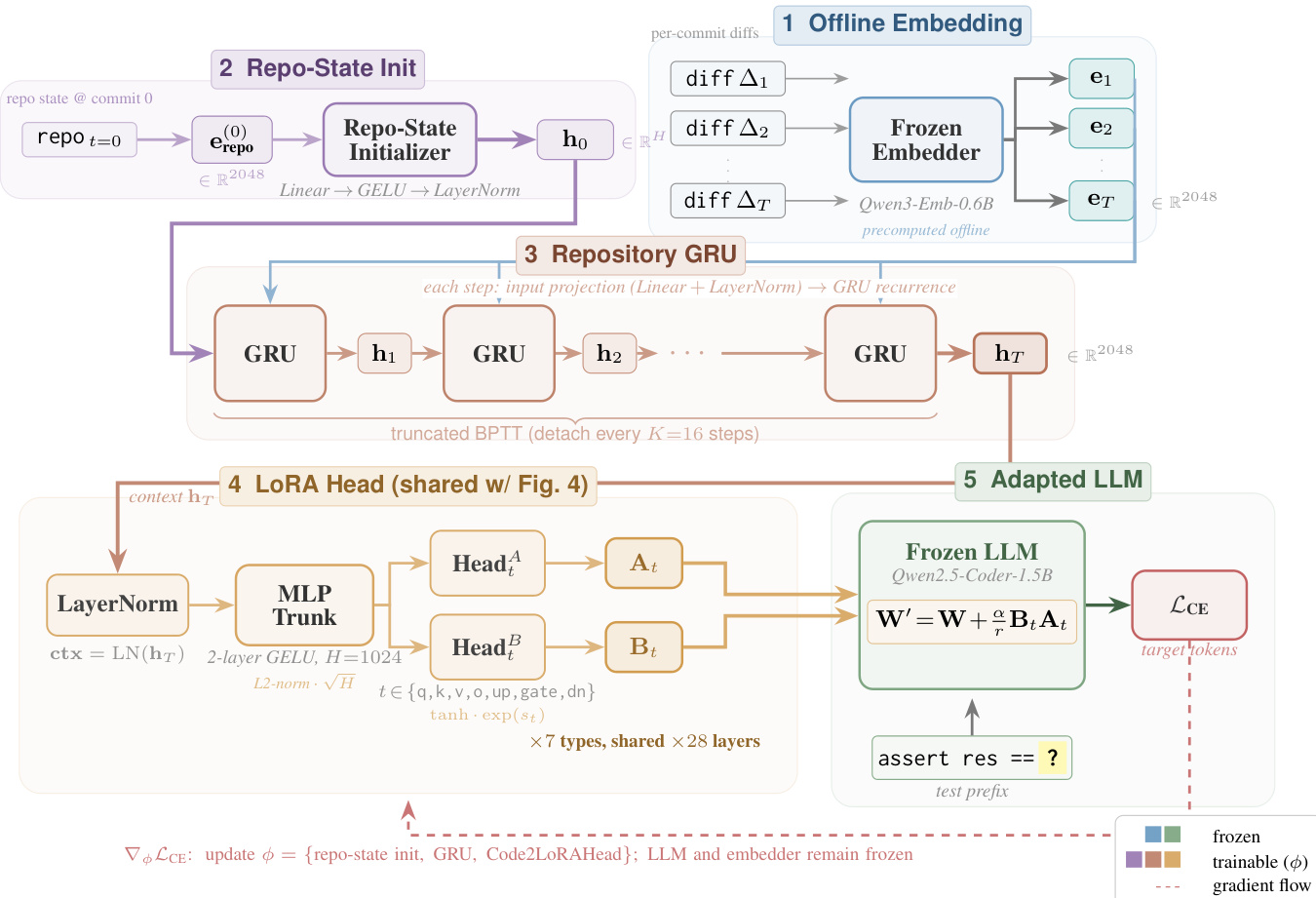
Code2LoRA-Evo 变体如图 1c 所示,将静态方法扩展至软件演进建模。它通过差异嵌入序列 {et} 维护仓库特定的适配器。该过程通过在仓库编码器与 LoRA 生成头之间插入 GRU 循环神经网络实现。在每个步骤 t,GRU 接收线性投影的差异嵌入 et,并将其与前一隐藏状态 zt−1 结合以生成当前状态 zt。初始 GRU 状态 z0 通过一个小型线性投影器初始化,该投影器映射初始仓库嵌入。在每个步骤,LoRA 适配器由与 Code2LoRA-Static 相同的共享头生成,但使用当前 GRU 状态 zt 作为输入。该过程在仓库生命周期内产生适配器轨迹,使模型能够按提交逐步适配代码变更。
训练过程详见 3.4 节,通过最小化来自冻结基础 LLM 的断言补全对的交叉熵损失进行端到端训练。损失函数定义为 L(θ)=−∑(x,y)∈Dlogp(y∣x;Hypernetworkθ(u)),其中 u 为超网络的输入。对于 Code2LoRA-Static,u 为仓库嵌入 e,而对于 Code2LoRA-Evo,u 为当前 GRU 隐藏状态 zt。