Command Palette
Search for a command to run...
ACC:编译 Agent 轨迹以进行长上下文训练
ACC:编译 Agent 轨迹以进行长上下文训练
摘要
标题:摘要:智能体(agents)的近期发展重新激发了对大语言模型(LLMs)长上下文推理能力的需求。然而,为此训练大语言模型需要高昂的长文档整理或启发式上下文合成成本。我们观察到,智能体在解决问题时会产生大量的轨迹(trajectories),在多轮交互中调用工具并接收环境观测结果。因此,回答原始问题所需的证据分散在这些轮次中,需要整合远距离的上下文片段。然而,标准的智能体监督微调(SFT)会屏蔽工具响应,仅训练轮次级的工具选择,从而造成监督盲区,使得这些分散的信号未被利用。我们提出了智能体上下文编译(Agent Context Compilation, ACC),将来自搜索、软件工程和数据库查询智能体的轨迹转换为长上下文问答对,将原始问题与跨多轮收集的工具响应和环境观测结果相结合,训练模型在不使用工具的情况下直接回答问题。这使得问题与证据之间的依赖关系显式化,从而能够在无需额外标注的情况下,对远距离片段的长上下文推理进行直接监督。ACC 是一种简单但有效的方法,可与任何现有的长上下文扩展或训练方法结合使用,提供可扩展的监督微调数据。我们通过 MRCR 和 GraphWalks 在长程依赖建模任务上验证了 ACC,这两个具有挑战性的基准测试要求跨轮次共指解析以及在扩展上下文中的图遍历。使用 ACC 训练 Qwen3-30B-A3B 模型,在 MRCR 上达到 68.3(+18.1),在 GraphWalks 上达到 77.5(+7.6),结果与 Qwen3-235B-A22B 相当,同时保持了在 GPQA、MMLU-Pro、AIME 和 IFEval 上的通用能力。进一步的机制分析表明,经过 ACC 训练的模型表现出任务自适应的注意力重构和专家专业化。
一句话总结
Agent Context Compilation (ACC) 将多轮 agent 轨迹转换为长上下文问答对,整合了跨轮次的分散工具响应与环境观测,从而支持可扩展的监督微调,在无需额外标注或工具使用的情况下,直接对远距离上下文片段进行监督。
核心贡献
- Agent Context Compilation (ACC) 将来自搜索、软件工程与数据库查询 agent 的多轮轨迹转换为长上下文问答对。该过程聚合分散的工具响应与环境观测,显式建立远距离证据与原始查询的关联,从而实现无需人工标注的直接监督微调。
- 使用 ACC 微调 Qwen3-30B-A3B 在 MRCR 上取得 68.3 分,在 GraphWalks 上取得 77.5 分,性能与 Qwen3-235B-A22B 相当,同时保持了在 GPQA、MMLU-Pro、AIME 和 IFEval 上的通用能力。
