Command Palette
Search for a command to run...
感知还是偏见:多模态大语言模型能否超越对人格的初印象?
感知还是偏见:多模态大语言模型能否超越对人格的初印象?
摘要
多模态大语言模型(MLLMs)正日益被部署于需要人格感知的面向人类的角色中,然而现有基准测试仅通过预测大五人格(Big Five)的数值分数来评估这一能力,从而留下了一个未解之谜:模型究竟是通过行为理解真正感知了人格,还是仅仅通过浅层的模式匹配进行了预判。为填补这一空白,我们做出了三项贡献。(i)一项新任务:我们形式化了“基于证据的人格推理”(Grounded Personality Reasoning, GPR),该任务要求 MLLMs 通过评分、推理和基于证据的锚定链条,将每一项大五人格评分锚定在可观察的证据之上。(ii)一个新数据集:我们发布了 MM-OCEAN(包含 1,104 个视频和 5,320 道多项选择题),该数据集由多 agent 流水线生成并经人工验证,包含带时间戳的行为观察、基于证据的特质分析以及七类基于线索锚定的多项选择题。(iii)基准测试与分析:我们设计了一个三层评估体系(评分、推理、基于证据的锚定)以及四个样本级的失败模式指标:预判率(Prejudice Rate, PR)、虚构率(Confabulation Rate, CR)、整合失败率(Integration-failure Rate, IR)和整体基于证据的锚定率(Holistic-grounding Rate, HR),并对 27 个 MLLMs(13 个闭源,14 个开源)进行了基准测试。分析揭示了一个显著的“预判差距”(Prejudice Gap):在整个领域内,51% 的正确评分并未基于检索到的线索进行锚定,且整体基于证据的锚定率仅在 0-33.5% 之间波动。这些发现暴露了“获得正确分数”与“基于正确理由进行推理”之间的脱节,为 MLLMs 中的基于证据的社会认知绘制了路线图。