为管理数据的顺序特性,Code2LoRA-Evo 采用截断的随时间反向传播,每隔 K=16 步分离隐藏状态。批次通过采样一个仓库及其一对输入输出构成,以确保多样化的暴露并防止对数据丰富仓库的过拟合。超网络使用 AdamW 进行训练,采用余弦学习率调度与 0.01 的权重衰减,基础 LLM 和仓库编码器保持冻结。
实验
评估利用 RepoPeftBench 基准测试,涵盖静态、演进提交与分布外时序轨道,以验证仓库级代码适配策略。结果表明,通过生成 LoRA 的超网络进行的参数适配持续优于上下文注入和全微调基线,有效转移了跨仓库知识,同时规避了每仓库训练观察到的严重过拟合现象。此外,演进变体成功聚合顺序代码差异以缓解模型陈旧性,在仓库生命周期和未见代码库上保持了稳健性能。结构与部署分析进一步证实,生成的适配器保持语义多样性与高度效率,与传统微调方法相比需要可忽略的推理开销。
作者在不同仓库适配任务上评估 Code2LoRA 变体,比较静态与演进代码场景。结果表明参数适配优于上下文注入,且对提交差异的循环聚合提升了演进仓库的性能。Code2LoRA-Evo 在两个轨道上均取得最佳结果,在不同仓库类型中保持一致的性能提升,且随时间推移漂移极小。参数适配方法在静态与演进轨道上均优于上下文注入技术。Code2LoRA-Evo 通过聚合提交历史在演进仓库上展现出持续优势。Code2LoRA 变体在不同仓库类型间保持高性能,且每仓库方差极小。
