Command Palette
Search for a command to run...
Token 分类
摘要
一句话总结
针对传统 next-token prediction 中均匀加权的假设,本研究引入了一种新颖的 token-weighting 方案。该方案采用两步框架对 token 进行评分,通过比较长上下文模型与短上下文模型的置信度来分配非均匀损失权重。在多项长上下文理解任务上的评估表明,非均匀损失权重能够提升大语言模型的长上下文能力。
核心贡献
- 本文提出一种两步 token-weighting 框架,以动态评分取代均匀损失加权。该评分基于长上下文模型与短上下文模型预测置信度的比较。该流程对评分方法进行分类,并采用密集或稀疏后处理来调整训练侧重点。
- 研究系统评估了密集与稀疏权重后处理,并证明冻结的预训练短上下文模型可作为高效、轻量级的评分器。该机制显式提升反映长距离依赖的 token 权重,同时降低琐碎或固有难以预测的 token 权重。
- 在多项长上下文理解任务上的评估表明,非均匀损失权重始终优于标准训练基线,提升模型性能。这些实证发现为损失加权策略提供了实用指导,并阐明了长上下文语言建模中固有的权衡关系。
引言
大语言模型日益部署于需要长上下文理解的应用中,但始终难以有效利用扩展的输入序列。尽管以往研究主要优化训练数据与架构效率,但训练准则本身却鲜受关注。标准的 next-token prediction 为每个 token 分配同等重要性,未能考虑不同序列间变化的上下文需求,且掩盖了长距离依赖。作者利用一种新颖的 token-weighting 框架,通过比较短上下文与长上下文模型的预测置信度来动态调整损失贡献。通过系统评估密集与稀疏加权方案,作者证明优先处理具有真实长距离依赖的 token 可在不改变底层架构的情况下显著提升模型性能。
数据集
-
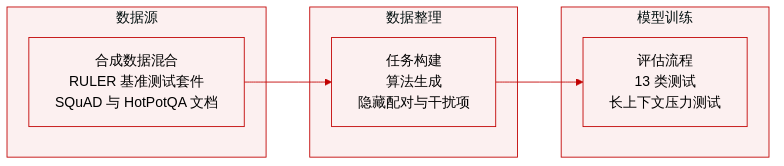
数据集构成与来源: 作者采用 RULER 基准,这是一个由合成数据生成的评估套件,包含 6,500 个示例,分布在 13 个类别中。这些类别涵盖四大核心长上下文能力领域:检索、多跳追踪、聚合与问答。
-
各子集关键细节:
- 检索任务包含五种变体,围绕干扰文本中隐藏的键值对构建。作者控制的参数包括键值对数量(m)、键与值格式(单词、数字或 UUID)、背景文本构成(文章、重复句子或空文本)以及查询数量。
- 多跳追踪采用变量跟踪设置,通过五次链式赋值模拟指代消解。
- 聚合任务生成合成词表,要求模型提取出现三十次的十个单词,或通过 Zeta 分布采样提取出现频率最高的三个单词。
- 问答子集从 SQuAD 获取单跳查询文档,从 HotPotQA 获取多跳场景文档,将一个目标文档作为“针”置于随机采样的干扰项中。
-
