Command Palette
Search for a command to run...
ArcANE:角色扮演语言 Agent 是否在正确的时间保持角色?
ArcANE:角色扮演语言 Agent 是否在正确的时间保持角色?
Woojung Song Nalim Kim Sangjun Song Chaewon Heo Jongwon Lim Yohan Jo
摘要
角色扮演语言 agents (RPLAs) 应当扮演那些随着故事推进其价值观与行为不断演变的角色,而非维持固定的人设。现有的基准测试仅评估特定章节的事实性记忆能力,而非考察回答是否与角色的心理轨迹相一致,尤其是在源文本未曾涉及的场景中。我们提出了 ArcANE(Arc-Aware Narrative Evaluation),这是一个自动构建的基准测试,涵盖 17 部小说及 80 位主要角色。Character Arc 沿心理轴将叙事划分为若干阶段,每个探测用例在不同阶段提出相同的场景,涵盖源文本内部的情境以及文本外部的情境。在六个模型与六种上下文模式下,以 Character Arc 为条件在所有模型上均优于其他所有上下文策略,且该优势在源文本之外的场景中最为显著,因为检索机制在这些场景中无法找到相关信息。我们进一步使用相同数据对开放权重模型进行微调,获得 ArcANE-8B/32B,该模型在源文本之外的场景中进一步扩大了 Character Arc 的优势。
一句话总结
ARcANE 是一个自动构建的基准测试,涵盖 17 部小说和 80 位主要角色。该基准通过将叙事划分为心理角色弧(Character Arcs)来评估角色扮演语言 Agent 的表现,旨在测试角色在不同故事阶段的对齐情况。实验结果表明,基于角色弧的条件控制(arc-conditioning)优于所有其他上下文策略,尤其在文本外场景中表现突出,而经过微调的 ARcANE-8B 和 ARcANE-32B 模型进一步放大了这一优势。
核心贡献
- 本研究推出 ARcANE,这是一个自动构建的基准测试,涵盖 17 部小说和 80 位主要角色,用于评估语言 Agent 是否与角色不断演变的心理轨迹保持一致,而非仅仅依赖静态的事实记忆。