一句话总结
本研究提出扎根人格推理(Grounded Personality Reasoning, GPR)及包含1,104个视频与5,320道选择题的MM-OCEAN数据集,旨在将多模态大语言模型的评估从表浅的大五人格分数预测转向三级评估体系。该体系基于证据锚定的特质分析对27个模型进行基准测试,最终揭示出一个偏见差距:51%的准确人格评分缺乏可观察的行为依据。
核心贡献
- 形式化定义扎根人格推理(GPR)任务,要求模型通过结构化的评分、推理与扎根链条,将大五人格特质预测锚定于可观察的行为证据。该方法通过超越单纯的数值分数预测,明确区分了真实的心理感知与表浅的模式匹配。
- 推出MM-OCEAN数据集,该数据集包含1,104个视频与5,320道选择题,由经人工验证的多Agent流水线生成。该资源提供带时间戳的行为观测、基于证据的特质分析,以及七类线索扎根问题,用于详细评估。
- 建立三级评估框架,包含四项样本级失败模式指标(偏见率、虚构率、整合失败率与整体扎根率),并对27个多模态大语言模型(13个闭源,14个开源)在评分、推理与扎根阶段进行基准测试。分析揭示出偏见差距:51%的正确评分缺乏扎根的线索检索,整体扎根率仅在0%至33.5%之间波动。
引言
多模态大语言模型正快速进入高利害的人类交互应用场景,例如AI面试筛选与心理健康分诊。在这些场景中,准确感知人格特质对系统可信度与合规性至关重要。然而,以往的基准测试将此项能力简化为单纯的数值回归任务,致使模型能够通过表浅的模式匹配获得正确分数,而非基于真实的行为理解。为克服该局限,研究提出形式化定义扎根人格推理任务,要求模型通过结构化的评分、推理与扎根流程,将特质预测锚定于可观察的多模态证据。该框架辅以MM-OCEAN数据集与多级评估系统,揭示了普遍存在的偏见差距,表明当前多数模型虽能正确预测特质,却并未真正理解底层的行为线索。
