Command Palette
Search for a command to run...
AdaPlanBench:评估世界与用户约束下大语言模型 Agent 的自适应规划
AdaPlanBench:评估世界与用户约束下大语言模型 Agent 的自适应规划
摘要
语言模型针对现实世界问题进行规划通常同时涉及环境约束与用户约束,这些约束往往无法在初期完全明确,而是通过交互过程逐步揭示。然而,现有基准测试对于此类逐步揭示的双重约束下的自适应规划研究仍显不足。为弥补这一研究空白,我们提出了AdaPlanBench,这是一个动态交互基准测试,旨在评估大型语言模型(LLM)agents能否在逐步揭示的环境约束与用户约束下进行自适应规划与重规划。AdaPlanBench基于307项家庭任务构建,并采用可扩展的约束构建流程,为每项任务附加双重约束。在运行阶段,agents通过多轮协议与环境进行交互,隐藏约束仅在agent提出违反该约束的计划时才会被揭示,这要求agents在反馈不断累积的情况下进行迭代式的计划修订。这显著增加了规划难度,因为agents必须在有效重规划的同时,从反馈中推断并持续追踪相关约束。在十款主流LLM上的实验结果表明,双重约束下的自适应规划依然极具挑战,表现最佳的模型准确率仅为67.75%。我们进一步观察到,随着约束数量的累积,模型性能呈现下降趋势;其中用户约束带来的挑战尤为突出,失败案例多源于物理 grounding 较弱及执行有效性降低。上述结果确立了AdaPlanBench作为双重约束交互规划测试平台的地位,并凸显了LLM agents在动态适应逐步揭示的约束时所面临的可靠性挑战。
一句话总结
作者提出了 AdaPlanBench,这是一个基于 307 项家庭任务构建的动态交互基准测试。该基准通过多轮协议评估了十款领先的大语言模型 Agent 在逐步揭示的世界约束与用户约束下的自适应规划能力。在该协议中,隐藏约束仅在违反时才会被披露。结果表明,即使表现最佳的模型在持续积累反馈并迭代修改计划的情况下,准确率也仅为 67.75%。
核心贡献
- 本研究引入了 AdaPlanBench,这是一个动态交互基准测试,旨在评估大语言模型 Agent 在世界约束与用户约束于交互过程中逐步披露时,如何进行自适应规划与迭代策略修订。
- 该基准测试采用可扩展的约束构建流水线,为 307 项家庭任务增加了双重约束,并实现了一套多轮运行时协议。该协议仅在计划违反后披露隐藏规则,以强制实施持续的反馈驱动重规划。
