Command Palette
Search for a command to run...
TransitLM:面向无地图 transit 路线生成的超大规模数据集与基准
TransitLM:面向无地图 transit 路线生成的超大规模数据集与基准
Hanyu Guo Jiedong Yang Chao Chen Longfei Xu Kaikui Liu Xiangxiang Chu
摘要
公共交通路线规划传统上依赖于结构化的地图基础设施和复杂的路线引擎,且目前尚无数据集支持训练模型以摆脱这种依赖。我们提出了TransitLM,这是一个包含来自四个中国城市的超过1300万条公共交通路线规划记录的大规模数据集,涵盖120,845个站点和13,666条线路。该数据集作为持续预训练语料库发布,并为三项具有互补评估指标的评估任务提供基准数据。实验表明,在TransitLM上训练的LLM能够以高准确率生成结构有效的路线,并隐式地将任意GPS坐标映射到相应的站点,而无需任何显式的地图匹配。这些结果表明,公共交通路线规划可以完全从数据中学习,从而实现端到端的、无需地图的路线生成,直接基于起讫点信息生成路线。数据集和基准数据可在 https://huggingface.co/datasets/GD-ML/TransitLM 获取,评估代码位于 https://github.com/HotTricker/TransitLM。
一句话总结
作者提出了 TransitLM,这是一个包含来自中国四个城市超过 1300 万条公共交通路线规划记录的大规模数据集与基准测试。该数据集通过训练语言模型将任意 GPS 坐标隐式映射到站点,无需显式的地图基础设施即可实现端到端的无地图路线生成,并为三项互补的公共交通路线规划评估任务提供了基准测试。
核心贡献
- 提出 TransitLM,这是一个包含来自中国四个城市超过 1300 万条公共交通路线规划记录、120,845 个站点和 13,666 条线路的大规模预训练语料库与基准数据集。该资源使模型能够完全从数据中学习公共交通导航,无需依赖显式的地图基础设施或路由引擎。
- 建立三项标准化的评估任务,分别用于最优路线生成、偏好感知规划和多路线生成。每项任务均采用涵盖连通性、可达性可行性、路线重叠度及数值字段准确率的互补指标。