- 该研究开发了一套 Character Arc 框架,将叙事划分为心理阶段,并在这些阶段中使用相同的场景对 Agent 进行探测,以捕捉文本内及文本外的行为变化。
- 在六种模型和六种上下文模式下的评估表明,基于角色弧的条件控制始终优于其他替代策略,而微调后的 ARcANE-8B 和 ARcANE-32B 模型在叙事外场景中进一步放大了这一优势。
引言
角色扮演语言 Agent 为交互式叙事、游戏和陪伴型 AI 提供动力,用户期望获得能够真实反映角色随时间演变的沉浸式体验。然而,先前的评估框架将人格设定视为静态目标,主要在固定时刻测量事实记忆或表层风格一致性。这种方法无法捕捉随着叙事事件累积,角色的核心价值观和行为模式如何发生变化。为了解决这一局限性,作者引入了 ARCANE 基准测试,通过将角色发展映射到结构化的心理轨迹上,来评估时间维度上的行为保真度。通过在特定阶段的探测任务(包括源材料中从未出现过的场景)上测试 Agent,研究证明将模型建立在叙事弧的基础上,能显著提升其描绘角色演变状态的忠实度。
数据集
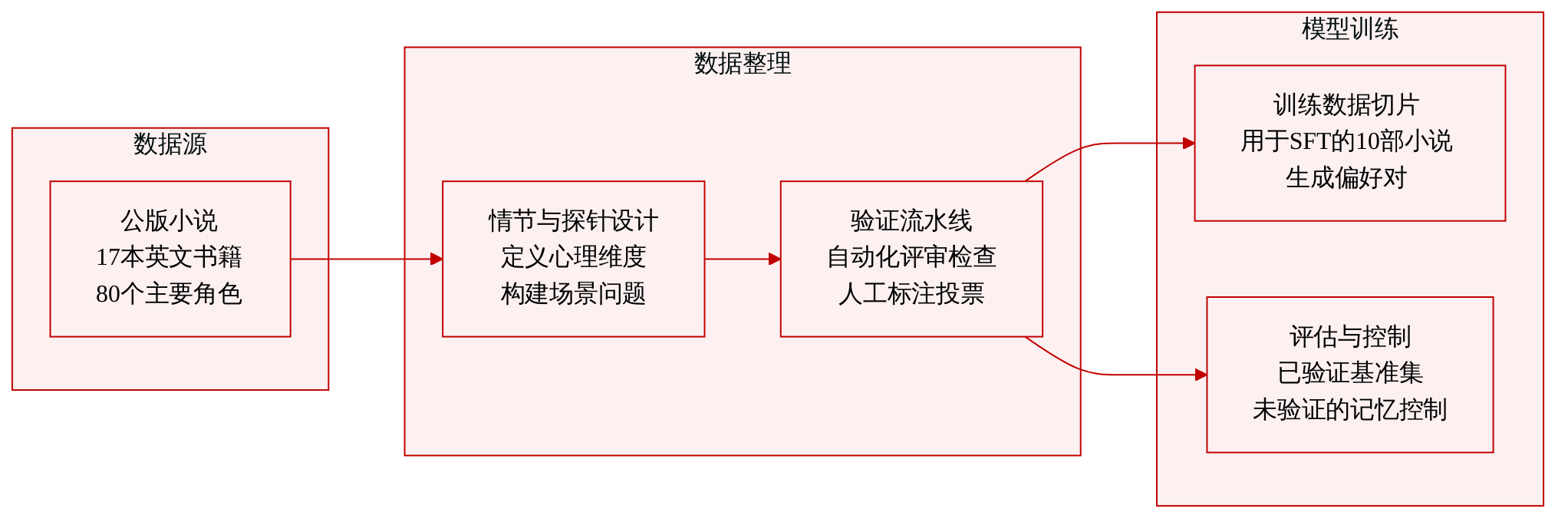
数据集构成与来源
- 作者从美国公有领域的 17 部英文小说中汇编了 ARCANE,主要来源为 Project Gutenberg。该语料库涵盖 544 条心理发展维度轴上的 80 位主要角色,并包含 4,601 个结构化探测任务。
- 所有数据均序列化为 JSON 记录,用于追踪角色弧和探测响应,元数据则记录文学验证结果、标注者投票及质量控制日志。
各子集关键细节
- 训练切片: 包含 10 部小说和 2,545 个探测任务。该子集作为监督微调和偏好优化数据生成的基础。
- 验证评估切片: 包含 5 部小说和 1,754 个探测任务。作者采用严格的过滤流程,每条维度轴必须通过自动化评论家集成模型,并获得至少两名人类标注者的多数票(三分之二)方可纳入。
- 未验证低热度切片: 包含 2 部小说和 302 个探测任务,均选自 Project Gutenberg 热度指标底层的作品。该切片不参与人工审核,用作记忆控制基准。
数据使用与处理
- 训练切片生成 45,690 行监督微调数据。作者通过从 gpt-5.4-mini 和 claude-sonnet-4-6 各采样三个完成结果(温度设为 0.9,限制 800 token),并合并输出以降低单一模型偏差。