数据集

- 数据集来源与构成: MM-OCEAN通过从ChaLearn First Impressions V2数据集中选取1,104个测试视频构建而成。该原始数据集提供约10,000段单人发言的15秒短视频片段,并附带众包标注的大五人格分数与自动语音识别转写文本。
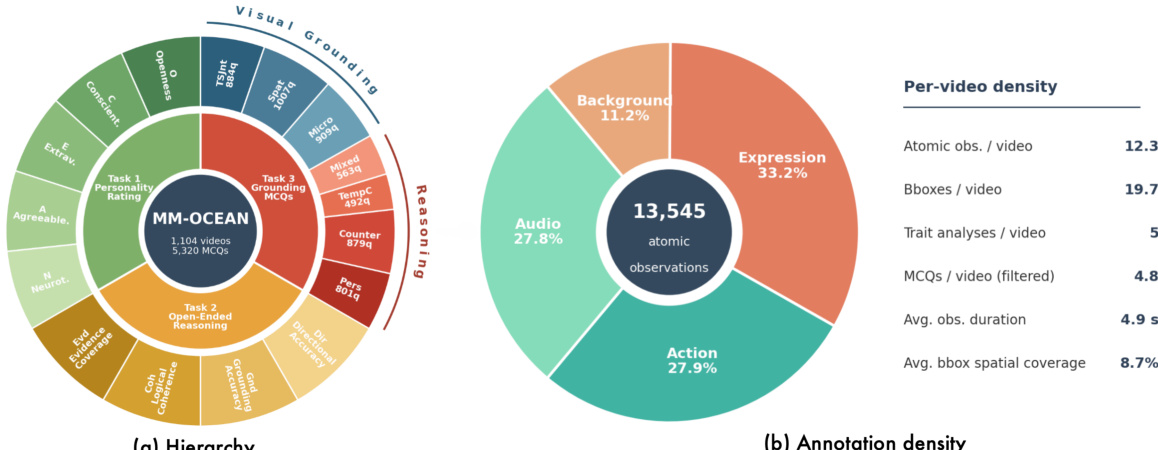
- 原子级行为观测: 基准测试包含约13,500条经人工验证的原子级线索,划分为四个感知通道:表情、动作、音频与背景。每条观测数据均包含唯一标识符、帧级精确时间戳、视觉事件紧密边界框、事实性描述及身体部位标签。
- 特质级分析: 数据集包含5,520份结构化人格分析报告,将原始连续的大五人格分数离散化为五个有序等级。每份报告提供特质评估、加权置信度的推理依据,以及明确引用特定行为线索标识符作为证据的推理链条。
- 线索扎根问题: 发布内容包含5,320道选择题,平均每视频4.8道,旨在测试七类社会认知能力,包括人格归因、反事实推理与时空扎根。每道题目提供六个选项,干扰项专门设计用于探测文本推导错误与近失错误等特定失败模式。
- 标注流水线与过滤: 数据构建采用五阶段多Agent流水线,交替运行LLM Agent与人工验证环节。Observer Agent起草初始线索,由24名人工标注员进行审核、修正或删除,同时优化时空标注。Aligner Agent执行自动化质量保障,最后的文本泄漏过滤器会剔除仅凭转写文本即可被两个纯文本语言模型正确回答的题目,确保所有保留项目均依赖多模态扎根。
