Command Palette
Search for a command to run...
全注意力卷土重来:在百步训练内将全注意力转移至稀疏
全注意力卷土重来:在百步训练内将全注意力转移至稀疏
Yanke Zhou Yiduo Li Hanlin Tang Maohua Li Kan Liu Lan Tao Lin Qu Yuan Yao Xiaoxing Ma
摘要
大型语言模型中的长上下文推理受限于全注意力机制的二次方计算成本。现有的高效替代方案通常依赖于原生稀疏训练或启发式 token 淘汰策略,从而在效率、训练成本和准确性之间产生不理想权衡。在本工作中,我们表明全注意力大型语言模型本质上已经具有稀疏性,并且只需极少的适配即可转化为高度稀疏的模型。我们的方法基于以下三个观察结果:(1)只有少量注意力头真正需要完整的长上下文处理;(2)长程检索主要由低维子空间主导,使得相关 tokens 可以通过一个 16 维的索引器高效检索;(3)有用 token 预算强烈依赖于查询,使得动态 top-p 选择比固定的 top-k 稀疏化更为合适。基于这些见解,我们提出了 RTPurbo,该方法仅对检索头保留完整的 KV 缓存,并引入轻量级 token 索引器以实现稀疏注意力。通过利用模型固有的稀疏性,RTPurbo 仅需数百步训练即可完成稀疏化。在长上下文基准和推理任务上的实验表明,RTPurbo 在保持近乎无损精度的同时,带来了显著的效率提升,包括在 1M 上下文长度下预填充速度最高提升 9.36 倍,解码速度提升约 2.01 倍。这些结果表明,无需昂贵的原生稀疏预训练,仅通过标准的全注意力训练即可获得强大的稀疏推理能力。
一句话总结
RTPURBO 通过在长上下文推理中仅对检索注意力头(retrieval heads)保留完整的键值缓存,并采用轻量级十六维索引器结合查询依赖的 token 选择机制,高效地对全注意力语言模型进行稀疏化处理,仅需数百个训练步骤即可实现近无损的准确率与显著的效率提升。
核心贡献
- 本文提出 RTPURBO,一种稀疏推理框架。该框架仅对专门用于检索的注意力头保留完整的 KV 缓存,同时为其余所有头部署轻量级 16 维 token 索引器,从而缓解长上下文大语言模型(LLM)的二次方计算成本。