- 针对偏好优化,作者构建了涵盖 12 部小说和 2,838 个探测任务的 14,671 对直接偏好数据。每对数据将锚定阶段的响应作为选择输出,相邻阶段的响应作为拒绝输出,从而将角色发展变化隔离为唯一变量。
- 在评估阶段,作者测试了多种上下文模式,包括基础身份提示、五章摘要、使用 Top-6 文本块检索增强生成(RAG),以及自定义弧模式(输入截断至查询章节的精选角色轨迹)。
元数据构建与处理细节
- 角色弧的构建通过定义具有对立两极、方向标签和人生阶段分类的心理维度来实现。探测任务基于与源文本的距离划分为三个难度层级:场景内(原文摘录)、世界内(符合设定的虚构内容)和世界外(时代置换场景)。
- 多阶段验证流程执行严格的质量标准。作者运行 Q-Voice 检查以验证角色一致性和知识截断合规性,使用 Q-PhaseFit 通过盲测 LLM 评估验证阶段对齐情况,并执行 Q-Anchor/World 检查以确认世界观规则。未通过检查的探测任务将自动重新生成,而响应难以区分的相邻阶段对将被标记以供分析。
- 每条探测记录均包含一个作为知识截断点的锚定查询章节,确保模型无法引用后续情节发展。所有验证器判决、重试次数及标注者有效性分数均直接嵌入数据集架构中。
方法
ArcANE 框架围绕一个三阶段流水线构建,用于构建和评估角色弧。角色弧被定义为角色不断演变的心理与关系状态的阶段化轨迹。整体流程始于角色弧构建,接着进行探测任务生成,最后完成验证与过滤。该框架利用两条独立的数据流——事件流与状态流——来生成候选维度轴,随后通过 LLM 评论家与人类标注者的结合进行协调与验证。
第一阶段为候选生成,通过两条并行的章节级数据流处理小说。事件流提取具有心理冲击力的事件,如情绪、信念或关系动态的变化;状态流则输出角色的横截面心理画像,捕捉情绪状态、信念、欲望、意图和自我意识。每条数据流独立生成两类候选维度轴:个人内部维度轴追踪信念、动机和应对机制的内部变化,关系维度轴追踪二元关系,包括信任、尊重、亲密和敌对。这种双流设计确保了事件遗漏和状态误读的错误可被分离,从而提供内部可靠性检验。生成的候选维度轴基于成熟的文学与心理学研究,遵循《Values in the Wild》中的概念 grounding 标准。