- 机制分析表明,ACC 训练引发了任务自适应的注意力重构与专家专业化,证明长程推理能力以灵活且上下文特定的注意力模式涌现。
引言
AI agent 的快速普及加剧了大语言模型在扩展上下文中进行有效推理的需求,因为 agent 通常需要通过数十次工具调用与环境观测来收集分散的证据。构建该能力的现有方法依赖于昂贵的长文档整理、启发式合成或复杂的后训练流水线,而标准的 agent 微调会遮蔽中间工具响应,仅对轮次级决策进行监督。这造成了监督盲区,导致宝贵的跨轮次信号未被利用。本文通过引入 Agent Context Compilation (ACC) 方法,利用这些被忽视的 agent 轨迹,将多轮交互转换为长上下文问答对。通过显式对齐原始查询与完整的工具响应及观测序列,ACC 实现了无需额外标注的长程推理直接监督微调,在保持模型通用能力的同时,显著提升了跨轮次依赖基准测试的性能。
数据集

-
数据集构成与来源: 本文从跨越三个操作领域的自主 agent 轨迹中构建 ACC 数据集,涵盖网页搜索、软件工程与 SQL 数据库查询。
-
子集详情与过滤规则: 最终数据集包含 10,802 条已验证轨迹,细分为 3,369 条搜索样本、4,368 条软件工程样本和 3,065 条 SQL 样本。答案验证通过率在不同领域存在差异,搜索领域稳定在 100% 左右,SQL 领域为 50%,软件工程领域为 10%。每个样本包含的编译上下文长度在 2,000 到 128,000 tokens 之间,长度分布经过刻意调整以匹配各类 agent 的特性。
-
处理与上下文构建: 对于每条轨迹,提取自包含的证据片段,确保无需进一步工具调用即可回答原始查询。搜索 agent 提供已访问页面的完整文本,并将未访问结果作为干扰项。软件工程 agent 提供正确补丁对应的文件以及额外的调试上下文文件。SQL agent 包含所有查询表的完整内容。为消除位置偏差,证据片段经过随机打乱后拼接,直至达到严格的 token 预算限制。候选推理轨迹使用 DeepSeek-V3.2-Thinking 生成,并经过严格过滤,仅保留能成功抵达真实答案的路径。最终训练格式被构建为包含原始问题、打乱的编译上下文以及已验证推理轨迹的三元组。
-
模型使用与训练配置: 本文使用完整的编译混合数据对 Qwen3-30B-A3B-Thinking 基础模型进行监督微调。训练过程未划分明确的训练集与验证集,而是利用多样化的 token 分布与打乱证据来强化标准长上下文基准测试中的长程依赖建模与多跳推理能力。
方法
本文采用名为 Agent Context Compilation (ACC) 的框架,以解决标准 agent 监督微调 (SFT) 中固有的监督盲区问题。在传统的 agent SFT 中,训练目标仅对每轮模型推理与 action tokens 进行监督,所有工具响应(观测)均被遮蔽并排除在损失函数之外。这造成了结构性局限:跨多轮收集的中间证据未受最终答案监督的直接引导,导致分散信息的整合效果次优。模型倾向于学习优化局部的下一步工具选择,而非综合生成连贯的全局答案。
