Command Palette
Search for a command to run...
GLM-4-Voice:迈向智能且拟人的端到端语音聊天机器人
GLM-4-Voice:迈向智能且拟人的端到端语音聊天机器人
Aohan Zeng Zhengxiao Du Mingdao Liu Kedong Wang Shengmin Jiang Lei Zhao Yuxiao Dong Jie Tang
一键部署 GLM-4-Voice:端到端中英语音对话模型
摘要
我们介绍了 GLM-4-Voice,这是一种智能且拟人的端到端语音聊天机器人。它支持中文和英文,能够进行实时语音对话,并根据用户指令调整情感、语调、语速和方言等语音细微差别。GLM-4-Voice 采用了一种超低比特率(175bps)、单码本语音分词器,帧率为 12.5Hz,该分词器源自自动语音识别(ASR)模型,通过在编码器中引入向量量化瓶颈实现。为了高效地将知识从文本模态迁移到语音模态,我们使用文本到标记(text-to-token)模型,从现有的文本预训练语料库中合成语音-文本交错数据。我们以预训练的文本语言模型 GLM-4-9B 为基础,结合无监督语音数据、交错语音-文本数据和监督式语音-文本数据进行继续预训练,规模扩展至 1 万亿个 token,在语音语言建模和语音问答方面均取得了最先进的性能。随后,我们使用高质量的对话语音数据对预训练模型进行微调,在对话能力和语音质量方面均优于现有基线模型。开源模型可通过 https://github.com/THUDM/GLM-4-Voice 和 https://huggingface.co/THUDM/glm-4-voice-9b 访问。
一句话总结
GLM-4-Voice 是一款智能且拟人化的端到端语音聊天机器人。该模型采用 175 bps 单码本语音标记器,并在合成语音-文本交错数据上进行一万亿 token 的预训练,从而实现支持动态语音细微变化的实时中英对话。其在语音语言建模与语音问答方面达到最先进水平,后续微调进一步使其对话能力与语音质量优于现有基线模型。
核心贡献
- GLM-4-Voice 是一款端到端语音聊天机器人,支持实时语音对话,并支持对情感、语调及方言进行动态控制。其架构采用一种源自自动语音识别(ASR)编码器且带有向量量化瓶颈的新型超低比特率(175bps)单码本语音标记器,以实现 12.5Hz 的帧级表示。
- 为实现文本与语音模态的对齐,该框架基于现有文本预训练数据集合成语音-文本交错语料,并从 GLM-4-9B 语言模型继续执行预训练。该跨模态训练扩展至一万亿 token 的混合无监督、交错及监督数据,在语音语言建模与自动语音识别方面奠定了坚实的基线能力。
- 该模型经过对话微调,采用在文本与 token 之间交替的流式思维模板,以实现低延迟对话生成。广泛评估表明,该模型在语音问答方面达到最先进水平,且在语音质量与对话流畅度上优于现有基线模型。
引言