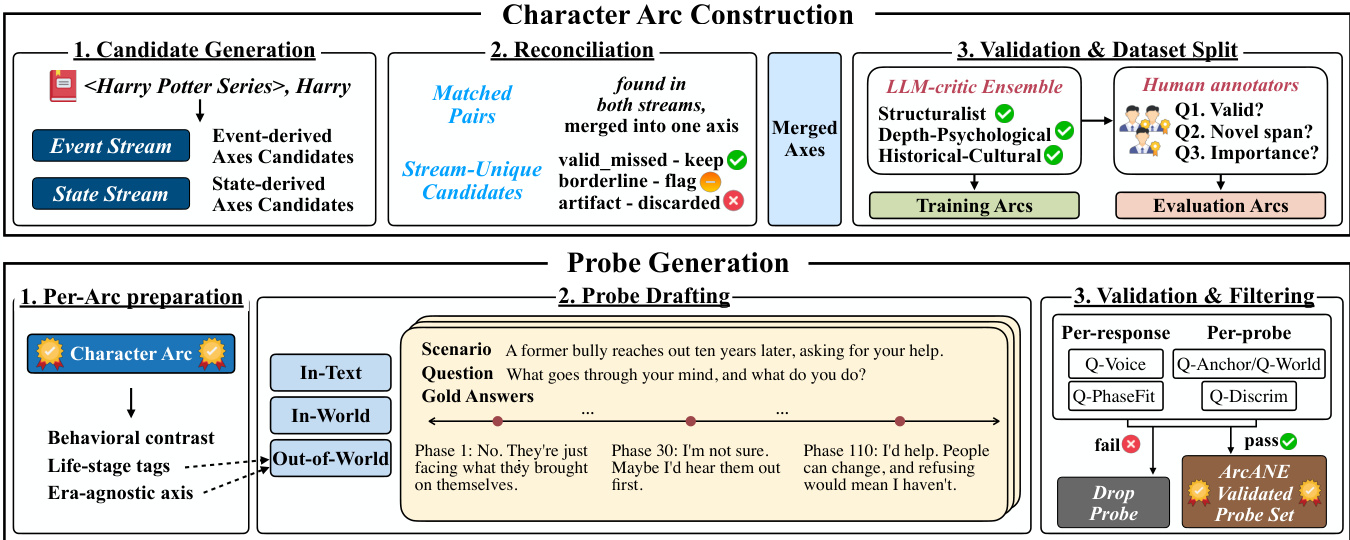
第二阶段为协调合并,涉及一个分析型 LLM,用于比较两条数据流的候选维度轴。匹配对——即两条数据流共同提出的维度轴——被合并为单一维度轴,并附带方向标签以指示各阶段更接近的极点。未匹配的候选项根据其合理性和证据被分类为有效遗漏(保留)、边缘(标记)或伪影(丢弃)。此步骤确保只有稳健且经过交叉验证的维度轴才能进入最终数据集。

第三阶段为验证与数据集划分,旨在确保外部有效性。合并后的维度轴将经过一个由三种视角组成的 LLM 评论家集成模型:结构主义/叙事学家、深度心理学和历史/文化视角。每位评论家均依据其学术框架对维度轴进行评估并提供引用。对于训练小说,仅当至少两名评论家判定其具有字面依据时才会保留。对于评估小说,评论家评分仅作为参考,人类标注者将独立重新评估每条维度轴的有效性、小说覆盖范围及重要性,有效性判定遵循三分之二多数规则。

完成弧构建后,流水线进入探测任务生成阶段,旨在创建行为探测任务以评估模型区分不同叙事阶段中角色行为细微变化的能力。该过程始于单弧准备,利用角色弧生成时代无关的维度轴和人生阶段标签。随后起草三种类型的探测任务:文本内、世界内和世界外,每种类型均有特定的约束条件和风格指南。草稿阶段将生成场景、问题及一组阶段响应,每个响应代表角色在其弧线上特定节点的行为表现。

最终阶段为验证与过滤,确保探测任务忠于源文本并具备适当区分度。逐响应验证使用 Q-PhaseFit 模型判定该响应最具有诊断意义的阶段,并与目标阶段进行比较。若响应偏离阶段,则重新生成。逐探测任务验证检查世界观一致性,并排除经典场景的机械复现。轨迹评分标准评估角色在不同阶段变化的对齐度、方向和形态,相邻阶段对基于决策变量进行区分。这一全面的验证流程确保生成的探测任务集准确反映角色弧,并可用于评估模型性能。
实验
该评估使用基于小说的角色弧基准测试,在多种上下文策略下对六种语言模型进行评估,验证结构化的叙事引导是否能提升 Agent 追踪心理演变的能力。结果一致表明,基于明确角色轨迹的条件控制优于其他上下文方法,尤其在传统检索失效的文本外场景中表现更佳。定性分析指出,这一优势反映了对角色发展的真实方向性追踪,而非孤立的场景匹配。微调实验进一步证明,偏好优化成功赋予了模型与叙事进展相一致的动态语气变化。消融研究证实,这些改进源于结构化的弧内容,而非预训练记忆或结构性伪影。