数据使用与处理: 每个类别恰好包含 500 个示例,作者仅将其用于评估而非模型训练。提供的节选未详细说明训练集划分或混合比例,因为该数据集作为标准化基准用于压力测试长上下文保持能力。提示词模板与生成逻辑改编自原始 RULER 论文。
-
额外处理细节: 作者完全依赖具有明确超参数的算法构建,以保证可重复性与可控的噪声水平。未应用任何手动裁剪或元数据过滤,因为合成框架本身已管理干扰密度、任务复杂度与答案格式。
方法
作者利用一种两步框架来确定大语言模型(LLM)训练目标中的非均匀 token 权重,旨在提升长上下文理解能力。该框架包含两个关键阶段:token 评分与后处理。整体方法通过允许灵活且连续的 token 加权,而非局限于稀疏二值或基于分位数的方案,对以往工作进行了泛化。该方法基于以下假设:基础模型 θ0 已在长度有界的序列 n 上完成预训练,目标模型 θ 随后被扩展以处理长度 N≫n 的更长序列,通常通过位置插值或 RoPE 基础缩放等技术实现。其目标是在扩展上下文数据的训练过程中增强模型捕捉长距离依赖的能力。

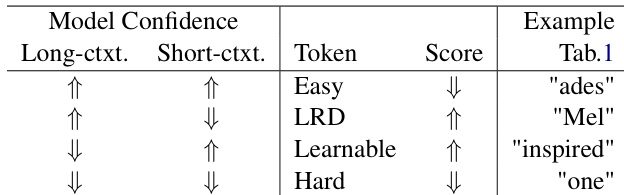
如图下方所示,token 评分方法旨在识别两类 token:一类在短上下文建模下难以预测但在长上下文建模下可预测(表明存在长距离依赖);另一类已被长上下文模型良好预测,但在短上下文模型下仍不确定(表明内容可学习但尚未掌握)。评分函数定义为短上下文模型 θ′ 与长上下文模型 θ 之间对数概率差值的绝对值:
∣w~i∣=log(pθ(N)(i)pθ′(n)(i))=log(pθ′(n)(i))−log(pθ(N)(i)).此处上标表示用于预测的过去 token 数量,θ′ 在长度 n 的上下文中运行,θ 在长度 N 的上下文中运行。该公式确保表现出长距离依赖的 token(例如短上下文模型不确定而长上下文模型自信的 token)获得高分。相反,固有难以预测的 token(例如因歧义或变化导致)或琐碎的 token(例如高频或可预测的)获得低权重。绝对值确保评分保持为正,并避免长上下文模型置信度低于短上下文模型时可能出现的负值,从而不违背在扩展上下文时强调长距离依赖的目标。
作者指出,该评分函数对应于当前 token 与远距离上下文之间的负条件逐点互信息(CPMI),使其成为衡量长距离影响的自然指标。该特性符合强调远距离上下文提供显著预测信息的 token 的预期行为。尽管存在其他评分方法,但所选方案因其简洁性与理论依据而更受青睐。
短上下文模型 θ′ 的选择是一项关键设计决策。一种方案是将预训练模型 θ0 用作短上下文模型并冻结其参数。该方法与 ρ 中使用的方案类似,但需要对整个数据集进行预评分或在训练期间维护两个模型,从而增加内存消耗。另一种方案是作者考虑使用较小模型作为短上下文模型,该模型可在弱到强泛化设置中充当“教师”。这允许更高效地评分,尤其是在可用多个同架构模型时。第三种方案是使用长上下文模型 θ 本身,但在评分时人工限制其上下文,从而共享权重并降低内存开销。作者通过实验探讨了这些选择并讨论了其权衡关系。
