Command Palette
Search for a command to run...
一键部署 MedGemma-4b-it 多模态医疗 AI 模型
摘要
一句话总结
MIRAGE 是一个多模态检索与生成系统,它利用经过微调的 MedICaT-ROCO 模型、Prompt2MedImage 扩散网络以及 Dolly-v2-3b 语言模型,将医学文本和图像映射到共享的潜在空间中,以检索和合成具有临床价值的视觉内容。该系统为医学生提供了一个免费的、托管于 Kaggle 上的教育平台,且完全依赖公开可用的预训练模型。
核心贡献
- 本文提出了 MIRAGE,一个统一的多模态系统,集成了医学图像检索、合成图像生成以及基于潜在空间算术的概念级比较。通过将文本和视觉输入映射到共享的嵌入空间,该架构支持语义对齐的查询,并支持双路搜索功能以可视化临床差异。
- 该处理流程完全依赖公开可用的预训练模型,包括经过微调的 MedICaT-ROCO 视觉语言编码器、Prompt2MedImage 扩散生成器以及 Dolly-v2-3b 大语言模型。该透明技术栈在 ROCO 数据集上进行训练,无需专用计算基础设施即可保证完全的可复现性。
- 该平台已部署于 Kaggle,并通过定量与定性分析进行了验证,确认了其在真实教育场景中的语义一致性。该易用的界面为非编程背景的医学生提供了交互式医学训练环境。
引言
医学教育从根本上依赖于对高质量、带注释的视觉数据进行交互式访问,以训练诊断技能和解剖学理解。尽管传统图谱具备临床可靠性,但其操作繁琐且内容静态,而通用网络搜索常常产生未经核实或标注不佳的内容。现有的 AI 驱动教育工具主要侧重于文本,未能将可靠的图像检索、合成生成和经过验证的临床依据整合到单一工作流中。为弥补这一差距,研究团队利用经过微调的医学视觉语言模型、领域特定的扩散生成器以及大语言模型构建了 MIRAGE。这是一个统一平台,能够检索相关医学图像、生成合成视觉内容,并根据用户提示生成丰富的临床描述。该系统还通过潜在空间操作支持比较分析,并完全在公开可用的预训练模型上运行,确保完全的可复现性,便于缺乏技术背景的医学生进行部署。
数据集
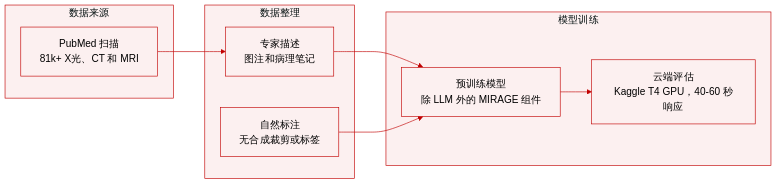
- 数据集构成与来源: 研究团队使用 ROCO 数据集,这是一个大规模的多模态医学影像集合,包含从 PubMed Central 开放获取子集中提取的超过 81,000 张图像。
- 子集详情: 该集合涵盖多种成像模态,如 X 射线、CT 和 MRI。每张图像均与专家撰写的说明文本配对,这些文本通常源自图片图注或文章内容,主要标识成像类型及具体病理特征。
- 数据用途: MIRAGE 的所有组件(底层大语言模型除外)均在该数据集上进行预训练,以支持多模态研究与交互式医学查询处理。
- 处理与元数据: 该数据集依赖自然生成的临床注释,而非合成元数据或裁剪策略。说明文本作为主要的文本依据,在保留诊断上下文的同时,支持可复现的训练与云端推理。
方法
研究团队利用以共享潜在空间为核心的多模态框架,实现医学图像与描述的语义检索与生成。MIRAGE 系统通过三个主要模块运行:系统编码器、查询处理以及合成图像生成。整体架构旨在支持医学影像领域的教育用例,使用户能够检索相关图像、获取丰富的文本描述,并根据用户查询生成合成图像。
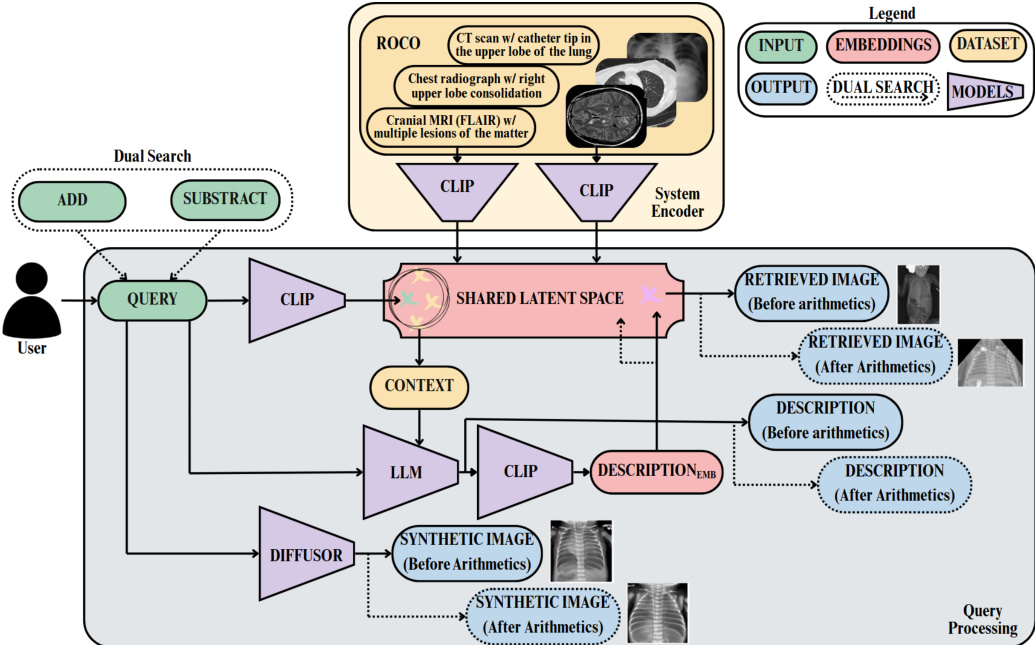
请参阅框架图以了解端到端的工作流程。系统以 ROCO 数据集为起点,该数据集作为医学图像及其对应说明文本的参考图谱。图像与说明文本均通过一个针对医学内容微调的基于 CLIP 的模型(CLIP-ViT-L-14-448px-MedICaT-ROCO)嵌入到共享的潜在空间中。该模型采用独立的文本和视觉编码器生成归一化嵌入向量,从而实现文本查询与图像表示之间的直接语义比较。这些嵌入向量经过预计算并存储,以支持高效的余弦相似度检索。