- 元数据与裁剪策略: 标注员为所有保留的表情与动作观测绘制紧密边界框,并将起止时间戳对齐至最接近的感知有效帧。元数据强制执行严格的扎根约束,要求人格分析报告必须引用有效的线索ID,且题目需使用经验证标注池中的精确时间戳锚点与边界框坐标。
- 预期用途: 该数据集仅作为预留评估基准,用于评估多模态模型将人格判断扎根于可观察行为证据的能力。本资源专用于扎根推理相关的学术研究,明确不建议在未经明确同意与公平性审计的情况下,将其用于自动化人格筛选或招聘应用。
方法
MM-OCEAN被设计为一种多阶段扎根人格推理框架,围绕三项核心任务构建,逐步评估模型基于多模态视频数据推理人格特质的能力。整体流程以输入视频序列 V=(Vvis,Vaud,Vtxt) 为起点,该序列包含视觉帧、音频与语音转写文本,随后通过生成人格评分、开放式推理与结构化线索扎根的流水线进行处理。该框架依托人机协作的标注流程,确保输出高质量且基于证据的扎根结果。
第一阶段为原子级线索标注,涉及Observer与Annotator角色,负责识别并标记视频中的原子级感知线索。这些线索划分为四个维度:表情、动作、音频与背景,每条线索均标注起止时间戳、文本描述,并在适用时附加边界框坐标。该阶段输出一组原子级观测数据,供后续推理任务使用。标注结果经过过滤与专家审核流程进行优化,其中纯文本大语言模型(LLM)用于评估生成的多选题(MCQ)质量,人类专家标注员则审核推理依据与题目,以确保逻辑连贯性与扎根可靠性。
如图所示,七类线索扎根MCQ题目被划分为两个集群:推理类(涉及语义与因果推断)与视觉扎根类(专注于像素级与时间级定位)。这些类别被系统性地应用于三项任务中,以确保对模型推理能力的全面评估。
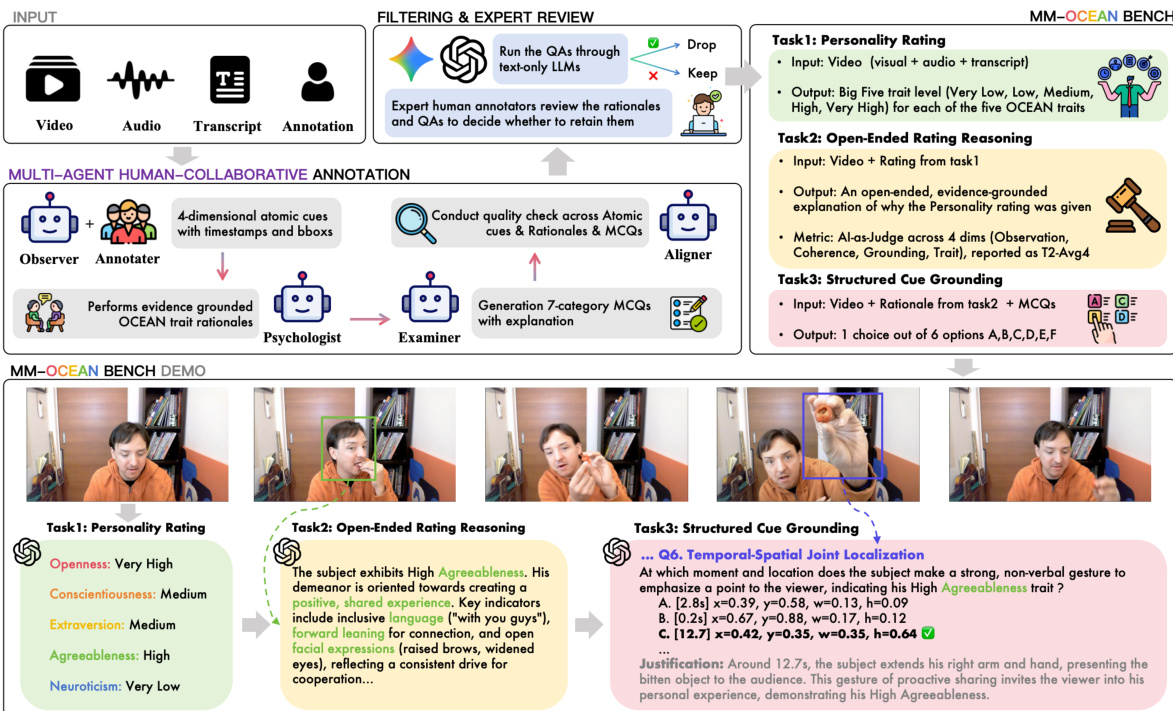