基于语音的交互为人机通信提供了更自然、更具表现力的媒介,但传统语音聊天机器人依赖割裂的 ASR、语言模型与文本转语音(TTS)流水线,导致高延迟、误差累积以及情感细微变化有限。端到端语音语言模型提供了有前景的替代方案,但受限于相对于文本语料库的语音数据严重匮乏,且通常缺乏专用的语音预训练,这限制了其生成流畅、拟人化韵律和动态语音风格的能力。作者采用了一种运行于 12.5Hz 的单码本监督语音标记器来高效离散化音频流,并通过在一万亿 token 的交错与无监督语音-文本数据上进行大规模预训练,有效弥合了文本与语音模态之间的差距。他们进一步利用在文本与 token 之间交替的流式思维模板对模型进行微调,以提升对话流畅度。该方法实现了实时低延迟的语音交互,能够动态调整情感、语调与语速,同时在语音建模、问答与合成任务中达到最先进水平。
数据集
- 作者将数据集划分为两个训练阶段,以开发具备语音能力的语言模型与语音对话 Agent。
- 阶段 1:联合预训练
- 基于现有文本语料库合成的语音-文本交错对,用于实现跨模态对齐
- 约 700k 小时无监督的真实世界语音数据,用于通用声学学习
- 覆盖自动语音识别与文本转语音任务的监督语音-文本对
- 混合标准文本预训练数据集,以保留原生语言能力
- 阶段 2:语音聊天机器人微调
- 源自文本源的多轮对话语料,经过严格过滤以排除代码与数学内容。团队精简冗长回复,剔除口语不自然的表达,合成匹配音频,并补充人工录制输入以提升真实世界多样性
- 风格控制的多轮对话,专门用于建模语速、情感基调与地域方言的变化
- 数据处理与使用
- 初始预训练阶段将语音子集与文本语料库以未指明的比例混合,以联合优化语音与语言建模
- 所有对话数据在部署用于聊天机器人训练前,均经过质量过滤、长度缩减以及音频合成或人工录制
- 完整的数据集统计与混合比例详见原始论文
方法
作者对自回归 Transformer 架构进行最小化修改,设计了 GLM-4-Voice。该模型旨在打造一款拟人化的端到端语音聊天机器人,兼具语音理解与生成富有表现力的语音回复的能力。核心架构为输入与输出集成统一的语音表示,支持在语音数据上进行下一个 token 预测,并便于在大规模无监督语音语料库上进行高效预训练。该设计在保留模型文本处理能力的同时,通过单码本语音标记化方法实现有效的语音建模,避免了多层语音 token 生成的复杂性。

语音标记化过程将连续的音频波形转换为离散的语音 token,这些 token 保留了语义信息及部分声学细节。模型采用监督式语音标记器,具体为 Zeng 等人描述的 12.5Hz 变体,该标记器由预训练的自动语音识别模型(如 whisper-large-v3)微调而来。该标记器架构在编码器内部包含前馈网络与池化层,随后是向量量化层,其码本向量通过指数移动平均法学习。为确保低延迟交互,Whisper 编码器通过将其卷积层替换为因果卷积,并将双向注意力替换为块因果注意力,从而适配因果性,实现输入语音的流式编码。该标记器在多样化的 ASR 数据集与带有伪标签的无监督语音数据上进行微调,监督样本与伪标签样本的比例为 1:3,所选的 12.5Hz 变体因在质量与比特率之间达到最佳平衡而被采用。