如下图所示,查询处理模块接收描述医学概念或病症的用户输入。查询内容使用相同的 CLIP 模型编码为嵌入向量,随后在共享潜在空间中与预计算的图像嵌入向量进行比较。系统检索出最相似的 top-k 张图像,并将其对应的说明文本作为上下文输入给通用指令遵循语言模型 Dolly-v2-3b。该模型生成丰富的说明文本,提供关于查询概念的更详细且上下文相关的描述。随后,该丰富说明文本通过 CLIP 重新编码,并在第二次检索步骤中与图像嵌入向量进行比较,以返回语义最匹配的图像及相应的丰富描述。
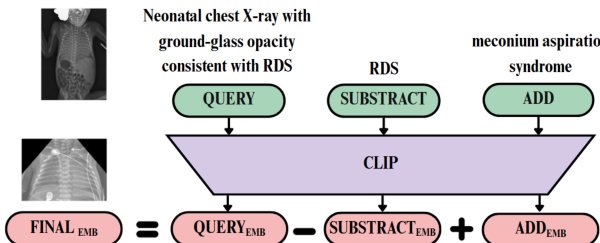
该系统进一步支持双路搜索模块,旨在促进两个相关医学概念的比较。该功能允许用户通过执行潜在空间算术操作,探索临床不同病症之间的差异。当用户指定基础查询及两个术语(一个用于减去,一个用于加上)时,系统将所有文本输入嵌入共享语义空间。修改后的查询嵌入向量按照公式 1 的定义,计算为原始查询嵌入向量与减去项嵌入向量的差值,加上加上项嵌入向量的结果。该变换使语义表示向新概念偏移。原始与修改后的嵌入向量均用于检索各自最相似的 top-1 图像,从而实现并排视觉对比。
除检索功能外,系统还使用基于扩散的模型 Prompt2MedImage 生成合成医学图像。该模型在医学内容上进行训练,支持 MRI、CT 和 X 射线等多种模态。图像生成过程直接使用原始用户提示,因为更长的描述并不会提升合成输出的质量。合成图像生成流程已集成至整体管线中,使用户能够对比真实图像与合成图像,从而增强概念理解与解读能力。整个管线设计充分考虑了人机协作,通过交互式探索以及上下文相关的视觉与文本反馈,鼓励主动学习。
实验
该评估结合了定量嵌入分析以验证文本与多模态配对间的语义对齐情况,并辅以定性视觉检查以评估医学语境下的检索准确率与生成保真度。实验结果表明,潜在空间可靠地保留了临床关系,确保语义相关的输入能够与无关输入保持一致的区分度。定性评估进一步证实,系统检索到的真实图像与用户查询高度契合,生成的合成视觉内容能够准确捕捉指定的解剖与病理特征。此外,潜在空间操作成功引发了可预测的语义与视觉变化,凸显了该模型在交互式医学教育与概念探索中的实用价值。
研究团队通过分析不同输入类型(包括文本-文本、真实图像-说明文本、合成图像-说明文本配对)的余弦相似度得分与分类准确率,评估了多模态系统的语义一致性。结果显示,语义相似的输入始终比不相似的输入获得更高的相似度得分,且所有配置下的分类准确率均较高。该系统在文本与视觉表示之间展现出强对齐性,尤其在真实图像-说明文本配对中表现突出,而合成图像-说明文本配对也显示出显著但相对较低的相似度。研究团队进一步通过定性示例展示了系统能力,突出了其检索相关图像及生成捕捉关键医学特征合成图像的能力,并能在查询修改时产生相应的视觉与语义变化。与合成图像-说明文本配对相比,文本-文本和真实图像-说明文本配对表现出更高的相似度得分与分类准确率。该系统在所有评估类型中均能实现高分类准确率,有效区分相似与不相似配对。定性结果表明,系统能够生成反映关键医学特征的合成图像,并针对查询修改做出适当的视觉与语义响应。

该评估通过在文本-文本、真实图像-说明文本及合成图像-说明文本配对上测试系统,来检验语义一致性,以验证表示对齐与分类可靠性。结果表明,模型能够一致地区分相似与不相似的输入,且真实配对表现出比合成替代方案更强的图文一致性。定性评估进一步展示了系统检索相关医学图像及生成准确合成视觉内容的能力,这些合成内容能够针对查询修改做出适当调整。总体而言,该框架成功保持了语义完整性,并在所有评估配置下提供了上下文适配的多模态输出。