- 该方法通过仅需数百个训练步骤的极简适配实现快速稀疏化,利用查询依赖的动态 top-p 选择机制,替代了高昂的原生稀疏预训练与静态 top-k 淘汰策略。
- 在长上下文基准测试与推理任务上的评估表明,该框架在保持近无损准确率的同时,在百万 token 场景下可实现最高 9.36 倍的 prefill 加速,以及约 2.01 倍的 decode 加速。
引言
长上下文推理对于将大语言模型部署于长文档中至关重要,但其性能仍受限于全注意力机制的二次方计算成本。以往的效率优化方法通常依赖高昂的原生稀疏预训练,或依赖僵化的启发式 token 淘汰策略,迫使实践者在推理速度、训练开销与下游准确率之间做出妥协。作者利用预训练模型固有的稀疏性,识别出处理长程上下文的少数检索头,同时为其余注意力头应用轻量级 16 维索引器与查询依赖的动态 top-p 稀疏化策略。该策略被形式化为 RTPURBO,仅需数百个训练步骤即可将标准全注意力模型转化为高度稀疏的架构,在保持近无损准确率的同时实现显著的 prefill 与 decode 加速。
方法
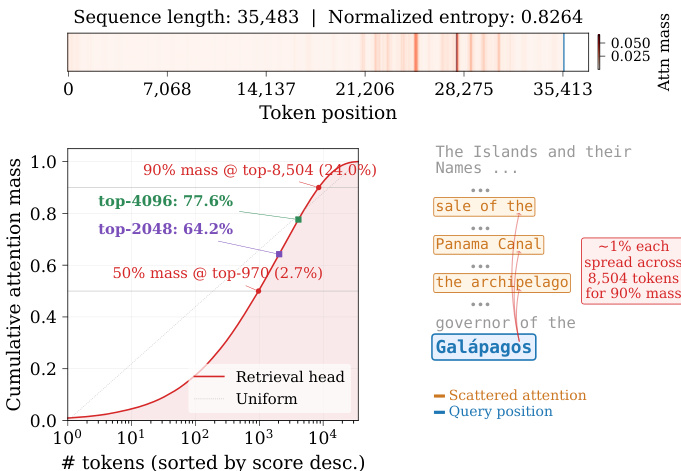
作者利用基于注意力头的框架 RTPURBO,在保持性能的同时实现大语言模型的高效稀疏推理。整体架构的设计基于以下观察:全注意力模型本质上具有稀疏性,部分头充当检索机制,关注语义相关但空间距离较远的 token,而其他头则聚焦于局部上下文。这一洞察得到了插图中检索头关注语义相似但空间距离较远 token 的行为支持,构成了选择性稀疏化策略的基础。

该方法首先通过离线校准流程来识别检索头。具体做法是在长文档的开头与结尾构建包含“针”(needle)片段的校准序列。通过测量从后一个“针”到前一个“针”的注意力质量(attention mass),来量化每个头的检索能力。该过程稳定且与输入无关,允许一次性将所有头划分为检索集 Hret 与局部集 Hloc。
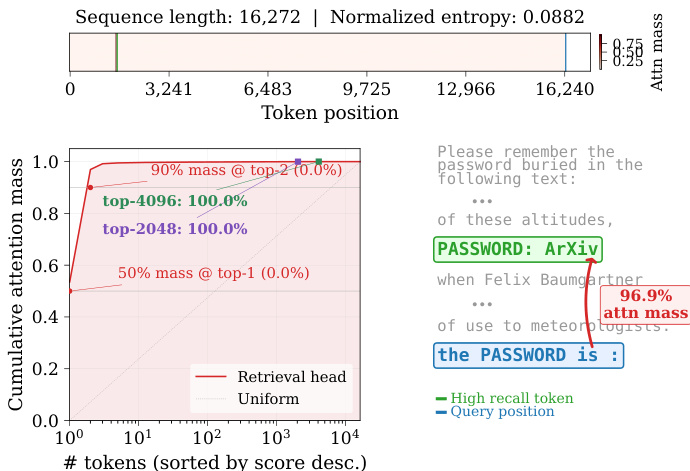