- 针对十款主流语言模型的评估表明,在动态演化的双重约束下进行自适应规划仍是一项重大挑战。表现最佳的模型准确率仅为 67.75%,且在约束不断累积时难以有效修订计划。
引言
大语言模型 Agent 正日益被部署于需要与用户及外部环境进行持续交互的复杂现实任务中,这使得自适应规划成为一项关键能力。现有的评估框架通常将用户偏好或世界限制单独隔离,并假设所有约束均为预先已知。这导致在 Agent 如何应对需要迭代重规划的动态披露双重约束方面,存在显著的研究空白。为弥补这一局限,作者引入了 AdaPlanBench。这是一个动态交互基准测试,用于在 307 项增加了可扩展双重约束的家庭任务中评估大语言模型 Agent。该基准测试仅在提议的操作违反约束时逐步披露隐藏约束,从而迫使 Agent 持续跟踪反馈并修订计划。该设置提供了一个严格的测试平台,用于衡量当前模型适应累积且部分可观测约束的能力,这些约束正是定义现实 Agent 工作流的关键要素。
数据集

数据集构成与来源
- 作者基于 MacGyver 数据集构建 AdaPlanBench,专门针对环境与基于偏好的约束自然交叉的家庭任务。
- 每个基准测试实例将一个重写后的家庭查询与一个双重约束配置文件配对,该文件明确追踪不可用工具与用户偏好。
子集详情与过滤规则
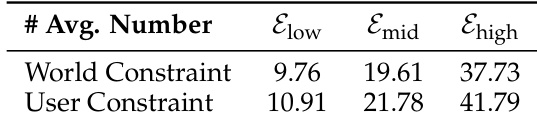
- 数据集根据约束密度划分为三个难度层级(Elow、Emid 和 Ehigh),具体实例数量记录于论文的补充表格中。
- 原始查询经过严格的二元过滤,仅保留具体的多步规划任务。作者明确排除了以知识为中心的问题、外部委托的解决方案、规定方法的指令以及主观装饰性过强的提示,以保留开放式的动作空间。
数据使用与评估协议
- 作者仅将 AdaPlanBench 用作评估基准而非训练语料,因此未应用任何训练集划分或混合比例。
- Agent 通过运行时交互协议进行测试,该协议逐步披露被违反的约束,要求模型推断潜在限制并持续修订计划。
- 性能通过基于大语言模型的裁判进行评估,涵盖约束违反检测与评分量表打分,并使用人工标注来验证裁判的一致性。
处理与元数据构建
- 一个多 Agent 流水线通过迭代采样候选计划、提取工具,并将其转换为世界约束(例如环境不可用)与用户约束(例如安全或卫生偏好)来构建数据集。
- 作者采用专用模型在多次采样轮次中合并、规范化并去重约束,随后进行最终验证步骤,移除模糊或逻辑矛盾的偏好集合。
- 该基准测试采用纯文本格式运行,刻意排除视觉或具身组件,以隔离在逐步披露约束下的规划能力。未使用裁剪策略,但逐步披露约束的机制构成了核心的运行时处理特性。
