Command Palette
Search for a command to run...
SoCRATES:迈向跨领域与社会认知差异的大语言模型主动调解的可靠自动化评估
SoCRATES:迈向跨领域与社会认知差异的大语言模型主动调解的可靠自动化评估
Taewon Yun Hyeonseong Park Jeonghwan Choi Hayoon Park Yeeun Choi Hwanjun Song
摘要
评估大语言模型调解员仍具挑战性,因为调解过程呈现为一条实时轨迹,受争议方不断变化的情绪、意图与情境所塑造。现有测试平台主要依赖少数由专家构建的领域,主要仅在战略立场方面存在差异,且对每个话题的每一步交互均进行评分,从而引入了离题噪声。本文提出SoCRATES基准,用于在贴近现实的多领域测试平台中评估主动式大语言模型调解员。该基准通过跨八个领域的agent管道从真实冲突中构建场景,考察五个社会认知适应轴(战略立场、当事方构成、历史长度、情绪反应性及文化认同),并借助主题局部评估器,仅对推进特定主题的交互步骤进行评分。该评估器与人类专家的一致性达到0.82,较单步基线提升了一倍以上。在对八款前沿大语言模型进行基准测试后发现,即使在多样化且贴近现实的测试平台下,表现最强的调解员也仅能缩小约三分之一的无调解共识差距。其性能在社会认知各轴向上差异显著,这表明未来的进展关键在于对多样化条件的社会适应能力。
一句话总结
SoCRATES 提出了一项针对主动式 LLM 调解员的基准测试,该基准通过 Agent 管道构建跨越八个领域的场景,探查五个社会认知适应维度,并采用话题局部评估器仅对推进特定话题的对话回合进行评分。该基准与人类专家达成 0.82 的一致性,并揭示出即使八个前沿模型中最强的模型也仅能缩小未调解共识差距的三分之一,凸显了进步依赖于对多样化条件的社会适应。
核心贡献
- 本研究推出了 SoCRATES,这是一个统一的自动化评估框架,通过 Agent 管道在八个领域内构建真实的冲突场景,并探查五个社会认知适应维度。
- 该框架整合了话题局部评估器,通过限制评估范围至推进特定话题的对话回合,沿三个实时指标对调解轨迹进行评分,与人类专家达成 0.82 的一致性。
- 对八个前沿 LLM 调解员的全面基准测试表明,最强模型仅能缩小约三分之一的未调解共识差距,且其性能在社会认知条件变化时呈现显著差异。
引言
将大型语言模型部署为自动化调解员在扩展冲突解决规模方面具有重要潜力,但当前系统在动态的实际争端中仍难以弥合共识差距。以往的评估框架面临三大瓶颈:依赖有限的专家编写场景、混淆多个社会认知变量,以及对每个对话回合针对所有话题进行评分,这会引入无关话题的噪声并加剧评估误差。为弥补这些不足,研究团队推出了 SoCRATES,这是一个统一基准,可自动整理跨越八个领域的真实冲突场景,并探查调解员在五个独立社会认知维度上的表现。该框架还开发了一种话题局部评估器,仅对积极推进特定话题的对话回合进行评分,与人类专家达成高度一致。该框架揭示,即使是最领先的 LLM 调解员也仅能缩小约三分之一的未调解共识差距,表明未来的进步依赖于稳健的社会认知适应,而非单纯的语言流畅度。