在推理阶段,该框架对两种类型的头采用不同的运作方式。局部头在 prefill 与 decode 阶段均持续应用带有注意力吸收(attention sinks)的滑动窗口机制。相比之下,检索头在 prefill 阶段执行完整的全量密集注意力以构建完整的 KV 缓存,但在 decode 阶段切换为动态稀疏选择。检索头稀疏机制的核心是对 pre-RoPE 查询与键表示 qm,hpre 和 kn,hpre 应用低秩投影,使用可训练权重 WhQ 和 WhK。该投影 sh(m,n)=(WhQqm,hpre)⊤(WhKkn,hpre) 在低维空间中高效计算相关性得分。随后,使用动态 Top-p 规则进行 token 选择,其中活跃集 Sh(m) 定义为累积注意力质量超过阈值 p 的 token 集合。该方法的动机基于以下观察:高频 RoPE 组件会削弱长程相关性,而低频组件能更好地保留检索信号,这一现象在插图中长程召回以低旋转分量为主导的情况中得到印证。
为使模型适应该稀疏机制,采用轻量级两阶段训练流程。第一阶段冻结主干模型,并独立训练每个检索头的低维投影权重 WhQ 和 WhK。具体做法是最小化原始密集注意力分布与由投影得分导出的分布之间的 KL 散度(Kullback-Leibler divergence)。第二阶段涉及自蒸馏过程,稀疏模型作为学生模型,以匹配原始密集模型的 next-token 预测。为降低计算开销,仅使用教师模型的 top-10 logits 进行此对齐操作。整体架构(包含两种头类型的 prefill 与 decode 阶段)在插图中展示,呈现了从离线校准到 decode 阶段动态稀疏选择的流程。
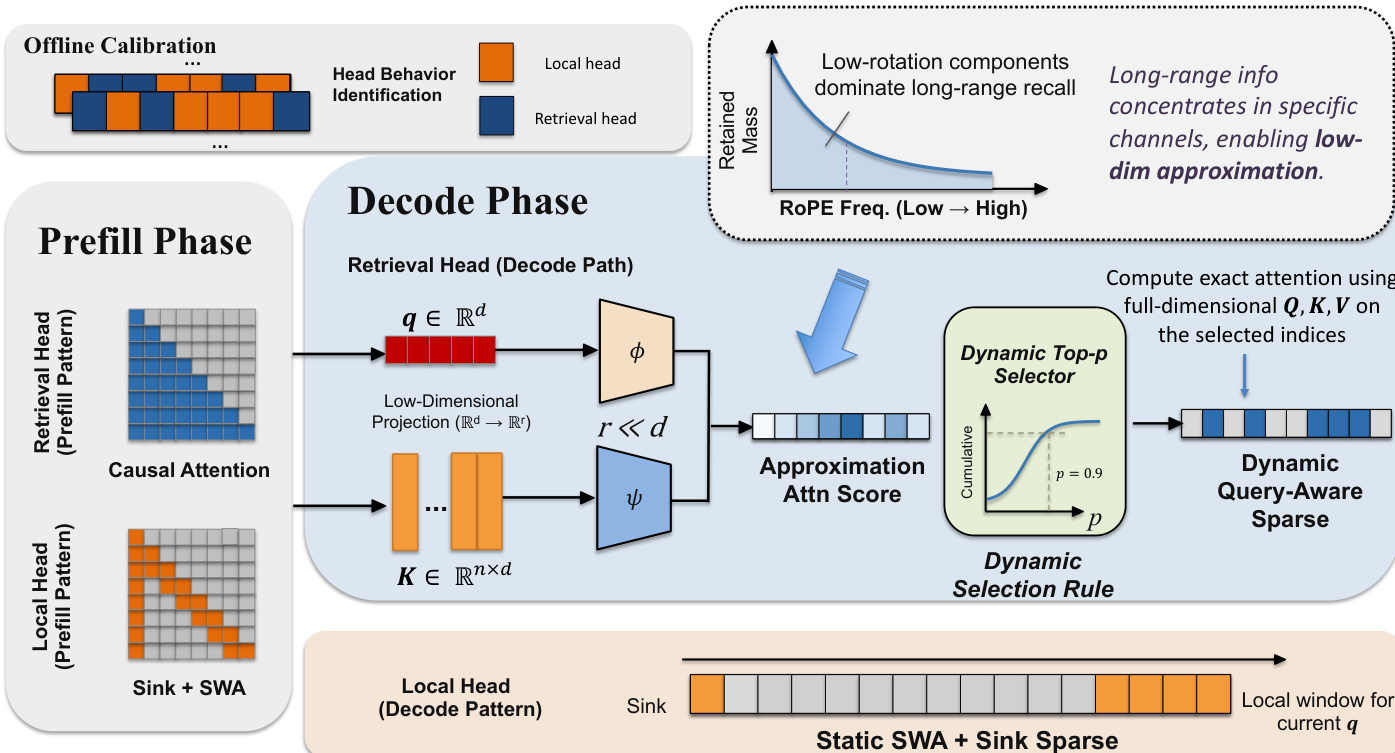
最后,实现了一种硬件感知的 decode kernel 以优化稀疏计算。该 kernel 解决了两个关键挑战:快速的 top-p 阈值筛选与内存高效的解码。第一个 kernel(Kernel 1)并行计算注意力得分,使用直方图无需昂贵排序即可筛选 top-p token,并将打分与选择融合为单次 kernel 启动。第二个 kernel(Kernel 2)负责实际的稀疏注意力计算。其设计通过采用无共享内存的 single-warp CTA 实现带宽优化,将所有状态保留在寄存器中以最大化并发内存请求。内层循环采用 2-token 展开,并使用向量化 half2 指令加载 K 和 V 数据,使得分计算与 online-softmax 更新能够与进行中的内存加载重叠。该架构在插图中展示,呈现了稀疏 decode 过程的并行与顺序阶段。