方法
AdaPlanBench 的框架旨在评估交互环境中的自适应规划 Agent。该环境以双重约束(世界约束与用户约束)为特征,这些约束在交互过程中逐步披露。整体架构由数据构建流水线与运行时交互协议组成,两者均经过设计以支持迭代重规划与约束发现。
数据构建流水线始于 MacGyver 查询的生成,旨在激发复杂的现实世界规划场景。这些查询经过约束采样机制处理,该机制利用多个规划器采样器并行生成多样化的候选计划。如图所示的并行采样策略通过利用不同模型间的规划倾向差异,实现了对解空间的广泛探索。每个采样器在单次遍历中生成多个计划,从而引入采样器间的多样性与采样器内的变化。初步探索之后是约束提取阶段,从生成的计划中识别世界约束与用户约束。提取的约束随后被聚合与验证,以形成全面的环境配置文件 E。为进一步丰富约束空间,流水线采用迭代采样策略,将先前发现的约束反馈至后续规划轮次中。该反馈机制鼓励规划器探索新的可行策略,从而揭示在一次性采样方法中将被隐藏的额外约束。
在每次迭代中,世界约束与用户约束的处理分别进行,确保两种类型的约束均得到充分探索与验证。并行采样与迭代采样的结合产生了协同效应:并行采样拓宽了初始探索范围,而迭代采样则在多轮中深化探索。这种双重方法生成了更丰富且更具代表性的环境配置文件,准确捕捉了现实世界规划任务的复杂性。
框架图中展示的运行时交互协议模拟了 Agent 在多轮交互中与环境和用户的互动。在第 t 轮,Agent 基于当前已披露约束的状态生成计划 pt。该计划由两个独立的大语言模型裁判进行评估:世界约束裁判与用户约束裁判。如提示模板所述,世界约束裁判检查计划是否违反任何环境约束,例如使用禁用工具或物品。用户约束裁判则根据用户偏好评估计划,识别与噪声或安全偏好等主观约束的冲突。评估结果用于确定违反约束的集合,随后将其转换为反馈披露约束 Fi,tx 并传递给 Agent。
反馈机制旨在支持渐进式披露,即随着交互的展开逐步揭示约束。Agent 利用该反馈在后续轮次中优化计划。该过程持续进行,直到 Agent 生成满足所有约束并通过评分量表评估的计划,或满足终止条件。终止条件包括最大轮数限制,或在连续多轮未触发新约束时提前终止,以表明进展停滞。
评估指标用于衡量 Agent 性能的各项维度,包括准确率、有效计划率、平均轮数以及重复违反约束的频率。这些指标全面评估了 Agent 适应新约束、生成有效计划以及高效收敛至解决方案的能力。采用多个裁判进行基于量表的评估,确保了在不同维度上对计划质量评估的稳健性与一致性。