{"summary": "作者在多种上下文策略下评估了多款语言模型,重点关注其维持角色在叙事弧中一致性的能力。结果表明,基于角色弧的条件控制在所有模型上始终优于其他上下文方法,尤其在超出源文本的场景中表现突出。性能差距在轨迹级指标上最为显著,表明弧策略能更好地捕捉角色不断演变的心理轨迹。", "highlights": ["弧控制在所有模型上始终优于其他上下文策略,尤其在源文本外的场景中表现突出。", "弧与其他方法的性能差距在轨迹级指标上最大,凸显了对角色演变的更好捕捉。", "弧控制的优势在基于相同数据微调的模型上最为明显,表明其与角色弧的对齐度更高。"]}
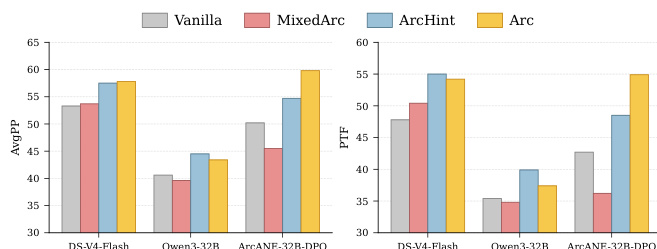
{"summary": "作者在多种上下文策略下评估了多款模型,重点关注角色弧 grounding 对角色扮演性能的影响。结果表明,基于弧的上下文始终优于其他策略,在源文本外的场景中增益最大。该优势在轨迹级指标上尤为明显,表明与角色不断演变的心理状态对齐度更高。", "highlights": ["基于弧的上下文在所有模型上始终优于其他策略,在源文本外的场景中增益最大。", "随着场景从场景内转向世界外,基于弧与非弧方法的性能差距逐渐扩大。", "与逐阶段指标相比,轨迹级指标显示基于弧的上下文具有更强优势,表明能更好地追踪角色随时间的发展。"]}
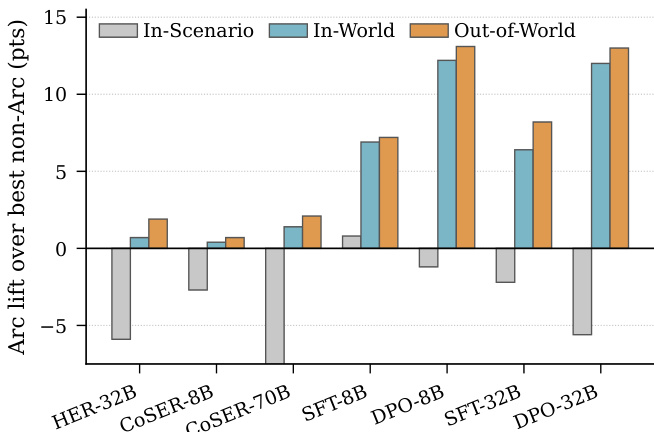
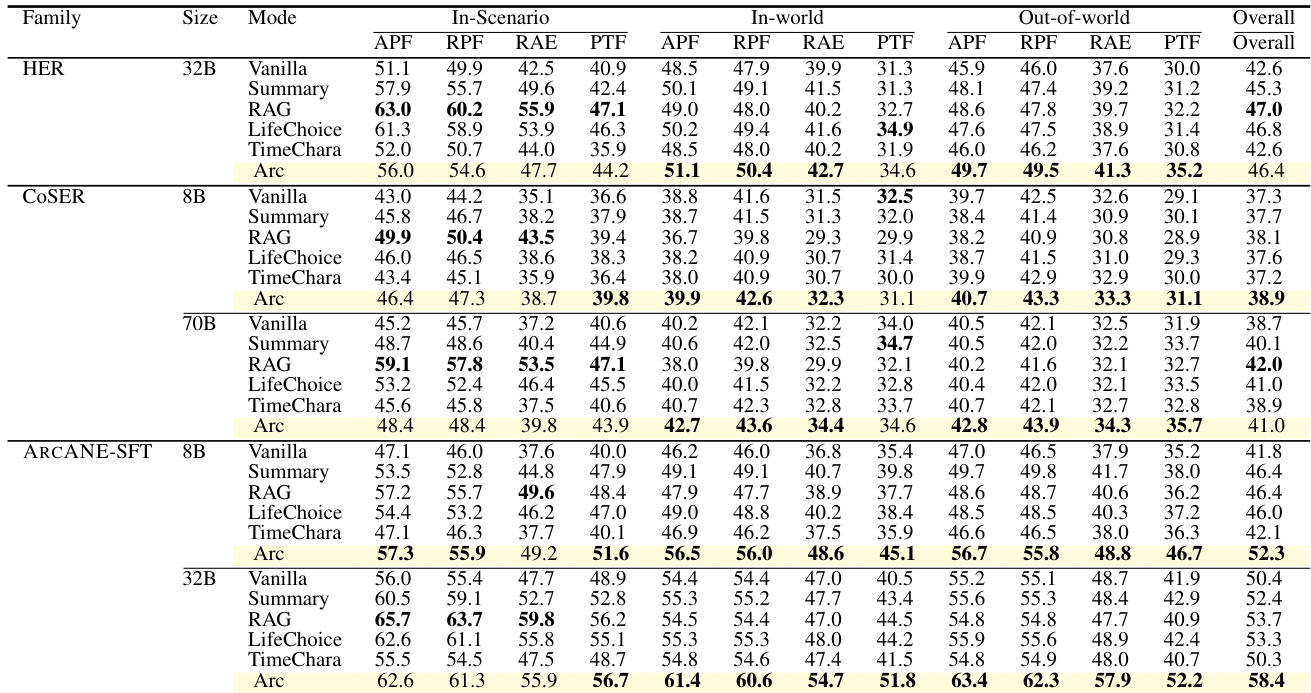
作者在评估叙事响应中角色弧一致性的基准测试上,对比了多种上下文策略下的多款模型。结果表明,基于角色弧的条件控制在所有模型上均带来更优性能,尤其在超出源文本的场景以及捕捉随时间推移的叙事连贯性的轨迹级指标上表现突出。基于角色弧的条件控制在所有模型和指标上均稳定优于其他上下文策略。基于弧与非弧方法的性能差距在源文本外场景中最大,因为基于检索的方法在此类场景中缺乏相关信息。基于弧的方法在轨迹级指标上获得最高分,表明其能更好地与角色随时间推移的心理进展保持对齐。