实验
在标准 GPU 基础设施上,结合统一的准确率评估框架与专用效率分析工具,该实验设置建立了评估架构设计与计算性能的基础基准。稀疏性与准确率实验验证了检索头的激活本质上依赖于查询,证明动态阈值筛选能有效平衡高注意力召回率与计算效率。同时,运行时基准测试验证了该自适应机制在超长上下文场景下持续加速推理,且不损害模型可靠性。
作者分析了检索头稀疏性的查询依赖特征,表明保留的最优 token 数量在不同输入间存在显著差异。结果表明,动态阈值筛选方法在实现高度稀疏的同时保持较高的注意力质量,在不同上下文长度下均优于固定预算方法。检索头的稀疏性高度依赖查询,不同输入需要差异极大的 token 数量来维持注意力质量。动态阈值筛选实现了高稀疏性并维持注意力质量,避免了固定预算方法可能导致的检索不足或计算浪费。最优 token 预算因查询类型而异,部分查询需要比其他查询多得多的 token 才能保留有效注意力。
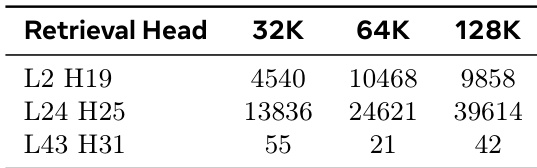
作者跨多个基准测试评估了动态稀疏方法 RTPURBO,并与固定 top-k 方法及全注意力机制进行对比。结果显示,RTPURBO 在保持显著更高稀疏性的同时,取得了具有竞争力或更优的准确率,尤其在长上下文场景中表现突出。该方法能够适应查询复杂度,在不受固定预算限制的情况下高效保留注意力质量。RTPURBO 相比固定 top-k 方法实现了更高的稀疏性,同时在各项基准测试中保持具有竞争力的准确率。该方法适应查询复杂度,动态调整活跃 token 数量以维持注意力质量。RTPURBO 在超长上下文长度下维持高准确率与高稀疏性,在效率与召回率方面超越基线方法。
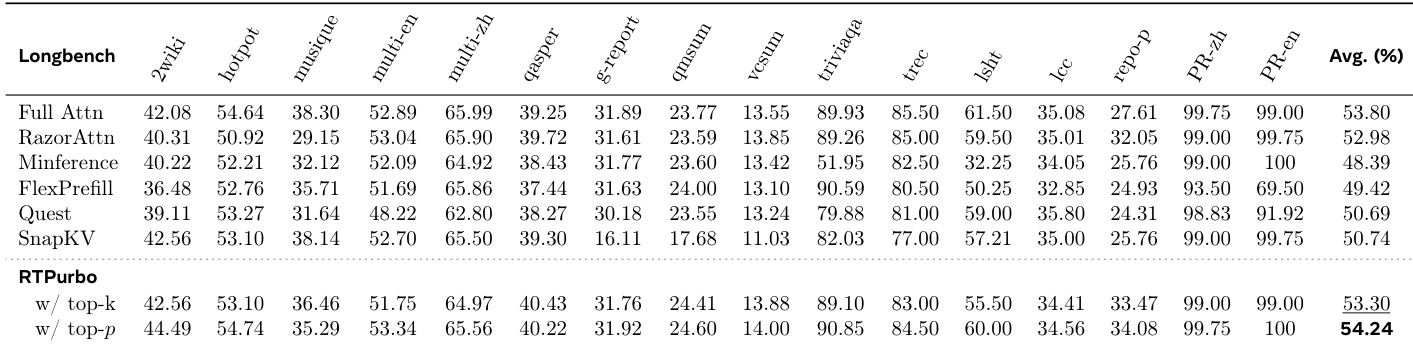