- 证明基于该数据集训练的语言模型能够将任意 GPS 坐标隐式映射至交通站点,并直接从起终点查询生成结构有效的路线。该模型在所有规划目标上实现泛化且未出现负迁移,证实了端到端无地图路线生成的可行性。
引言
公共交通路线规划对城市出行至关重要,但传统系统严重依赖结构化的地图基础设施与复杂的路由引擎。尽管通用大语言模型在推理方面表现优异,但由于常出现幻觉站点、路线不连贯以及缺乏结构映射,它们在交通规划任务中始终面临挑战。这一局限源于训练数据的碎片化:现有的轨迹数据集忽略了站点结构,而静态网络数据集则忽视了用户行为,导致缺乏用于学习端到端路由的综合资源。为弥补这一空白,作者提出了 TransitLM,这是一个包含中国四个主要城市超过 1300 万条路线规划记录的大规模数据集。研究团队同步发布了持续预训练语料库以及针对最优路由、偏好感知规划和多路线生成的标准化基准测试。通过在数据上训练大语言模型,研究证明了模型能够生成结构有效且无需地图的公共交通路线,从原始 GPS 坐标中隐式学习空间关系,并在不依赖外部地理数据库的情况下泛化至多种规划目标。
数据集
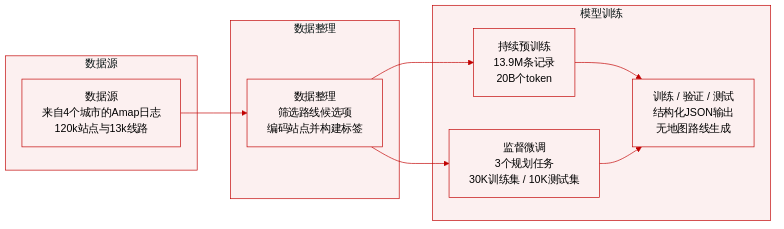
数据集构成与来源
- 作者提出了 TransitLM,这是一个源自中国主要导航平台高德地图的公共交通路线规划日志的大规模数据集。
- 数据涵盖北京、上海、深圳和成都四个城市,包含 120,845 个站点及 13,666 条公交与地铁线路。
- 数据集已完全去标识化,采样自单一日历日,并剔除了时间戳与用户标识符,以确保隐私安全并防止出行模式被重新识别。
各子集关键细节
- 持续预训练(CPT)语料库: 该子集包含 1390 万条记录,其中包括 12,945,264 条路线规划会话、880,854 条站点描述及 147,918 条线路描述。
- 路线规划会话记录起终点 GPS 坐标、兴趣点(POI)名称、分段行程指标、路线类型标注及用户选择标签。
- 模态分布均衡,其中纯公交路线占 33.0%,纯地铁路线占 19.0%,公交地铁组合路线占 16.8%,包含出租车或骑行接驳的混合路线占 30.5%。
- 平均序列长度为 2,377 个中文字符,语料库总计超过 200 亿个 token。
- 基准测试监督微调(SFT)数据: 作者针对三项评估任务构建了专用数据:最优路线生成、偏好感知规划与多路线生成。
- 每项任务均提供 30,000 条训练样本与 10,000 条测试样本,格式为标准化的提示词-标签对。