在后处理阶段,作者摒弃了 ρ 中基于分位数将权重设为零或 1/κ 的稀疏加权方案。相反,他们采用密集加权方法,直接使用归一化后的评分 ∣w~i∣。为确保与标准训练流程兼容,评分被归一化使其总和等于序列长度 N:
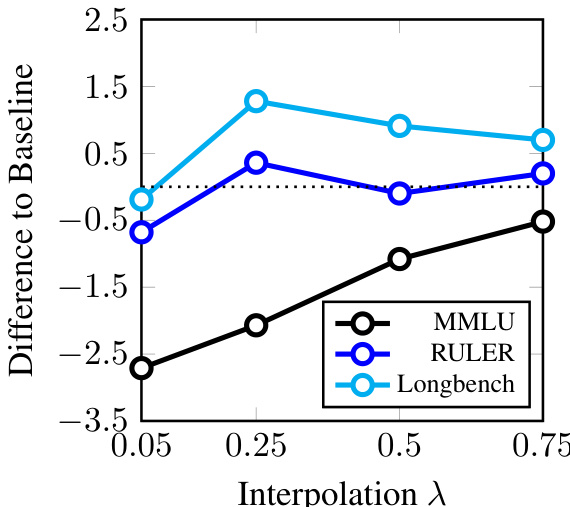
norm(∣w~i∣)=N⋅∑i=1N∣w~i∣∣w~i∣.该归一化确保有效损失与均匀加权保持可比性,从而允许使用标准学习率。为进一步控制偏离均匀程度的范围,作者使用超参数 λ∈[0,1] 在归一化评分与均匀权重之间进行插值:
wi=λ+(1−λ)⋅norm(∣w~i∣).该插值作用类似温度参数:当 λ=1 时,权重均匀;当 λ=0 时,权重完全由评分函数决定。这实现了短上下文性能与长上下文能力之间的平滑权衡,使模型能够针对不同上下文精细调整侧重点。作者强调,该密集加权方案避免了稀疏化带来的信号丢失,且与标准自回归训练兼容,尽管受限于 Transformer 解码器的特性,反向传播速度并未提升。
实验
实验评估了使用各种 token 加权方案将 Llama-3 8B 和 Phi-2 2.7B 的上下文窗口扩展至 32k token 的效果,在 RULER 和 Longbench 上评估长上下文能力,同时在 MMLU 和 BBH 上监控短上下文保持情况。结果表明,非均匀 token 权重始终优于均匀基线。稀疏加权有效将学习集中在长距离依赖上,从而提升以检索为主的任务性能,但牺牲了短上下文性能。相反,密集加权在长上下文与短上下文中保持了更均衡的泛化能力。此外,在处理显著的上下文长度不匹配时,冻结的评分模型通常比未冻结模型更具鲁棒性。最终,研究证实战略性 token 加权成功扩展了模型上下文窗口,但实践者必须在专业长距离检索与广泛短上下文保持之间应对明确的权衡。
作者比较了扩展语言模型上下文的不同 token 加权方法,评估其在长上下文任务与短上下文基准上的表现。结果显示,稀疏未冻结加权在提升长上下文能力的同时牺牲了部分短上下文性能,而采用密集加权的冻结模型在两者间保持了平衡。整体最佳性能由稀疏冻结模型取得,该类模型结合了长上下文侧重点与更优的短上下文保持能力。稀疏未冻结加权增强了长上下文性能但降低了短上下文能力。密集加权的冻结模型实现了长、短上下文性能的更好平衡。稀疏冻结模型通过结合长上下文侧重点与保留的短上下文能力,取得了最高的整体性能。
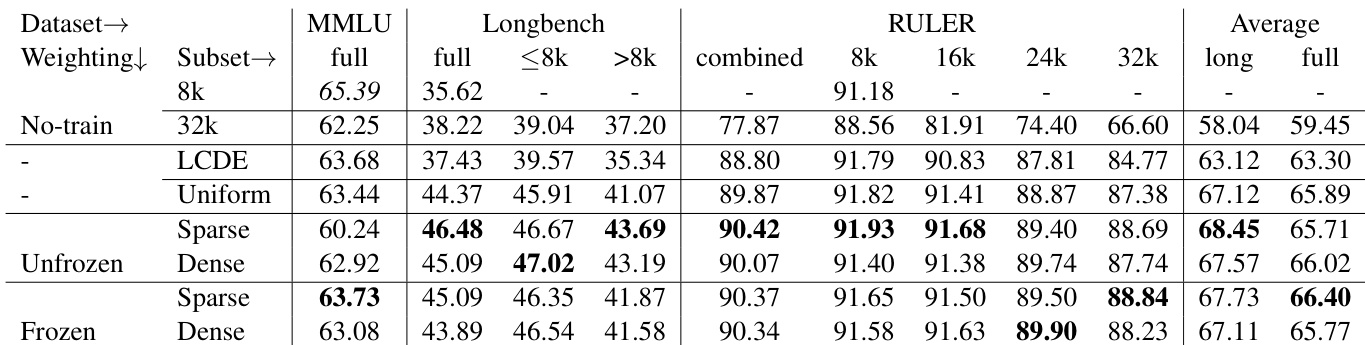