数据集

-
数据集构成与来源
- 研究团队利用 Agent 深度研究管道,综合八个规范领域的网络证据,从现实争端中整理冲突场景。
- 这些领域涵盖交易、医疗、环境、企业对企业、公共政策、国际、法律及组织内部类别,均取材于哈佛教学材料。
- 所有场景均由 Agent 进行匿名化处理,以移除对特定个人、组织或地点的引用,确保模拟中不涉及真实人物。
-
各子集关键细节
- 整理过程共生成 40 个高难度冲突场景,保持每个领域五个场景作为通用条件基线。
- 每个场景的结构包含背景信息、包含角色与各话题立场的参与方集合、包含选项的话题集合,以及各参与方的偏好分配。
- 通过对每个场景的独立副本应用五个独立维度,将基础场景扩展为 15 种不同的社会认知条件。
- 上下文维度包括结合 Thomas-Kilmann 模式的战略姿态、增加第三方争端方的参与方构成,以及扩展至默认值五倍的历史长度。
- 人格维度在镇定与反应敏感端点之间调整情绪反应性,并基于美国、中国及韩国 Hofstede 文化档案分配文化身份。
- 文化条件生成三种文化内配对与三种跨文化配对,所有参与方均被提示使用英语交互,以将身份因素与语言因素隔离。
-
数据使用与处理
- 研究团队采用三步管道流程:Searcher agent 负责收集冲突案例,Scenario Writer agent 将其重构为结构化格式,Simulation agent 负责数据过滤。
- 过滤机制仅保留在未调解多轮对话中未能解决的场景,且需三次独立重演均以僵局告终方可纳入。
- 僵局被定义为共识失败、一方退出或达到 100 回合预算,被拒场景将反馈至 Searcher 以生成新种子。
- Searcher 使用 o4-mini-deep-research 进行种子收集,Writer 使用 GPT-5.4 进行重构,Simulator 使用 DeepSeek-V3.2 agent,这些 agent 维持固定的循环回合与私有内部思考。
-
元数据与验证细节
- 文化元数据通过向参与方档案附加总结 Hofstede 维度分数的确定性语句来构建,而情绪反应性则采用固定的参数化模板。
- 数据集支持话题局部评估,共识在片段级别进行标注,每个数据点捕捉一次来回交互以进行细粒度评分。
- 研究团队利用众包标注员与专家审核员验证人格保真度与共识一致性,确保角色一致性与谈判进度的准确追踪。
方法
SoCRATES 框架通过一个三阶段管道运行,旨在模拟和评估社会冲突中的调解过程。第一阶段为 Agent 场景整理,通过利用现实世界的公开争端构建多样化的冲突场景集。该流程始于一个 search agent,负责从公开来源识别相关冲突案例,生成封装各争端时间线、利益相关者、核心问题与机构张力的种子报告。随后,这些种子由 scenario writer agent 处理,将其重新格式化为结构化的谈判模拟格式。此重构过程确保所有现实标识符均被虚构名称替换,同时保留冲突的核心动态,包括话题数量、离散选项及各方立场的差异。生成的场景表示为元组 s=(B,P,T,W),其中 B 表示背景信息,P 为争端参与方集合,T 为冲突话题,W 为各参与方的偏好权重。