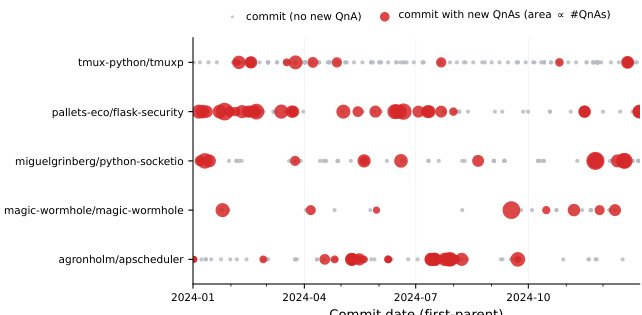
作者在不同仓库级代码补全任务上评估 Code2LoRA 变体,将其性能与多种基线在静态与演进仓库场景下进行对比。结果表明参数适配方法优于上下文注入方法,Code2LoRA-Evo 因其聚合提交历史的能力在演进设置中展现出优越性能,而 Code2LoRA-Static 在静态快照上实现了强大的跨仓库泛化。参数适配方法在静态与演进轨道上均优于上下文注入方法。Code2LoRA-Evo 通过利用提交差异的循环聚合在演进任务上取得最高性能。Code2LoRA-Static 在无需每仓库训练的情况下,在仓库内评估中达到了与每仓库 LoRA 相当的性能。
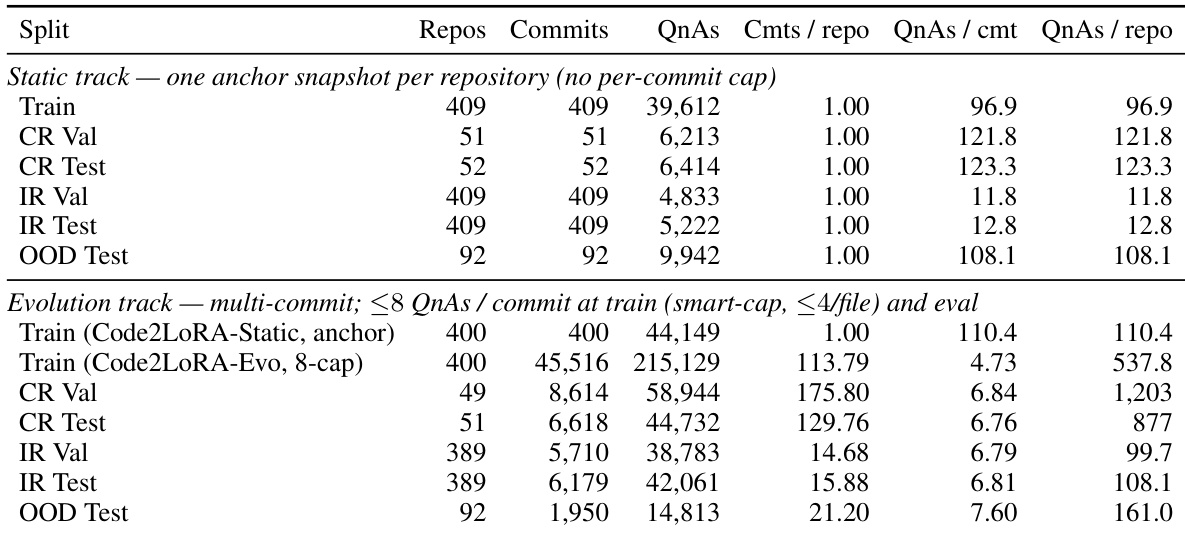
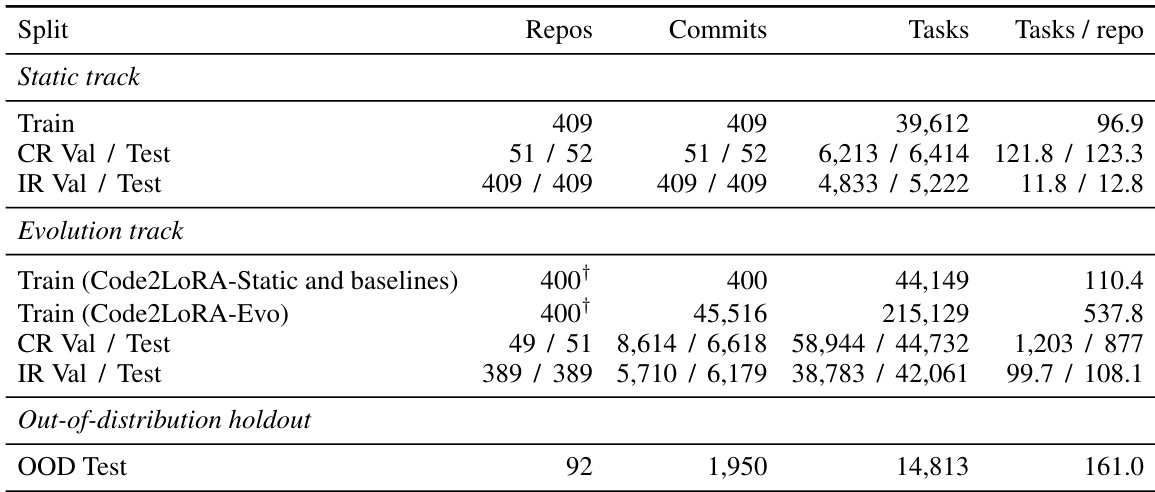