总体而言,AdaPlanBench 的架构旨在捕捉现实世界规划的核心特征,包括迭代重规划、用户与世界交互、双重约束、渐进式披露、开放式评估以及可扩展约束。通过隔离规划组件并抽象掉底层感知与执行过程,该基准测试实现了对复杂交互环境中自适应规划能力的专注评估。
实验
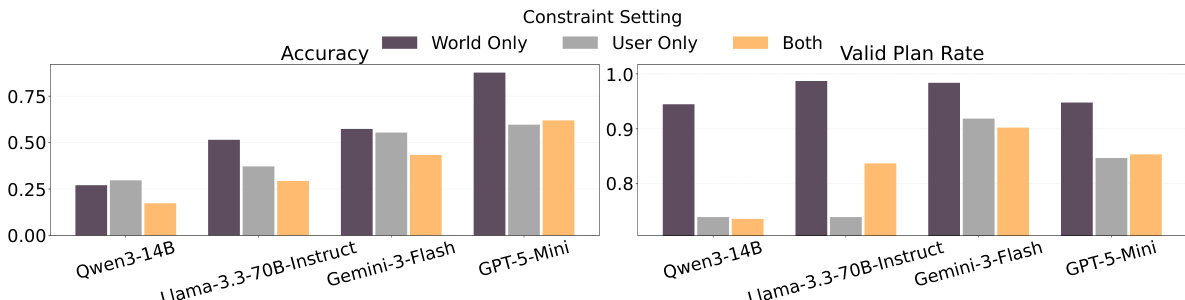
该评估在动态多轮环境中测试专有与开源的大语言模型 Agent,在此环境中,随着世界约束与用户约束的逐步披露,计划必须被持续修订。一系列改变约束复杂度、测试外部记忆模块以及隔离约束来源的实验,验证了模型如何适应累积的需求与纠正性反馈。定性来看,当前 Agent 在自适应规划方面面临显著困难,其性能随着约束负担与交互长度的增加而持续下降。最终表明,传统的模型扩展与显式约束追踪不足以保障可靠的任務成功,其中用户约束带来了不成比例的难度,且模型频繁无法维持物理一致性规划与长期计划有效性。
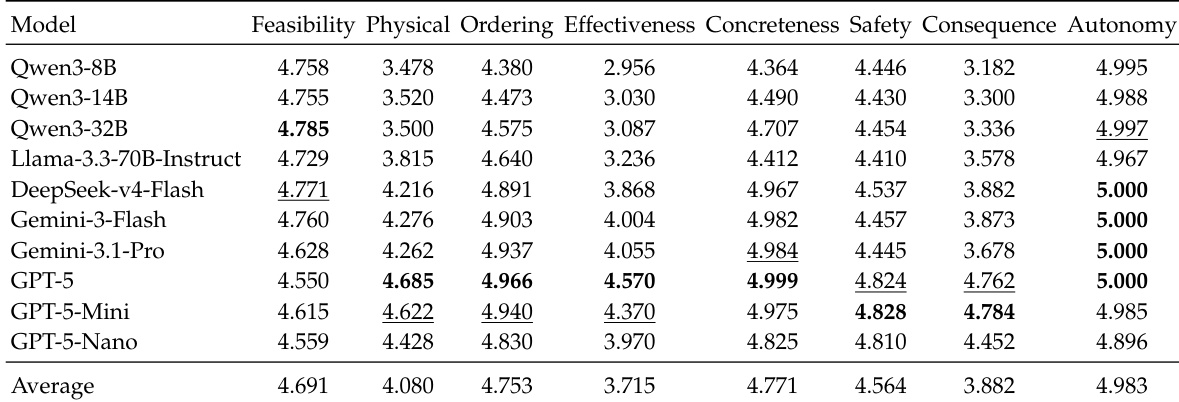
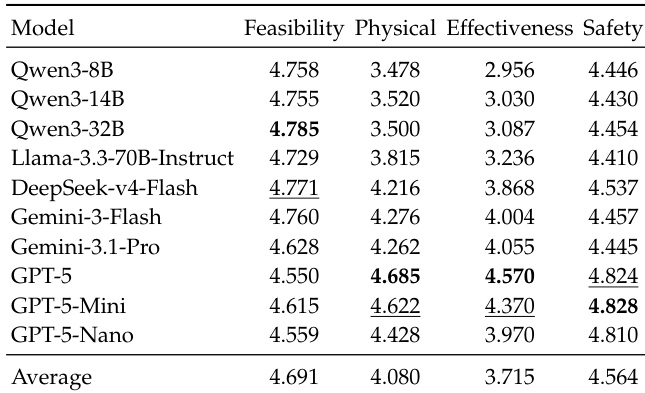
作者使用大语言模型裁判在四个评分维度(可行性、物理合理性、有效性及安全性)上评估模型性能。结果表明,模型在可行性与安全性方面表现普遍较好,而物理合理性与有效性则持续较弱。各模型表现存在差异,部分模型在特定维度得分较高,但没有任何单一模型在所有类别中均表现出色。研究结果表明,当前模型在约束密集的条件下难以维持有效且符合物理逻辑的计划。模型在可行性与安全性上表现强劲,但在物理合理性与有效性上表现较弱。没有任何模型在所有四个评分维度上持续获得高分,这表明各模型优势与劣势各异。物理合理性与有效性的表现明显偏低,反映出模型在约束条件下推理物理后果与计划有效性方面存在挑战。
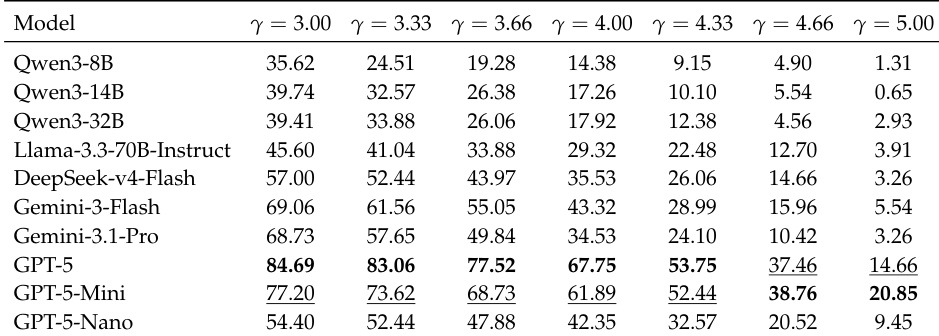
该实验评估了模型在逐步披露的双重约束下的性能,约束在交互过程中动态揭示。结果表明,随着约束数量增加,模型难以维持计划质量与约束遵循度,且随着约束复杂度上升,各项指标性能均出现下降。在约束披露方面表现出更高主动探索性的模型往往能获得更好的最终准确率。随着约束复杂度增加,性能持续下降,在约束更严格的环境中准确率和有效计划率均呈下降趋势。具有更高主动约束探索能力的模型取得了更好的最终准确率,表明探索行为与任务成功之间存在强相关性。主动披露约束与计划质量提升相关,而重复违反已披露约束仍是各模型普遍存在的持续性问题。