第二阶段为特质推理,由Psychologist Agent负责生成人格评分的开放式解释。该Agent利用原子级观测数据,为五大人格特质分别生成推理依据,确保推理过程扎根于实际观测线索。第三阶段为MCQ生成,由Examiner Agent基于推理结果与观测数据创建多选题,重点保障题目逻辑一致且与观测数据相符。最终阶段为质量保障,由Aligner Agent对原子级线索、推理依据与MCQ执行全面质量检查,确保输出内容连贯准确。
该框架旨在通过三项独立任务评估模型:任务1(人格评分),要求预测大五人格特质等级;任务2(开放式评分推理),要求生成扎根的评分解释;任务3(结构化线索扎根),要求基于视频与推理依据从多选题集中选出正确选项。每项任务均针对模型推理能力的不同维度进行设计,核心聚焦于确保预测结果扎根于观测数据。

原子级观测数据分布于四个感知通道中,表情与动作观测占据显著密度,如图所示。逐视频统计进一步细化了标注密度,表明每个视频平均包含13,545条原子级观测,其中表情与动作观测占比极高。该分布反映了视觉与听觉线索在人格推理中的重要性,框架设计旨在有效捕捉并利用这些线索。
实验
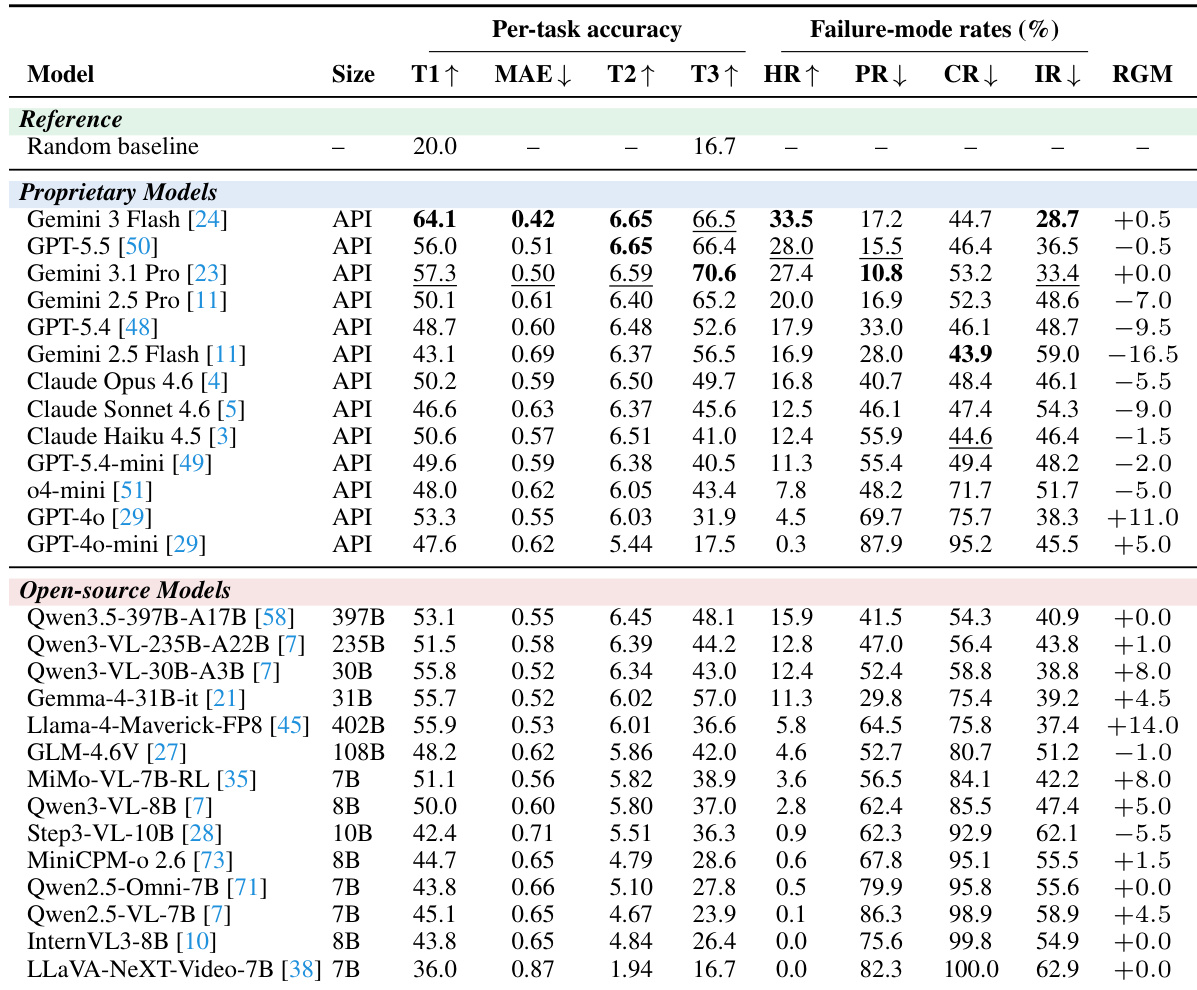
MM-OCEAN基准测试在三项逐步递进的任务中评估了27个多模态大语言模型,验证基础人格预测能力、开放式解释的连贯性以及行为证据的精确定位能力。该多任务框架揭示出普遍存在的偏见差距:多数正确评分缺乏可验证的扎根依据,表明传统以评分为核心的评估体系会系统性高估模型能力。尽管闭源与开源系统在初始预测与语言推理方面表现相近,但在细粒度时空线索检索方面存在显著鸿沟。最终,整体扎根指标有效区分了不同的模型推理模式,并表明优先开展基于证据的后续训练对于开发可信的人格感知AI至关重要。