该表格展示了 RepoPeftBench 的数据集统计信息,划分为静态与演进轨道。静态轨道使用每个仓库的单一快照与一个锚定提交,而演进轨道涉及多个提交,并对每个提交的问答数量应用智能上限,训练集与测试集划分中每个仓库的问答数量更多。两个轨道共享相同的分布内仓库集合,但在每个提交的提交数量与问答数量上有所不同,演进轨道显示更高的提交与问答数量。静态轨道使用每个仓库的一个锚定快照,每个提交的问答数量一致,而演进轨道涉及多个提交且每个提交的问答数量更高。演进轨道中每个仓库的问答数量显著高于静态轨道。两个轨道共享相同的分布内仓库集合,但在每个提交的提交数量与问答数量上有所不同,演进轨道显示更高的提交与问答数量。
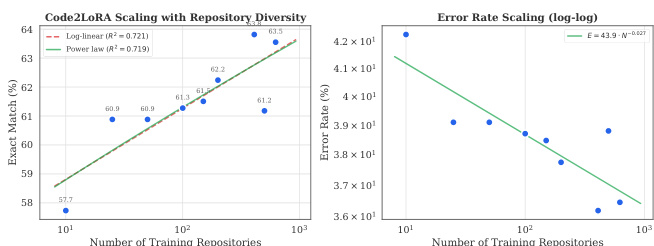
实验考察了训练仓库多样性对模型性能的影响,表明性能随仓库数量增加而提升,且错误率随训练仓库数量增加而下降。结果表明模型从多样化的仓库集合中受益,性能在数百个仓库时趋于饱和。性能随仓库多样性增加而提升,在约 200 个仓库前呈现对数线性趋势。错误率随训练仓库数量增加而下降,表明使用更多样化数据时泛化能力更强。性能在数百个仓库时趋于饱和,表明超出该点后收益递减。
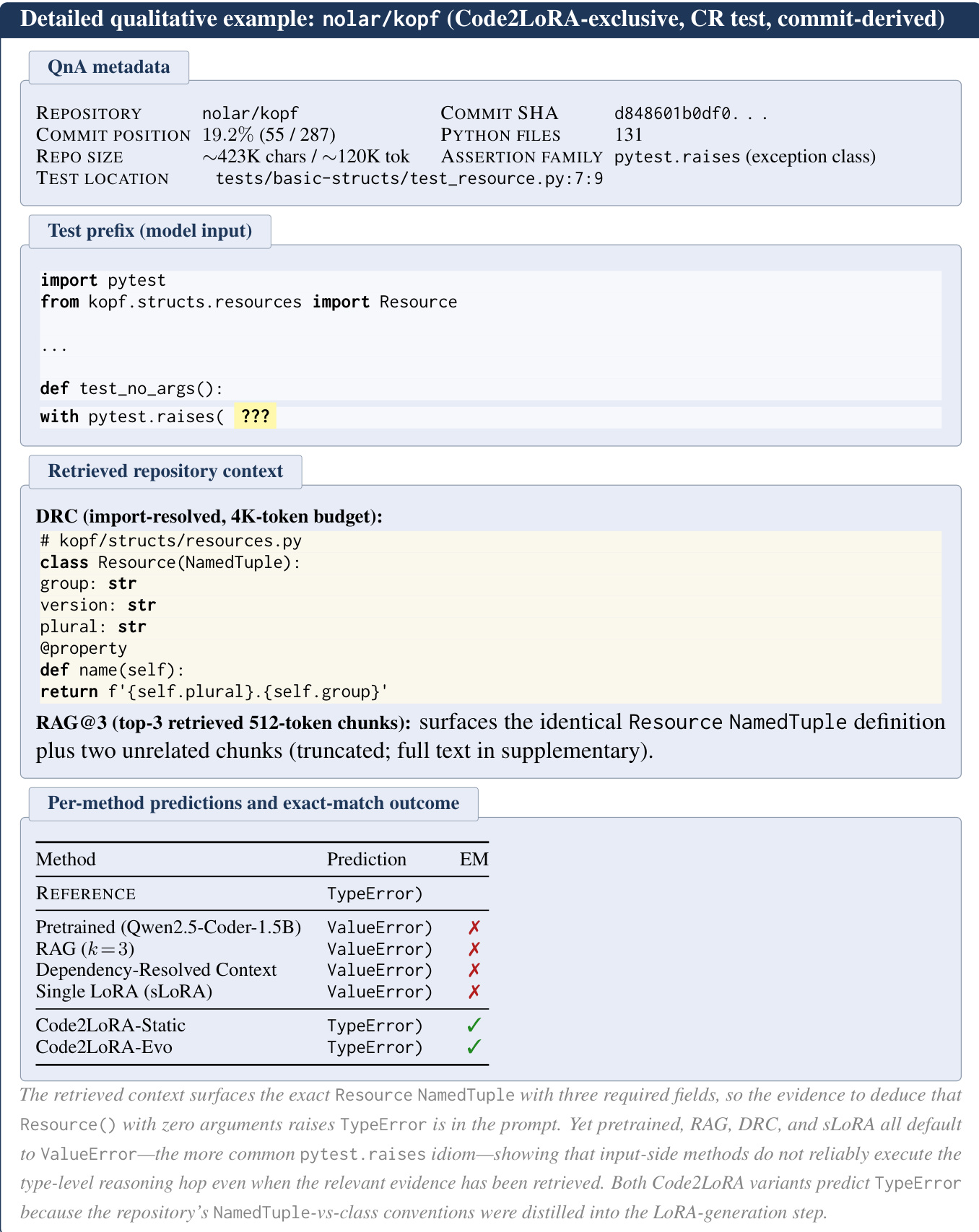