作者比较了扩展语言模型上下文的不同 token 加权方法,重点关注长上下文性能与短上下文能力的保持。结果表明,非均匀加权提升了长上下文理解能力,稀疏未冻结模型在以检索为主的任务中表现优异,但以牺牲短上下文性能为代价,而冻结模型在长、短上下文间维持了更好的平衡。加权方案的选择显著影响各基准上的表现,密集方法保留泛化能力,稀疏方法则专注于关键信息。稀疏未冻结模型实现了最佳的长上下文性能,但因忽略早期 token 而在短上下文任务中表现不佳。冻结模型(尤其是稀疏冻结)在长上下文能力与短上下文保持之间维持了更好的权衡。密集加权方法保留泛化能力,在长、短上下文评估中表现更为一致。
作者探讨了 token 加权方法对扩展语言模型上下文长度的影响,比较了密集与稀疏加权方案以及冻结与未冻结评分模型。结果显示,稀疏未冻结加权提升了长上下文性能,但以牺牲短上下文能力为代价,而采用稀疏加权的冻结模型在长、短上下文性能间取得了更好的平衡。评分模型与加权策略的选择显著影响下游任务表现,尤其在以检索为主和合成任务中。稀疏未冻结加权增强了长上下文性能但降低了短上下文能力。稀疏加权的冻结模型在长、短上下文性能间实现了更好的权衡。加权方法的有效性因任务而异,稀疏未冻结方案在以检索为主和合成任务中表现突出。
作者比较了扩展语言模型上下文长度的不同 token 加权方法,重点关注不同上下文长度与任务下的表现。结果表明,稀疏未冻结模型在长上下文任务中表现最佳,尤其适用于以检索为主的场景,而密集模型保持了更好的短上下文性能。评分模型的选择(冻结或未冻结)对整体性能影响显著,冻结模型在长上下文任务中通常优于未冻结模型。稀疏未冻结模型在长上下文任务(尤其是检索主导场景)中表现出色,但短上下文性能较弱。密集模型在短、长上下文中维持了更均衡的表现,比稀疏模型更好地保留了短上下文能力。冻结模型在长上下文任务中优于未冻结模型,评分器的选择对整体结果具有重大影响。
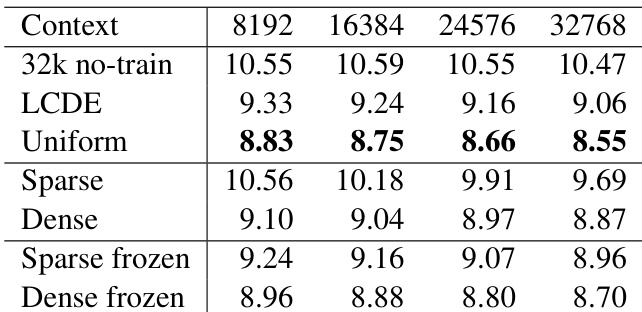
作者比较了扩展语言模型上下文长度的不同 token 加权方法,重点关注其对长上下文性能与短上下文能力保持的影响。结果显示,稀疏未冻结加权提升了长上下文性能,尤其在以检索为主的任务中,但以牺牲短上下文性能为代价,而密集方法维持了更好的整体平衡。评分模型的选择(冻结或未冻结)同样影响性能,冻结模型在稀疏设置中通常表现更佳。稀疏未冻结加权提升了长上下文性能但损害了短上下文能力。密集加权方法保持了更好的整体性能并保留了短上下文能力。冻结评分模型在稀疏设置中优于未冻结模型,而未冻结模型能够从初始长上下文性能不佳中恢复。
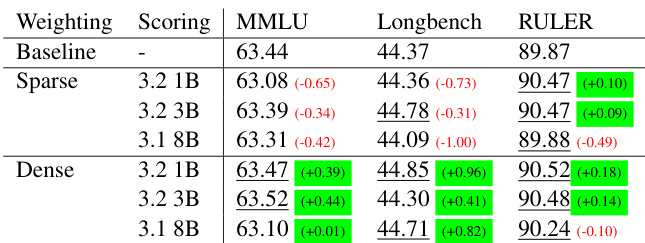
实验评估了不同的 token 加权策略,通过比较密集与稀疏方案以及冻结与未冻结评分模型,评估其对扩展语言模型上下文长度的影响。每项验证均聚焦于提升长上下文能力(尤其以检索为主的任务)与保留短上下文泛化之间的关键权衡。定性来看,稀疏未冻结加权最大化了长上下文性能但降低了短上下文保持率,而密集方法在两个领域间维持了更一致的平衡。最终,稀疏冻结模型通过有效优先长上下文侧重点并保留短上下文能力,交付了最强的整体结果。