- 标签为结构化的 JSON 对象,编码了线路序列、站点序列、总距离、时间、票价及首末接驳换乘详情。
使用与处理流程
- 候选过滤: 作者对路线规划会话应用多样性过滤,将原本平均 6.32 个选项缩减至每会话最多保留 5 条候选路线。
- 偏好学习: 在构建 CPT 语料库时,用户实际选择的路线被置于候选列表首位,使模型能够通过下一个 token 预测隐式学习用户偏好。
- 站点编码: 站点采用唯一数字 ID 而非自然语言名称表示,这需要扩展语言模型的词表。
- SFT 构建: 在微调阶段,作者根据任务定义的标准从候选集中筛选特定路线,以构建结构化的真实标签。
- 元数据: 数据集包含线路与站点的静态描述,附带停靠序列、运营时间及连通性等属性,使模型能够内化网络拓扑结构。
方法
作者采用基于大语言模型(LLM)的框架进行公共交通路线规划,旨在克服传统方法与通用大语言模型的局限性。整体架构称为 TransitLM,围绕结合持续预训练(CPT)与监督微调(SFT)的两阶段训练流水线构建,使模型能够生成准确、多样化且符合偏好的交通路线。该框架为端到端且无需地图支持,在推理阶段无需显式检索地图数据或查询站点。
系统以包含起终点及可选偏好的用户查询作为输入起点。输入数据通过基于自定义数据集 TransitData 训练的模型进行处理,该数据集包含来自中国四个主要城市的 1300 万条真实用户会话记录,涵盖详细的起终点(OD)轨迹与用户交互信息。该数据用于训练模型执行三项核心任务:最优路线生成、偏好感知规划与多路线生成。每项任务均遵循相同的结构化输入输出模式,确保一致性。模型输出为包含线路序列、站点 ID、换乘标记、距离、时间、票价及首末接驳详情的结构化 JSON 格式的公共交通路线。
参见框架示意图 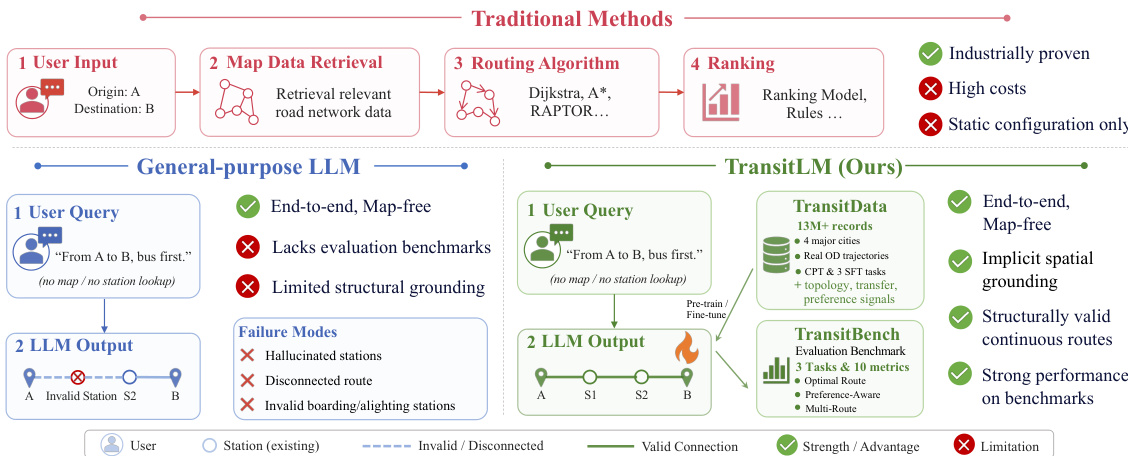 。该图展示了传统方法与本文提出的 TransitLM 方法的对比。传统系统依赖包含地图数据检索、Dijkstra 或 RAPTOR 等路由算法以及排序模型的多步骤流水线,虽经工业界验证,但存在成本高与配置静态的缺陷。相比之下,TransitLM 作为单一端到端模型直接处理用户查询,生成有效路线而无需中间地图查询或外部算法。该设计实现了隐式空间映射,并支持结构有效的连续路线,有效解决了通用大语言模型中幻觉站点或路线不连贯等关键局限。