{"summary": "实验在三项任务中评估了27个多模态模型:有序人格评分、开放式推理与结构化线索扎根。结果表明,尽管模型在评分与推理任务上表现相近,但在线索检索方面存在显著差距,闭源模型优于开源模型。评估揭示出广泛存在的偏见差距,许多正确评分缺乏扎根证据,凸显了人格推理中更可靠扎根机制的必要性。", "highlights": ["与开源模型相比,闭源模型在线索检索方面展现出显著优势,而在评分与推理任务上表现相近。", "所有模型均存在显著的偏见差距,许多正确评分缺乏扎根证据,表明人格推理需要改进扎根机制。", "评估揭示了评分成功与可信推理之间的强烈脱节,部分模型在评分上表现优异但在扎根上失败,反之亦然。"]}
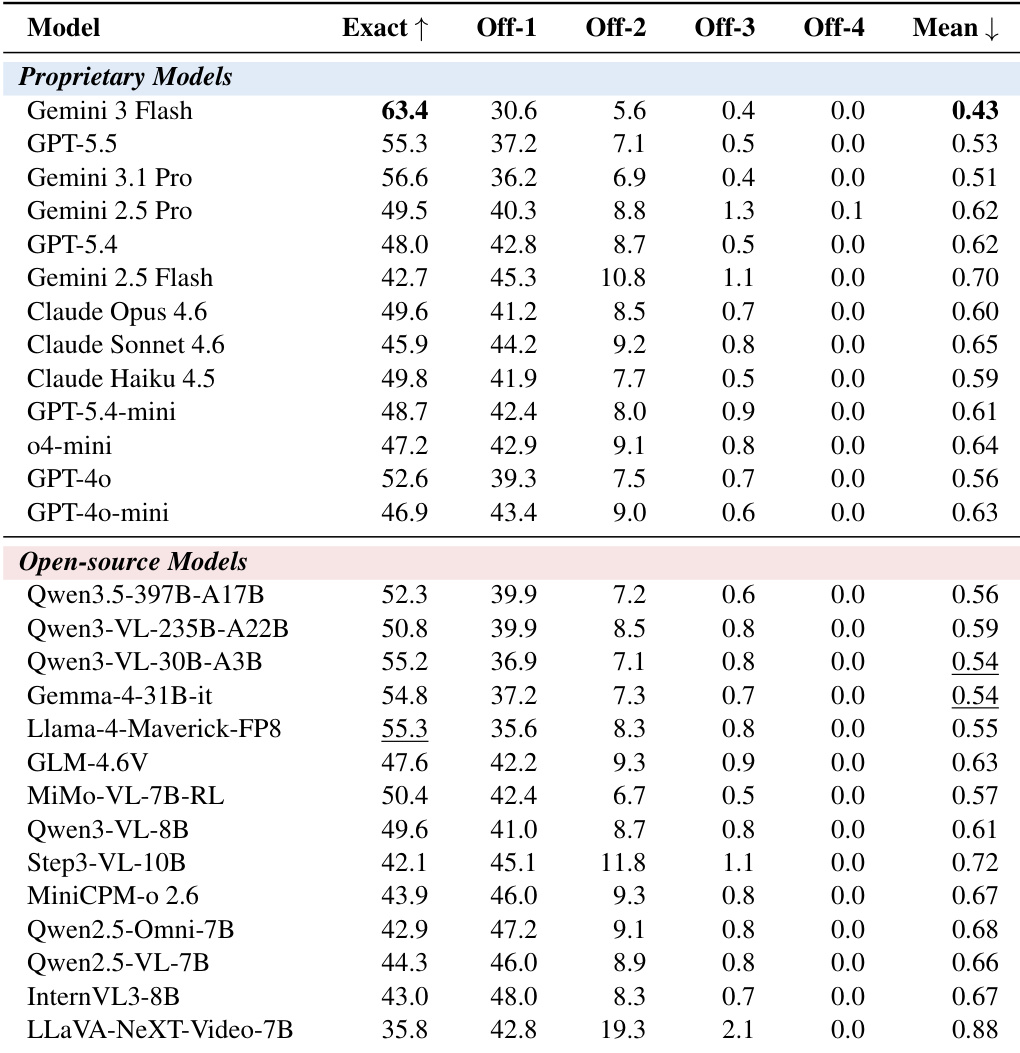
研究在三项评估人格评分、推理与线索扎根的任务中测试了27个多模态语言模型,揭示出广泛存在的偏见差距,即许多正确评分缺乏扎根证据。结果显示,尽管模型在评分与解释任务上表现相近,但在线索检索方面存在显著性能差距,闭源模型优于开源模型。整体扎根率成为一项高区分度指标,能够超越单一任务准确率,暴露出模型在可信推理方面的差异。模型普遍表现出偏见差距,多数正确人格评分缺乏扎根证据。闭源模型在线索检索方面显著优于开源模型,但在评分或推理任务上并无明显优势。整体扎根率是一项高区分度指标,比单一任务得分更能有效揭示模型差异。
实验在三项评估人格评分、推理与线索扎根的任务中测试了27个多模态模型,揭示出广泛存在的偏见差距,即多数正确评分缺乏扎根证据。评估凸显了闭源与开源模型在线索检索方面的显著差异,前者大幅领先后者。整体扎根率成为一项高区分度指标,能够识别具备可信推理能力的模型,暴露出传统仅关注评分的评估体系未能显现的性能差距。偏见差距普遍存在,超过半数的正确人格评分缺乏扎根证据。闭源模型在线索检索方面显著优于开源模型,而在评分与推理任务上表现相近。整体扎根率通过揭示那些将准确评分与扎根推理相结合的模型,有效区分了不同系统的性能。