为克服此问题,ACC 通过重构训练数据,将 agent 的完整轨迹编译为单个长上下文问答对。如图下所示,该流程始于初始任务,随后经历一系列涉及大语言模型推理、工具使用与环境响应的交互。每次交互生成工具响应或环境上下文,这些内容被收集并聚合为统一上下文 C。该编译上下文与原始问题 q 共同构成重新训练模型的输入。模型随后被训练直接从该长上下文中生成推理轨迹 r 与最终答案 y,无需任何中间 action 监督。
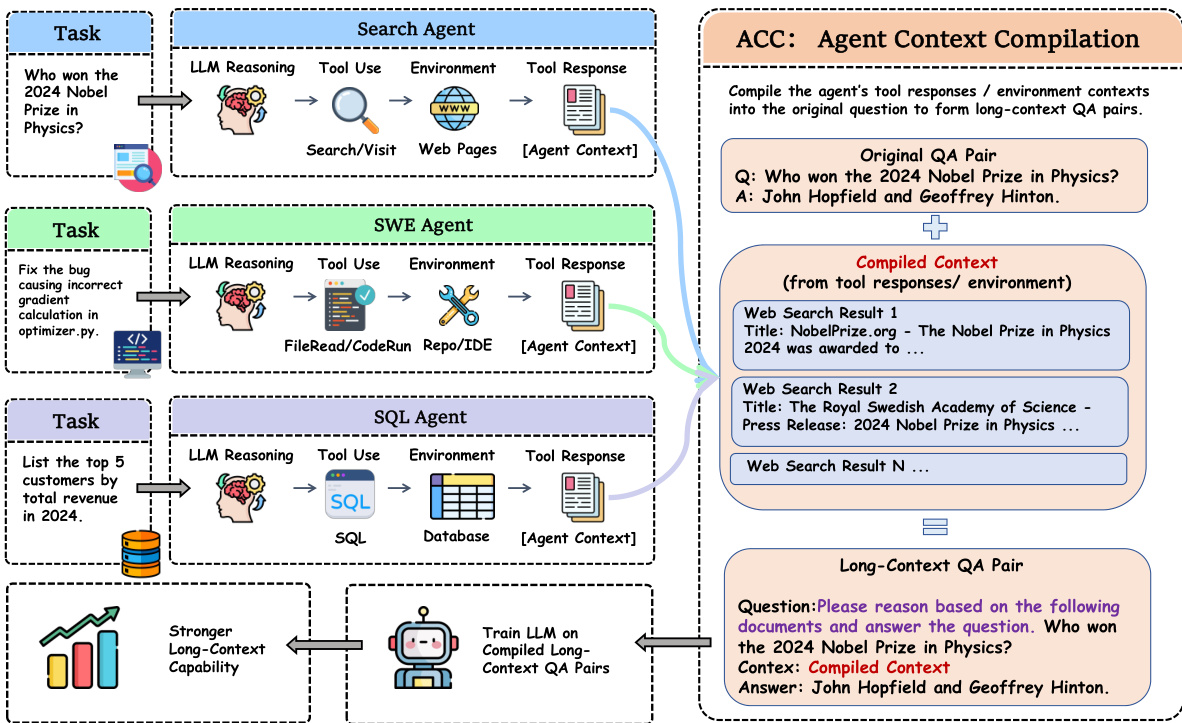
ACC 的训练目标定义为 LACC=−∑j∈r∪ylogP(tokenj∣q,C,token<j)。该目标直接监督从编译上下文生成最终答案与推理轨迹的过程,确保最终答案的梯度直接流向上下文 C 中的每一个 token,无论其在原始轨迹中的位置如何。这消除了标准 SFT 中存在的长链依赖问题,在标准 SFT 中,最终答案的梯度在反向传播至早期轮次工具响应时会严重衰减。通过将全部证据归入单一上下文,ACC 使模型能够学习跨轮次整合信息,并发展出更强的长上下文能力。生成的数据集由编译后的问答对 (xi,yi,ri) 组成,其中 xi 为原始查询与编译上下文的拼接,yi 与 ri 分别为原始轨迹中的最终答案与推理轨迹。该方法使模型能够学习对任务的整体性理解,直接将所有证据与最终输出相连。
实验
评估涵盖通用能力基准、对比基线、组件消融实验与内部机制分析,以验证模型在长上下文推理方面的增强效果。结果证实,该方法通过标准监督微调超越了复杂的多阶段流水线,且在无数据泄露的情况下保持了通用能力。消融实验进一步表明,整合多样化的 agent 轨迹与战略性干扰项为证据定位与跨域推理提供了互补收益。最后,机制分析揭示训练引发了注意力范围与专家路由的灵活、任务特定重构,证实模型会自适应优化其内部处理机制以应对长程依赖。
本文在通用能力基准上评估了 ACC 方法,并与强基线进行对比。结果显示,ACC 在大多数指标上取得小幅提升,同时在其他指标上保持原有性能,表明通用能力未出现显著退化。模型在所有评估任务上均优于基线,在基础模型与强基线设置下均观察到一致的性能增益。与基础模型相比,ACC 在多项通用能力基准上实现了一致的性能提升。ACC 带来的性能增益稳定,未显示对通用能力的负迁移。ACC 在所有评估任务上均优于强基线,证明了其有效性。
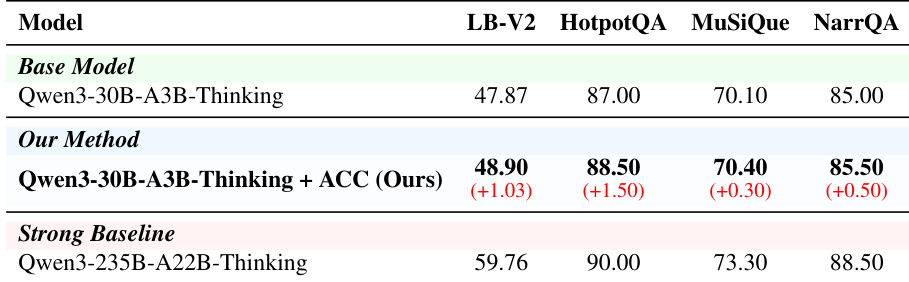