语音解码器从离散语音 token 合成高质量语音波形,并专为低延迟流式推理设计。该解码器采用 CosyVoice 架构,包含语音 token 编码器、条件流匹配模型与 HiFi-GAN 声码器。解码器采用两阶段范式进行训练:首先在来自不同说话人的多样化低质量语音数据上进行预训练,随后在高质量单说话人数据上进行微调。为支持流式推理,模型在微调过程中以块为单位处理截断的音频样本,使其能够以预定义块大小的最小延迟生成语音 token,GLM-4-Voice 的块大小设定为 0.8 秒。这使得解码器能够处理对应于前 n⋅b 秒音频的语音 token,并以前 (n−1)b 秒作为提示来预测下一片段。
推理过程将语音到语音任务解耦为两个子任务:语音转文本与语音及文本转语音。给定用户语音输入 Qs,模型首先生成文本回复 At,随后结合 Qs 与 At 生成语音输出 As,以确保对话连贯性。为降低延迟,模型采用“流式思维”模板,按指定比例交替生成文本与语音 token。基于 12.5Hz 标记器,模型在生成 13 个文本 token 与 26 个语音 token 之间交替,确保文本生成速度快于语音生成,从而维持上下文连贯性。
整体响应延迟由四个顺序阶段组成:语音标记化、LLM 预填充、LLM 解码与语音解码。语音标记化延迟取决于输入音频的块大小。LLM 预填充延迟由生成的语音 token 数量决定,该数量基于用户语音时长与帧率。初始音频回复的 LLM 解码延迟根据首个语音块生成的 token 数量计算。最后,语音解码延迟由语音解码器处理的音频 token 数量决定。总响应延迟为这四个阶段之和。
实验
评估框架验证了基础模型在语音到语音与语音到文本设置下,进行语音-文本交错处理及事实性语音问答的能力。结果表明,该模型在语音问答中持续优于基线模型,并显著缩小了模态间的性能差距,表明尽管文本引导仍更具准确性,但直接语音到语音的聊天机器人具有高度可行性。微调后的聊天实验进一步验证了回复正确性、语音自然度与跨模态一致性,确认该系统已具备用于交互式对话应用的准备条件。
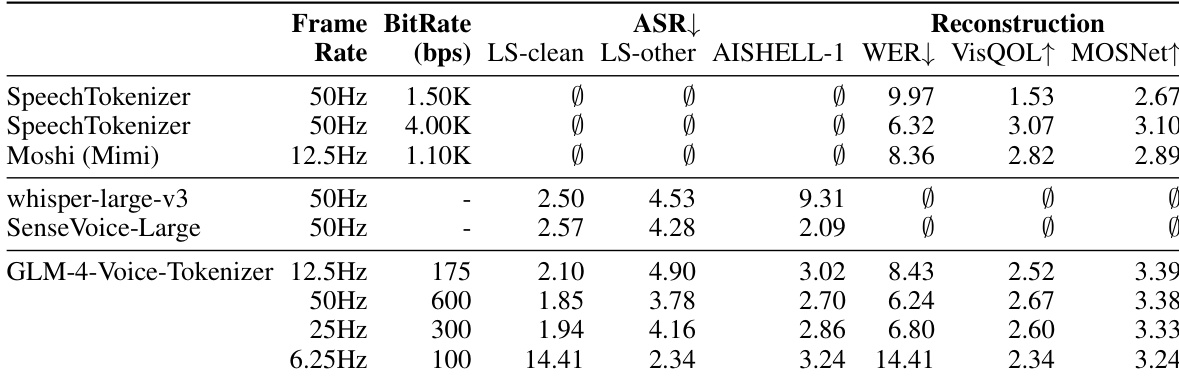
作者使用英文与中文的标准基准测试评估了 GLM-4-Voice 的 ASR 与 TTS 能力。结果表明,与既定基线相比,GLM-4-Voice 在 ASR 与 TTS 任务中均取得具有竞争力的性能,不同数据集与模态间的错误率存在显著差异。该模型在英文与中文的 TTS 任务中表现强劲,而 ASR 性能则因数据集与语言而异。与既定基线相比,GLM-4-Voice 在 ASR 与 TTS 方面均展现出具有竞争力的性能。该模型在英文 ASR(LibriSpeech)上的错误率高于英文 TTS(LibriTTS)。GLM-4-Voice 在中文 TTS(AISHELL-1)上的表现优于中文 ASR(Seed-TTS)。