第二阶段为社会认知探查,沿五个独立维度(人格、背景、上下文、情绪调节与战略适应)扩展初始场景,以生成丰富的条件集。每个维度扰动场景的特定组件:参与方档案、背景或参与方集合。此扩展使每个场景产生 15 种条件,通用条件作为基线。这些扰动旨在测试不同社会认知因素如何影响冲突动态。在每个场景中,参与方被建模为大型语言模型(LLM)agent,每个 agent 均配备私有档案,包含目标、后备立场、各话题初始立场、人格及话题权重向量。调解员同样为 LLM agent,仅观察共享输入(背景、话题与对话),并必须推断参与方的隐藏状态以进行有效干预。
最终阶段为话题局部评估,使用三项指标评估调解员表现:共识增益、干预及时性与干预有效性。评估框架将调解轨迹与匹配的未调解运行进行对比,追踪每个回合 t 的累积共识状态 S≤t。共识增益通过量化最终状态下已缩小的未调解共识差距比例,来衡量调解员的整体贡献。干预及时性奖励快速响应,测量共识下降与调解员干预之间的延迟,时间窗口为 10 个回合。干预有效性评估每次干预产生的共识提升,并进行归一化处理以消除天花板效应。评估采用话题局部评分方法,仅在积极讨论特定话题的回合内确定该话题的共识分数,从而降低无关内容的噪声并提高准确性。
整个流程通过一系列基于 LLM 的 agent 实现,每个 agent 具有特定角色与提示词。场景编写器使用结构化提示词以确保模拟符合所需格式。偏好加权 agent 为各方生成总和为 100 的正整数权重,确保清晰的优先级排序。参与方 agent 在 0.6 的温度下运行,同时生成私有内部思考与公开发言,前者计入私有历史,后者构成对话。调解员 agent 同样在 0.6 的温度下运行,首先根据预设条件决定是否干预,若决定干预,则生成战略性发言以引导各方达成共识。此模块化设计使得在多样化社会认知条件下系统探索调解策略成为可能。
实验
本研究利用 SoCRATES 基准测试,在多样化的冲突领域与社会认知条件下评估了八个 LLM 调解员,该基准依赖受控的人格模拟器与话题局部评估框架。初步验证确认,模拟争端方可靠地遵循规定的行为变化,且自动评分系统与人类专家判断高度一致。定性分析表明,社会冲突解决对当前模型而言仍极具挑战,其性能由上下文适应能力驱动,而非模型规模或干预频率。最终,有效的调解需要动态调整干预的时机与内容,以匹配不断演变的战略、情绪与文化需求,因为僵化或过于积极的调解策略始终无法推动共识形成。
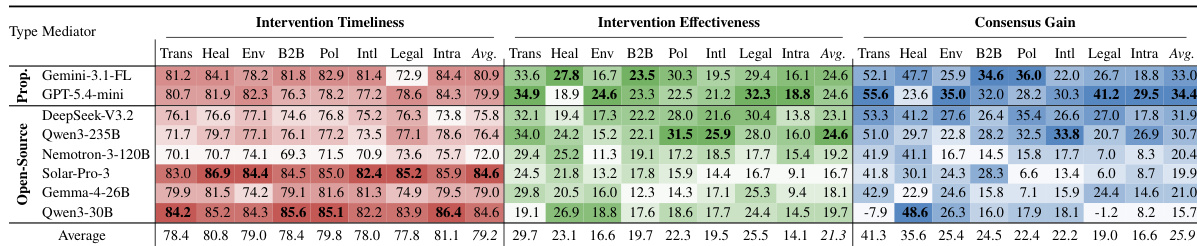
研究团队在多个冲突领域与社会认知维度上评估 LLM 调解员,通过共识增益、干预及时性与有效性衡量其表现。结果表明,调解员表现因领域与条件不同而存在显著差异,优秀调解员会调整干预时机以匹配冲突不断演变的社会认知需求。性能与模型规模或专有状态并非始终相关,过于频繁干预却缺乏实质影响的调解员虽具备高及时性,但共识增益较低。调解员在不同冲突领域的表现差异广泛,共识增益因冲突类型不同而呈现显著区别。干预有效性取决于时机适应能力;优秀调解员会根据冲突的社会认知需求在恰当时刻达到表现峰值。过早或过频干预的调解员虽及时性高,却无法改善共识,表明频率并不等同于有效性。