作者分析了多种语言模型在多轮交互中的性能,聚焦于四个评分维度:可行性、物理合理性、有效性与安全性。结果表明,模型性能总体上随时间推移而下降,其中有效性与物理合理性等维度表现出尤为急剧的下滑。表现最优的模型在多轮交互中保持了相对稳定的分数,而其他模型则显示出显著的性能衰减,这表明各模型在应对规划过程中累积约束时的韧性存在差异。随着交互推进,所有评分维度的模型性能均呈下降趋势,其中有效性与物理合理性的下降最为明显。表现最佳的模型随时间推移保持分数相对稳定,而表现较差的模型在计划质量上出现显著衰退。各模型的性能趋势各不相同,部分模型分数保持一致,而其他模型则表现出急剧下滑,尤其在后期交互轮次中更为显著。

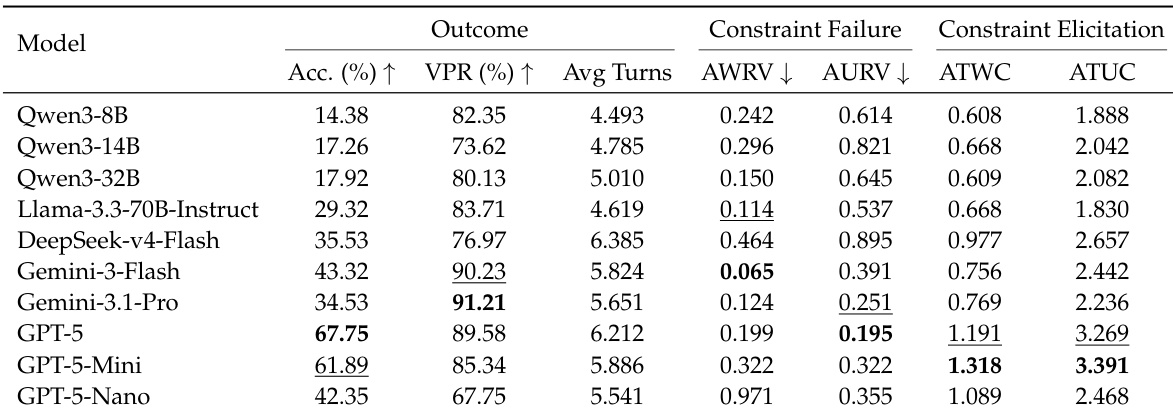
作者在一个动态规划基准测试上评估了多种语言模型,其中 Agent 必须适应逐步披露的约束。结果表明,模型在不同指标上的性能差异显著,部分模型实现了较高的有效计划率但最终准确率较低,这表明维持约束有效性与达成正确解决方案之间存在差距。该表格指出,具有更高主动约束探索能力的模型在准确率方面往往表现更佳,而重复违反已披露约束在各模型中普遍存在。高约束探索能力倾向于带来更高的准确率,表明主动探索有助于提升性能。高有效计划率并不能保证高准确率,说明约束遵循度与最终任务成功之间存在脱节。所有模型均频繁重复违反已披露的约束,凸显了在自适应规划过程中维持一致性所面临的持续挑战。
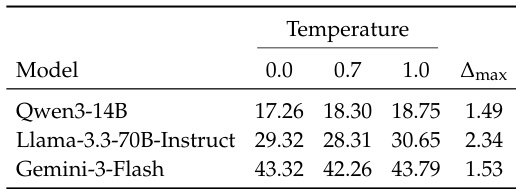
该表格展示了不同温度设置及最大偏差指标下的模型性能对比,呈现了 Qwen3-14B、Llama-3.3-70B-Instruct 和 Gemini-3-Flash 的分数变化。较高的温度设置通常会导致所有模型的分数上升,而 Δmax 指标在各模型及不同温度层级间保持相对稳定。结果表明,温度对模型输出具有一致性影响,且未引起模型相对性能排名的显著变化。所有模型的性能指标均随温度设置提高而上升。Δmax 指标在不同模型与温度设置下变化极小。无论温度如何变化,模型排名均保持一致。
实验在具有逐步披露约束的动态规划任务上评估语言模型,考察其在可行性、物理合理性、有效性与安全性维度上维持计划的能力。结果验证了尽管模型能够可靠地满足可行性与安全性要求,但随着约束复杂度与交互轮次的增加,它们在物理推理与计划有效性方面持续面临困难。主动约束探索提升了最终准确率,但维持有效计划与达成正确解决方案之间仍存在持续差距,重复的约束违反凸显了持续的一致性挑战。此外,敏感性分析证实温度调整会影响输出分数但不改变模型相对排名,这强调了当前架构在维持自适应且符合物理逻辑的规划方面仍面临根本性局限。