本文展示了消融实验,对比了不同训练配置、基础模型与所提方法。结果显示,所提方法在 MRCR 与 GraphWalks 上均取得最高性能,优于所有单一 agent 类型变体与消融版本。完整方法在两项任务上均表现出一致的提升,表明结合多样化轨迹类型并保留干扰项能够增强整体能力。与所有消融变体相比,所提方法在 MRCR 与 GraphWalks 上均取得最佳性能。使用单一 agent 类型训练的性能优于基础模型,但完整混合数据的表现优于所有单一 agent 变体。移除干扰项对 MRCR 性能产生负面影响,但提升了 GraphWalks 的结果,表明干扰项具有任务特定的收益。
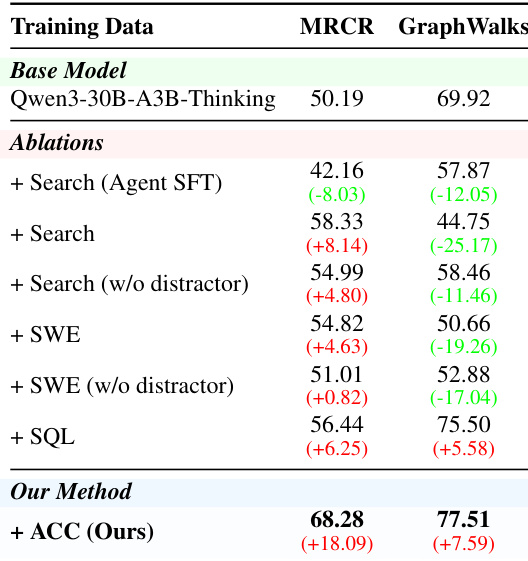
本文在通用能力基准上对比了所提方法与基础模型,结果显示大多数任务性能提升,其余任务仅有极小退化。结果表明,所提方法在提升性能的同时未引入显著的负迁移,性能提升归因于推理能力增强而非数据泄露。该方法在大多数通用能力基准上实现提升,同时在其他基准上保持稳定。语义分布分析证实,性能增益源于推理改善而非测试集泄露。该方法未对通用能力引入明显退化,表明基线能力得到有效保留。

本文将所提方法与现有长上下文后训练方法进行比较,显示模型在 MRCR 与 GraphWalks 上取得了具有竞争力的性能。结果表明,该方法在多项基线上表现更优,尤其在长上下文推理能力方面,同时保持了通用能力。与多种现有长上下文后训练方法相比,所提方法在 MRCR 与 GraphWalks 上取得了更高的性能。模型在 MRCR 与 GraphWalks 评估中均超越了 QwenLong-L1.5-30B 及其他 LongRLVR 变体。结果证明,该方法在提升关键基准性能的同时,保持了强大的长上下文推理能力。
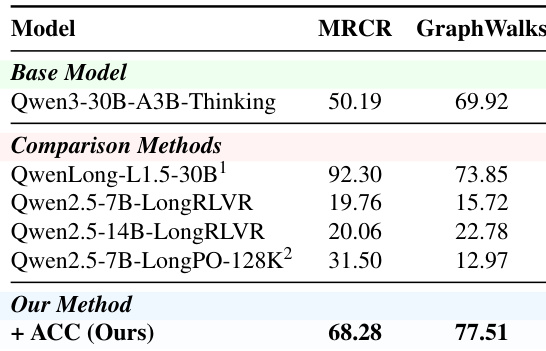
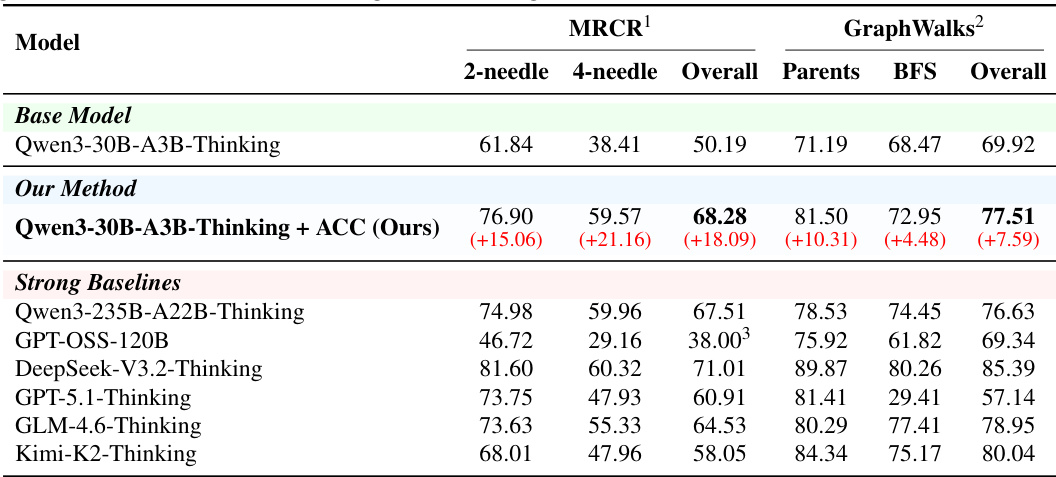
本文在 MRCR 与 GraphWalks 两项任务上,将 Qwen3-30B-A3B-Thinking + ACC 方法与多个强基线进行了对比。结果显示,该方法相较于基础模型取得了显著改善,并在两项任务上均优于所有列出的基线,其中 MRCR 提升尤为突出,GraphWalks 整体性能也有显著进步。与所有列出基线相比,该方法在 MRCR 与 GraphWalks 上均取得最高性能。模型在 MRCR 上展现出最大幅度的提升,在 2-needle 与 4-needle 子任务中均有显著增益。在 GraphWalks 上,模型实现了整体显著提升,在 Parents 与 BFS 子任务中均取得显著进展。
本文在通用能力基准与长上下文推理任务上,将所提 ACC 方法与基础模型、强基线、消融变体及现有长上下文方法进行了全面评估。实验验证了结合多样化训练轨迹与保留干扰项能够持续产出更优性能,同时保持基线能力。分析证实这些增益源于推理能力增强而非数据泄露,展示了该方法在不同配置下的鲁棒性。最终,该方法为提升长上下文理解能力建立了一个可靠框架,且未牺牲模型的通用能力。