。该图展示了传统方法与本文提出的 TransitLM 方法的对比。传统系统依赖包含地图数据检索、Dijkstra 或 RAPTOR 等路由算法以及排序模型的多步骤流水线,虽经工业界验证,但存在成本高与配置静态的缺陷。相比之下,TransitLM 作为单一端到端模型直接处理用户查询,生成有效路线而无需中间地图查询或外部算法。该设计实现了隐式空间映射,并支持结构有效的连续路线,有效解决了通用大语言模型中幻觉站点或路线不连贯等关键局限。
模型架构基于 Qwen3-Base 变体(0.6B、1.7B 与 4B)构建,词表已扩展以包含全部 120,845 个站点 ID 作为专用 token。该扩展确保站点以单一 token 形式表示,防止模型通过字符级组合生成不存在的站点,并使其能够学习直接的站点级关系。两阶段训练流程始于持续预训练(CPT),序列被打包至固定长度,并采用余弦学习率调度进行优化。该阶段之后为监督微调(SFT),模型在每个任务专用数据集上微调一个 epoch,数据集取自不同时间段以防止数据泄露。此外,还训练了一个联合变体 Qwen3-4B-Joint,使用三项任务的合并 SFT 数据进行训练,以评估交通知识是否能在不同规划目标间迁移,从而实现统一部署。
如下图所示: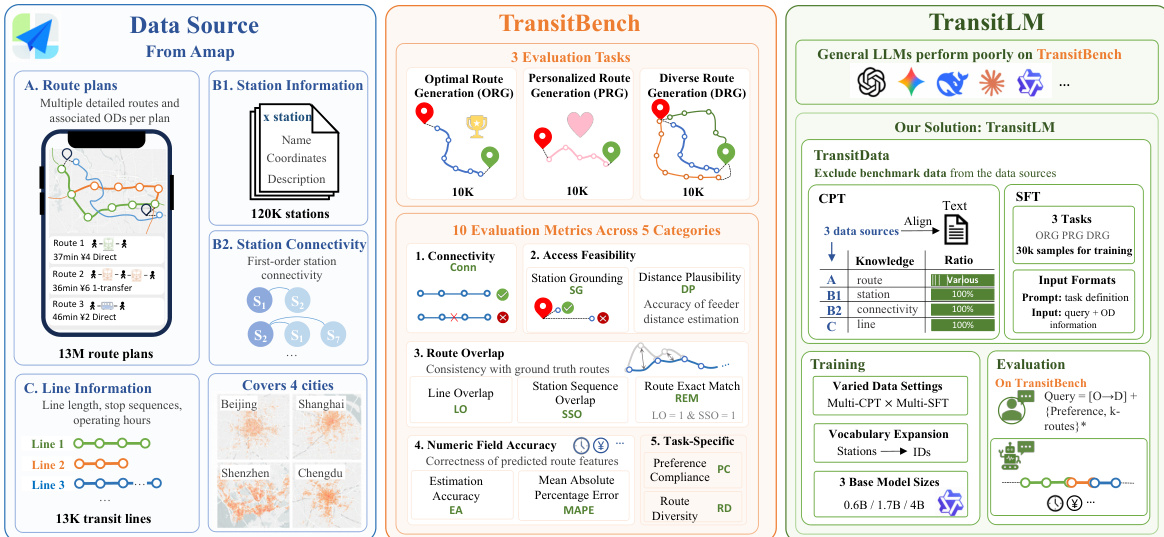 。该图详细说明了数据来源、评估任务与训练流水线。数据源自高德地图,包含中国四个城市的 1300 万条路线规划、12 万个站点及 1.3 万条交通线路。评估任务围绕五大类共 10 项指标构建:连通性、可达性可行性、路线重叠度、数值字段准确率,以及偏好符合度与路线多样性等任务特定指标。训练过程包含对文本与结构化数据的 CPT,随后针对三项独立任务进行 SFT。模型在 TransitBench 基准测试上进行评估,该基准包含 3 万训练样本与 10 项指标,确保模型在各类规划目标上均表现优异。
。该图详细说明了数据来源、评估任务与训练流水线。数据源自高德地图,包含中国四个城市的 1300 万条路线规划、12 万个站点及 1.3 万条交通线路。评估任务围绕五大类共 10 项指标构建:连通性、可达性可行性、路线重叠度、数值字段准确率,以及偏好符合度与路线多样性等任务特定指标。训练过程包含对文本与结构化数据的 CPT,随后针对三项独立任务进行 SFT。模型在 TransitBench 基准测试上进行评估,该基准包含 3 万训练样本与 10 项指标,确保模型在各类规划目标上均表现优异。