作者评估了不同维度设置在各类基准测试上的性能,表明较高维度通常能在各项任务中维持或提升准确率。结果表明,维度选择对性能的影响因基准测试而异,部分任务从维度增加中获益更多。与较低维度相比,较高维度在大多数基准测试中倾向于维持或提升准确率。性能在不同基准测试间差异显著,部分测试在不同维度设置下结果一致,而其他测试则表现出更大波动。维度的影响具有任务依赖性,某些基准测试在较高维度下显示出显著改进。
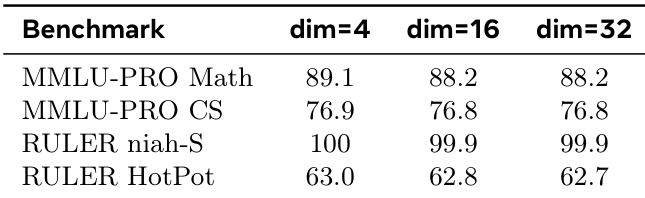
作者跨多个基准测试评估了其方法 RTPurbo 的性能,与基线方法对比显示,该方法在维持高稀疏性的同时取得了具有竞争力或更优的准确率。结果表明,检索头的动态阈值筛选实现了高效的注意力计算,且未造成显著的准确率损失,尤其在长上下文场景中。在多项推理任务中,RTPurbo 相比基线方法取得了具有竞争力的准确率,并在部分基准测试中实现提升。该方法在维持注意力质量的同时保持高稀疏性,使长上下文设置下的计算更为高效。检索头的动态阈值筛选支持查询依赖的稀疏化,优于 top-k 等固定预算方法。

作者跨不同上下文长度评估了其方法 RTPurbo 的效率,与基线方法进行对比。结果显示,RTPurbo 在 prefill 与 decode 阶段均较 FlashAttention-2 实现了显著加速,且随着上下文长度增加,性能进一步提升。该方法在实现高度稀疏的同时保持高准确率,尤其在超长上下文场景中。RTPurbo 在所有上下文长度下,于 prefill 与 decode 阶段均实现了高于 FlashAttention-2 的加速比。RTPurbo 在维持高准确率的同时实现高稀疏性,在较长上下文长度下尤为明显。RTPurbo 的加速比随上下文长度增加而提升,展现出相比基线方法更优的可扩展性。
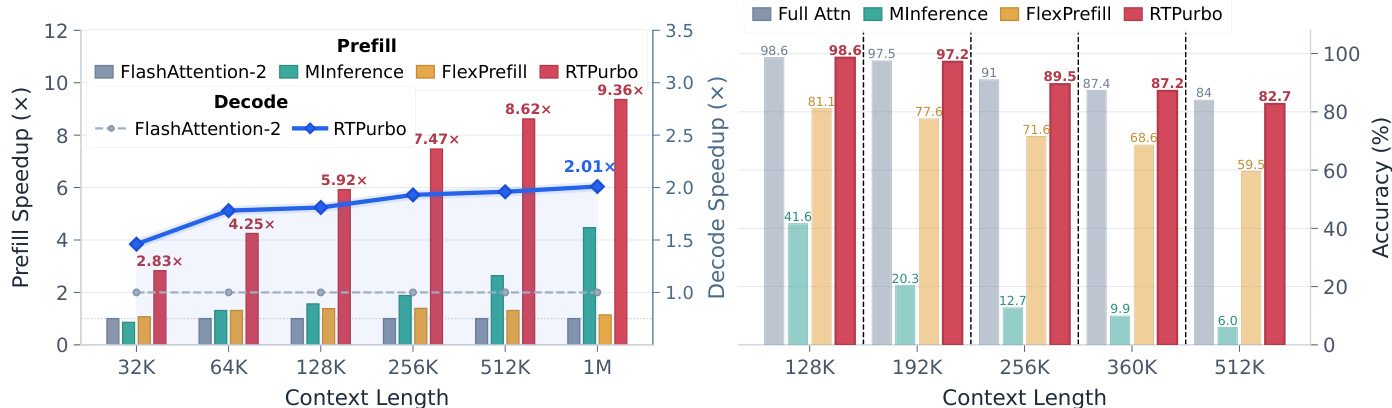
实验跨多个基准测试、不同上下文长度及维度设置,评估了针对检索头的动态稀疏框架,以验证其适应性与计算效率。结果表明,查询依赖的阈值筛选持续保留注意力质量并维持具有竞争力的准确率,同时实现了远高于固定预算或全注意力基线的稀疏性。该方法随上下文延长有效扩展,在无需性能损耗的情况下提供显著加速。总体而言,研究结果证实,基于输入复杂度动态分配 token 为静态选择策略提供了一种稳健且高效的替代方案。