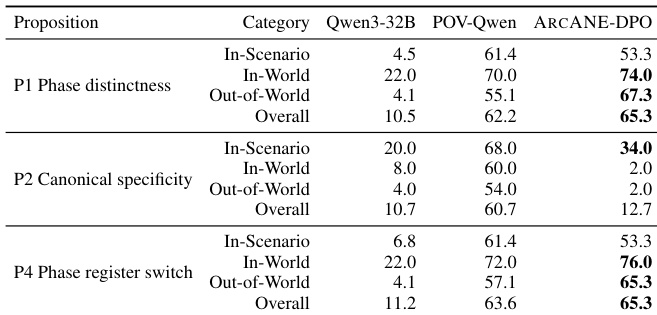
作者在评估叙事角色扮演中角色弧忠实度的基准测试上,对比了不同上下文策略下的多款语言模型。结果表明,基于角色弧的条件控制在所有模型上均稳定优于其他策略,在源文本外场景和轨迹级连贯性指标上增益最大。该优势在较大参数规模的模型上以及使用基准数据微调时尤为显著。基于角色弧的条件控制在所有模型上实现了最高的整体性能,超越了其他上下文策略。弧与非弧方法的性能差距在世界外场景和轨迹级指标上最大。在基准数据上微调的模型展现出更大的弧优势,尤其在世界外场景和轨迹评估中表现明显。
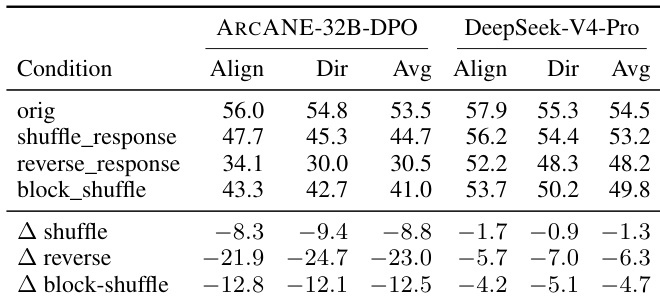
作者使用表格评估了不同响应顺序扰动对 ARcANE-32B-DPO 和 DeepSeek-V4-Pro 两款模型轨迹保真度指标的影响,表格报告了对齐度、方向和平均指标的得分。结果表明,打乱和反转响应序列会显著降低两款模型的轨迹保真度得分,其中 ARcANE-32B-DPO 的下降幅度大于 DeepSeek-V4-Pro,表明前者对阶段顺序更敏感,因而更能有效追踪叙事轨迹。块状打乱扰动同样导致得分大幅下降,说明轨迹指标不仅捕捉逐阶段内容,还受到响应序列的影响。打乱和反转响应序列会导致轨迹保真度得分显著下降,尤其对 ARcANE-32B-DPO 影响明显。ARcANE-32B-DPO 对响应顺序扰动的敏感性高于 DeepSeek-V4-Pro。块状打乱扰动同样引发大幅得分下降,表明轨迹指标捕捉了超越逐阶段内容的序列级结构。
实验在多种上下文策略下评估了多款语言模型,以检验其在叙事角色扮演中维持角色一致性与心理演变的能力。与替代方法相比,基于角色弧的条件控制始终产生更优性能,尤其在源文本外场景以及追踪随时间推移的叙事发展的轨迹级指标上表现突出。此外,敏感性分析表明,破坏响应序列会显著降低轨迹保真度,证明这些指标能有效捕捉序列级叙事结构而非孤立内容。综合来看,研究结果证实,基于弧的条件控制增强了长篇角色连贯性,而轨迹指标可可靠地衡量模型与不断演变的叙事动态的对齐程度。