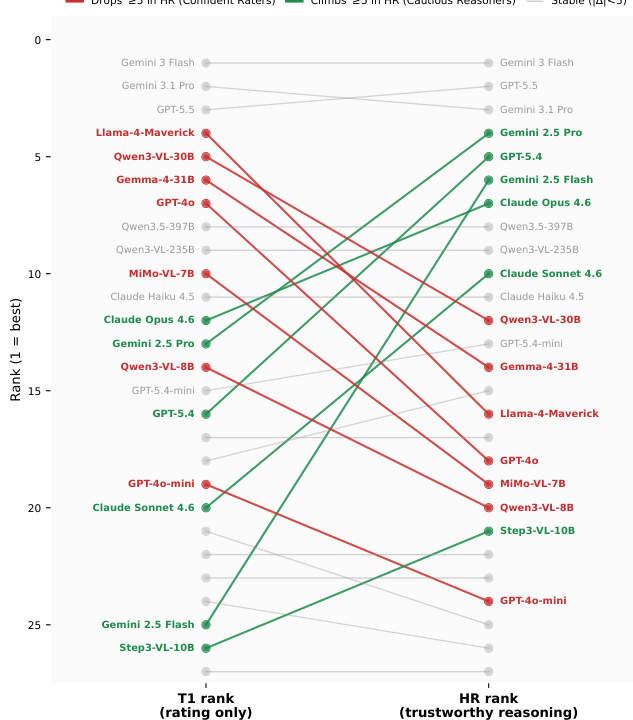
研究通过比较不同裁判模型下的排名并评估性能一致性,检验了AI-as-Judge协议的鲁棒性。结果显示,主裁判与替代裁判之间的高度Spearman相关性表明评估结果稳定可靠。同家族内部检查揭示了轻微的校准偏移,但未对模型的相对排名造成显著干扰。主裁判与替代裁判之间的高排名相关性印证了评估结果的稳健性。AI-as-Judge协议在不同裁判家族中表现出一致的性能,对模型排名的影响极小。裁判间存在微小的校准差异,但不会影响模型的相对排名。

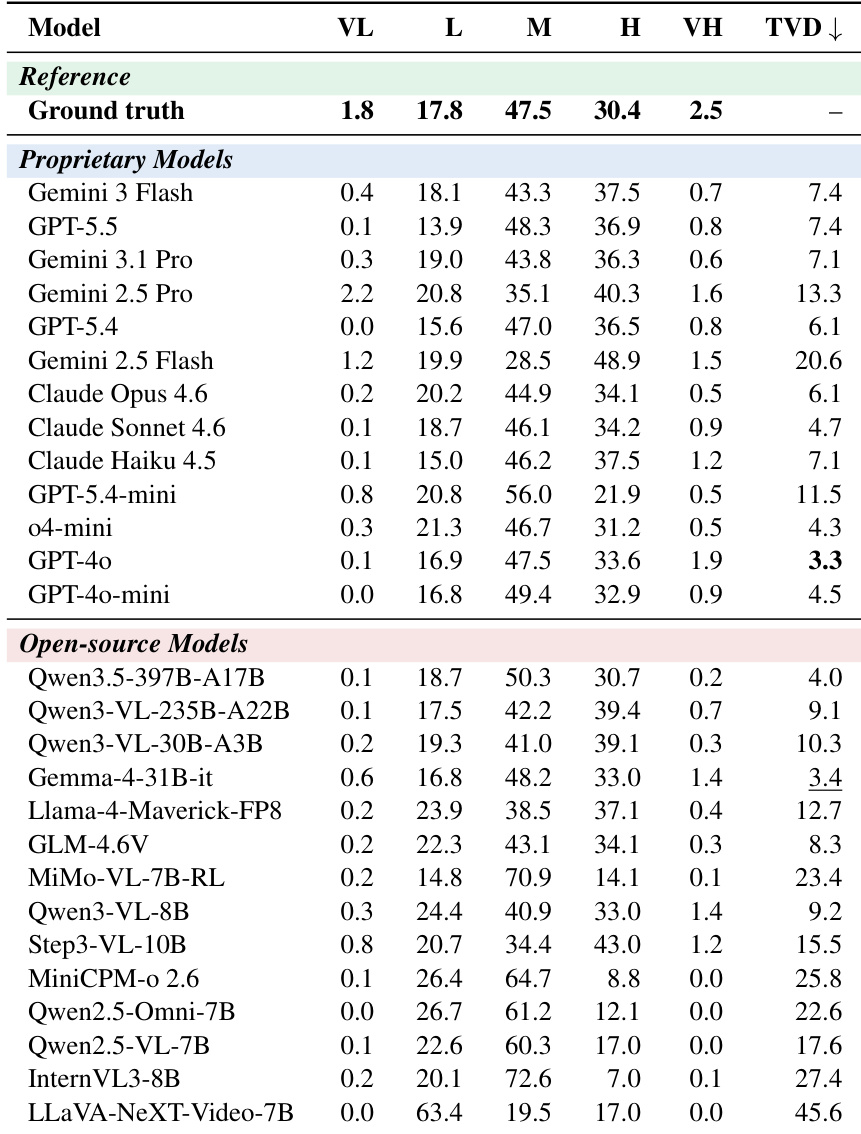
表格展示了不同人格特质与预测分布下的模型性能对比,凸显了闭源与开源模型之间的差距。闭源模型在预测特定特质时通常表现出更高的准确率,而开源模型的预测变异性更高,置信度更低,尤其在“极低”与“极高”类别中更为明显。总变差距离(TVD)用于衡量模型预测与真实标签的对齐程度,数值越低表明对齐效果越好。闭源模型在人格特质预测准确率上优于开源模型。开源模型的预测变异性更大,尤其在极低与极高类别中。总变差距离(TVD)反映了模型预测与真实标签的对齐情况,较低数值代表更优性能。
评估在人格评分、推理与线索扎根任务中检验了27个多模态模型,同时独立验证确认了AI-as-Judge协议的稳定性。核心实验揭示出准确人格评分与可信推理之间普遍存在的脱节现象,因为多数正确预测缺乏扎实扎根的证据。实验还表明,闭源模型在线索检索与预测一致性方面具有明显优势,而开源系统表现出更大的变异性。最终,整体扎根指标成功筛选出具备可靠推理能力的模型,且评估框架在不同裁判实现中均表现出鲁棒性,未改变模型的相对排名。