实验在静态、演进与分布外设置下评估 Code2LoRA 变体在仓库级代码补全任务上的表现,并与全微调、上下文注入及每仓库适配等多种基线进行对比。结果表明参数适配方法,尤其是 Code2LoRA,优于基于上下文的方法,Code2LoRA-Evo 因其整合提交历史的能力在演进仓库上取得最佳性能。该框架展现出强大的泛化与效率,生成仓库特定适配器无需每仓库训练或额外推理 token。Code2LoRA 变体在静态与演进轨道上均优于上下文注入与全微调方法,Code2LoRA-Evo 在演进仓库上取得最高性能。Code2LoRA 的静态变体在无需每仓库训练的情况下,在仓库内任务上达到了与每仓库 LoRA 相当的性能,证明了有效的跨仓库知识转移。Code2LoRA-Evo 在提交时间线上保持持续优势,相比静态适配方法陈旧性极小,并在分布外仓库上取得最佳结果。
评估在静态快照与演进提交历史上检验 Code2LoRA 变体在仓库级代码补全上的表现,将其与上下文注入、全微调和每仓库适配基线进行基准测试。结果表明参数适配持续优于基于上下文的方法,演进变体利用提交历史随时间维持稳定准确率,而静态变体在无需每仓库训练的情况下有效实现跨仓库泛化。此外,实验验证了模型性能随训练数据多样性增加而提升直至趋于平稳,最终证实了该框架在多样化与分布外代码库上的效率与强大泛化能力。