实验
评估涵盖最优规划、偏好感知路由与多路线任务中的公共交通路线生成,采用结构连通性、可达性可行性、路线重叠度与数值准确率等指标,将领域专用模型与通用大语言模型及工具增强基线进行基准对比。实验结果表明,通用模型从根本上缺乏交通拓扑知识并高度依赖文本提示,而领域专用模型仅通过交通数据的持续预训练即可实现稳健的空间映射与高路线保真度。消融实验进一步证实,这种空间理解能力独立于输入模态,随数据量增加有效扩展,并在多规划目标间无缝泛化且无负迁移,最终验证了端到端无地图路由可在不牺牲结构完整性的前提下达到与外部 API 相当的性能。
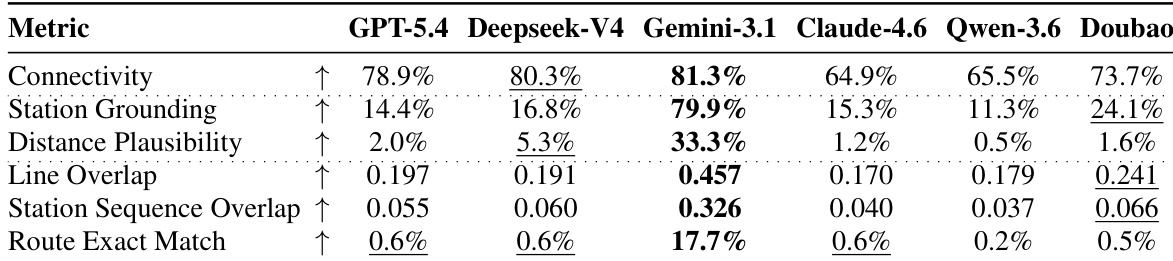
作者针对最优路线生成任务对比了多款通用大语言模型,从连通性、可达性可行性、路线重叠度与数值准确率等多个维度评估其表现。结果显示,这些模型在结构有效性与路线正确性方面面临困难,表现最佳的模型仅在连通性与路线精确匹配等关键指标上达到中等水平。通用大语言模型表现出较低的连通性与路线精确匹配率,表明其生成结构有效交通路线的能力有限。在参评模型中,Gemini-3.1 在连通性与站点映射方面表现最佳,但仍显著落后于领域专用模型。所有通用模型在路线精确匹配与线路重叠度上表现均较差,凸显了其对交通网络知识的缺乏。
作者评估了不同模型配置在交通路线生成任务上的表现,对比标准文本输入与仅 GPS 输入,以检验空间映射的鲁棒性。结果表明,采用持续预训练(CPT)训练的模型在仅 GPS 条件下仍保持高性能,而仅 SFT 训练的模型性能显著下降,说明 CPT 能够获取独立于文本提示的可迁移空间知识。4B-Joint 模型在各项指标与输入模态上均取得最佳综合表现,证明多任务联合训练能够提升路线质量与泛化能力。持续预训练模型在仅 GPS 输入下维持高性能,表明空间知识获取独立于文本提示。仅 SFT 基线在移除文本提示时出现严重性能衰退,而基于 CPT 的模型下降幅度极小,凸显了预训练对稳健空间推理的重要性。4B-Joint 模型在所有指标与输入类型上均优于其他配置,证明多任务训练增强了模型处理多样化规划约束的能力。
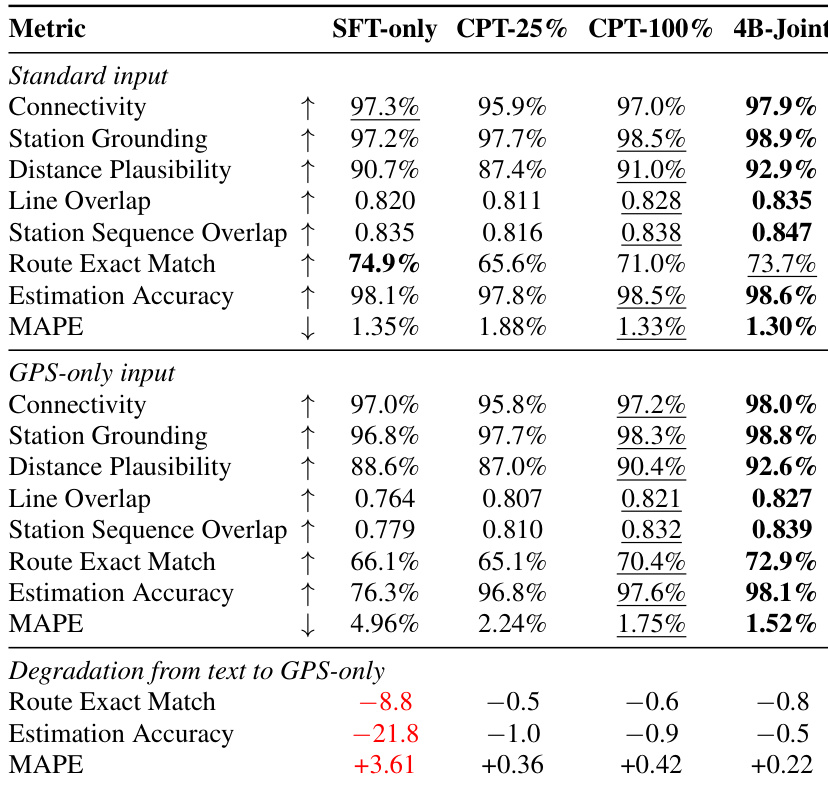
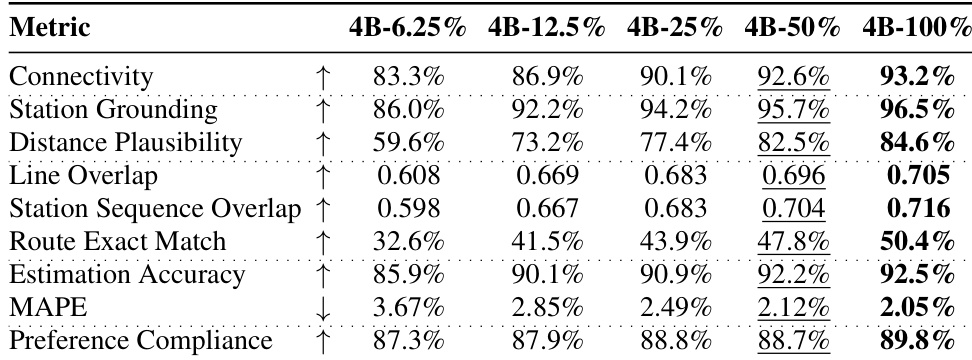