研究团队使用衡量干预及时性、干预有效性与共识增益的基准测试评估 LLM 调解员的表现。结果显示,该基准能够捕捉调解员行为中的有意义差异,优秀调解员会将其干预时机适应于冲突的社会认知需求。评估表明,有效调解需要兼顾及时性与实质性干预,因为早期且频繁的干预并不能保证结果改善。干预及时性与有效性呈现不同趋势,优秀调解员会根据冲突的社会认知需求调整时机。共识增益在不同冲突领域差异显著,表明调解员的表现因上下文而异。干预有效性与共识增益的相关性强于与干预频率的相关性,说明干预质量比数量更重要。
研究团队使用衡量干预及时性、有效性与共识增益的基准测试,在多个冲突领域与社会认知维度上评估 LLM 调解员。结果表明,调解员表现因领域与条件不同而存在显著差异,没有任何单一模型在所有指标上均表现出色,且有效调解需要针对具体冲突上下文调整时机与内容。调解员在不同冲突领域的表现差异广泛,共识增益在不同领域间存在显著区别,且无模型能在所有设置下实现高解决率。干预及时性与有效性并不相关;部分模型干预频繁却未能改善结果,表明仅靠时机不足以实现成功调解。调解员在社会认知维度上展现出不同的适应曲线,其性能会因战略、情绪或文化因素的不同而以不同方式下降。
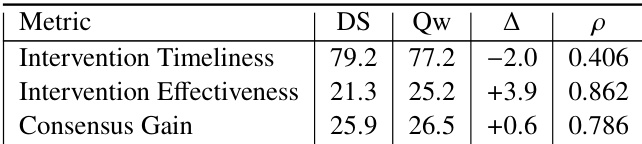
研究团队通过测量不同模拟器在变化强度尺度上维持预期情绪反应性水平的能力,评估 SoCRATES 中人格模拟的保真度。结果显示,DeepSeek-V3.2 与人类判断达到最高一致性,表明其将浮点值人格参数转化为行为结果最为可靠。DeepSeek-V3.2 在测试的模拟器中展现出最高的模拟保真度。评估揭示了不同模拟器在保留预期人格强度水平方面的清晰层级。人类标注员的一致性支持了观察到的模拟保真度差异的可靠性。

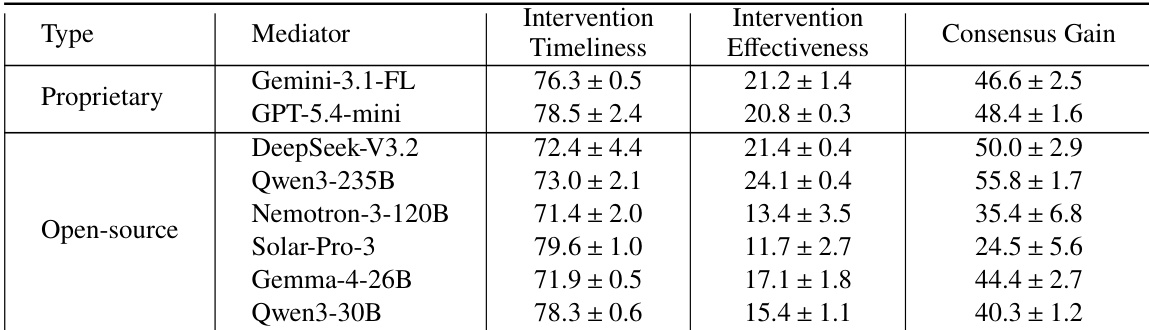
研究团队通过三项指标评估八个 LLM 调解员:干预及时性、干预有效性与共识增益。结果显示,专有模型实现的共识增益高于开源模型,表现最佳的开源模型仍落后于顶尖的专有调解员。干预及时性与共识增益并不相关,因为部分模型干预频繁但有效性较低。模型间的性能差距在不同冲突领域与社会认知条件下保持一致,表明有效调解依赖于适应能力而非统一的功能规格。专有模型的共识增益高于开源模型,顶尖专有调解员的表现优于最佳开源模型。干预及时性无法预测共识增益,因为更早或更频繁干预的模型未必取得更好结果。调解员在冲突领域与社会认知维度上的表现差异显著,凸显了采用适应性策略而非统一调解方法的必要性。
实验在多样化的冲突领域与社会认知条件下评估 LLM 调解员,并独立评估不同情绪强度尺度下的人格模拟保真度。结果表明,成功的调解依赖于上下文感知适应能力,而非频繁或早期的干预,性能因冲突类型不同而存在显著差异,且专有模型通常比开源替代方案实现更高的共识。此外,模拟保真度评估验证了行为转化能力中存在清晰的层级,表明根据人类判断,DeepSeek-V3.2 最能可靠地保留预期人格参数。