作者评估了持续预训练(CPT)数据量对领域专用模型在多项交通规划任务上表现的影响。结果显示,增加 CPT 数据量使所有指标均获得持续提升,基础连通性与站点映射指标改善迅速,而路线匹配与数值估算等复杂任务则需要显著更多的数据。即使移除文本提示,模型仍能保持强劲性能,表明空间知识通过 CPT 习得而非依赖输入语义。随着持续预训练数据量增加,所有评估指标均呈现单调上升趋势。基础连通性与站点映射指标在 CPT 数据量较少时即可达到较高水平,而路线匹配与数值准确率则需要更多数据。模型在仅 GPS 输入下维持高性能,说明空间映射通过 CPT 学习,而非依赖文本提示。
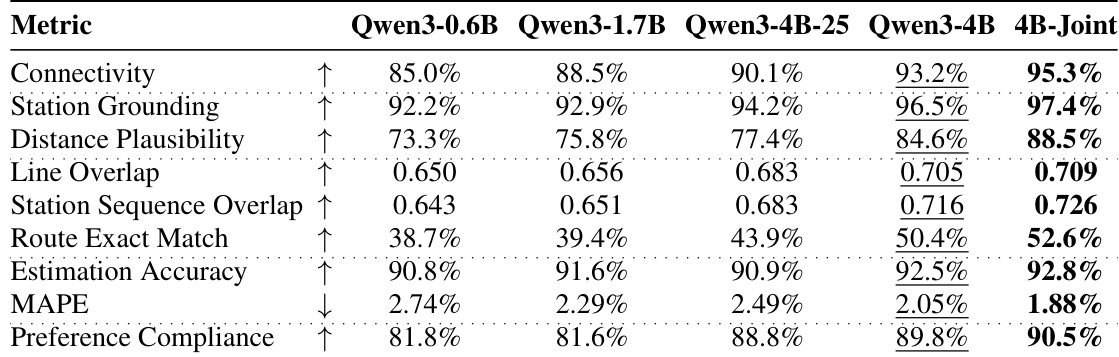
作者针对交通路线生成任务评估了多款模型,采用涵盖连通性、可达性可行性、路线重叠度与数值准确率的指标集。结果表明,领域专用模型显著优于通用大语言模型,且性能随模型规模扩大而提升,习得的空间表示在移除文本提示后依然稳健。表现最佳的模型实现了高连通性、准确的路线匹配,并在所有评估维度上表现优异。与通用大语言模型相比,领域专用模型在连通性与路线精确匹配上取得大幅提升。模型性能随规模增加而改善,最大规模模型在所有指标上均取得最佳结果。模型在仅 GPS 输入下维持强劲性能,表明空间知识独立于文本提示习得。
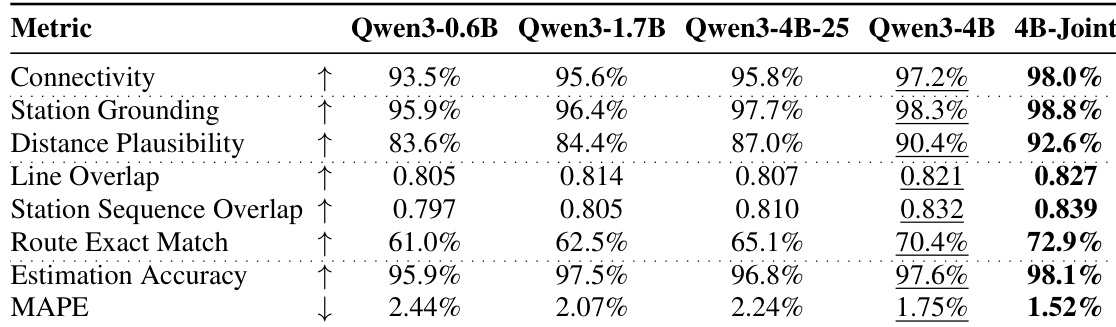
作者针对交通路线生成任务对比了多款模型,评估其在连通性、可达性可行性、路线重叠度与数值准确率方面的表现。结果显示,采用持续预训练的大规模模型实现了更高的连通性与路线精确匹配,而领域专用模型即使在仅 GPS 输入条件下仍能保持强劲性能。表现最佳的模型展现出高估算精度与较低的预测数值字段误差。相较于小规模模型,采用持续预训练的大规模模型在路线精确匹配与连通性上表现更佳。领域专用模型在仅 GPS 输入下维持高性能,表明空间映射源于训练数据而非依赖文本提示。最优模型在数值预测中实现高估算精度与低误差,且在移除文本输入时性能下降极小。
实验设置通过系统测试架构差异、训练方法与输入模态,评估大语言模型在交通路线生成任务上的表现。通用模型与领域专用模型的初步对比验证了专项训练能显著提升结构连通性与路线正确性。针对持续预训练与多任务学习的后续消融实验证实,空间推理能力可独立于文本提示习得,而规模扩展实验则确认了更大数据量与参数量可稳定提升复杂规划精度。