作者评估了包括 GLM-4-Voice-Tokenizer 在内的多种模型在不同帧率与比特率下的 ASR 与 TTS 性能。结果表明,与 Whisper-large-v3 和 SenseVoice-Large 等基线相比,GLM-4-Voice-Tokenizer 在重建指标上取得具有竞争力或更优的性能,尤其在较低帧率与比特率下表现突出。模型性能因条件不同而异,部分配置显示出语音与文本输出间更好的对齐效果。GLM-4-Voice-Tokenizer 在不同帧率与比特率下均展现出具有竞争力的重建性能。在较低帧率等特定条件下,模型性能有所提升,其在重建指标上优于其他模型。性能随帧率与比特率变化显著,表明 ASR 与 TTS 任务对这些参数较为敏感。
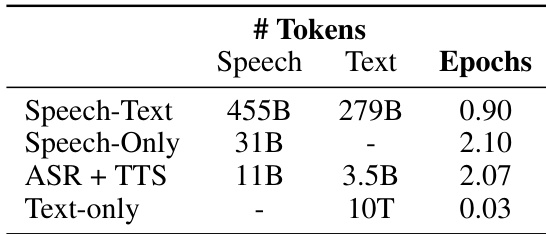
作者基于训练数据与参数对比了不同的模型配置。这些配置在使用数据类型(如语音-文本、仅语音、仅文本)以及 token 数量与训练轮数上存在差异。结果表明,使用语音-文本数据训练的模型相比仅使用语音或仅使用文本数据训练的模型,所需的 token 数量与训练轮数更少。与仅语音或仅文本模型相比,基于语音-文本数据训练的模型使用的 token 数量与训练轮数更少。仅文本配置所需的 token 数量与训练轮数显著多于其他配置。仅语音与 ASR + TTS 配置处于中间水平,其中 ASR + TTS 使用的 token 数量多于仅语音配置。
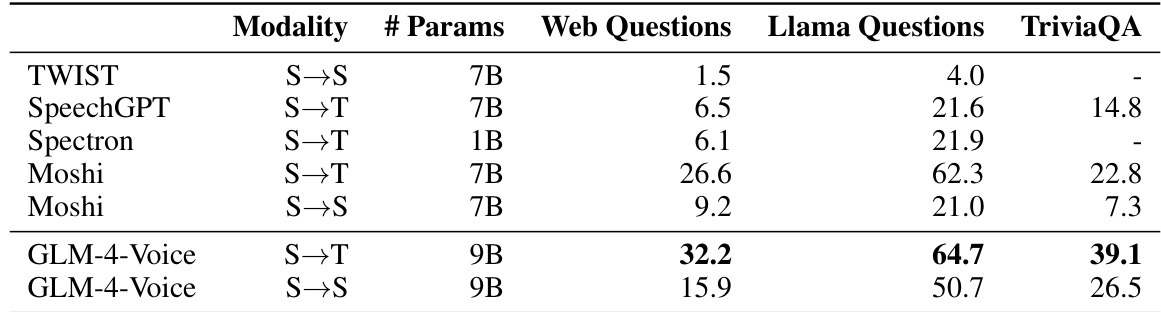
作者评估了 GLM-4-Voice 在不同模态的语音问答任务中的性能,并将其与多种基线模型进行对比。结果表明,GLM-4-Voice 在 S→T 与 S→S 设置下的准确率均高于其他模型,尤其在 S→T 设置下表现优异,且在 Llama Questions 与 TriviaQA 数据集上相比现有模型展现出性能提升。GLM-4-Voice 在多个数据集与模态的语音问答任务中均优于基线模型。该模型在 S→T 设置下的准确率高于 S→S 设置,表明在文本引导下的性能更优。GLM-4-Voice 在 Llama Questions 与 TriviaQA 上取得显著改进,尤其在 S→T 配置下表现突出。
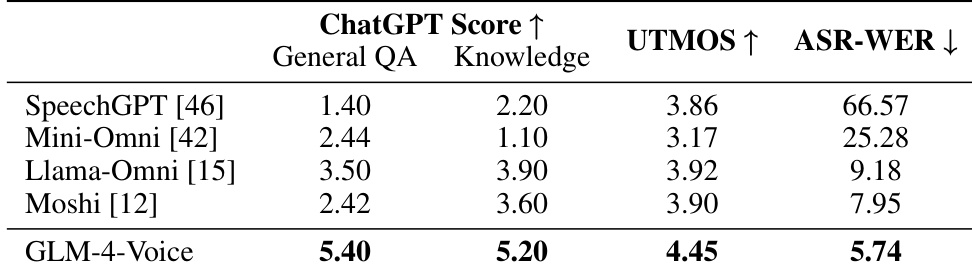
作者使用多项指标评估聊天模型性能,包括用于通用问答与知识任务的 ChatGPT 评分、用于语音质量的 UTMOS,以及用于语音-文本对齐的 ASR-WER。结果表明,与其他模型相比,GLM-4-Voice 在所有评估指标上均获得最高分,展现出卓越的文本与语音生成能力。GLM-4-Voice 在通用问答与知识任务中均取得最高 ChatGPT 评分。GLM-4-Voice 凭借最高 UTMOS 评分展现出最佳语音质量。GLM-4-Voice 的 ASR-WER 最低,表明生成的语音与文本回复对齐效果更佳。
实验在自动语音识别、文本转语音合成、语音问答与对话交互的标准基准上评估了 GLM-4-Voice 及其组件。这些测试验证了该模型与既定基线相比具有竞争力的性能,利用配对语音-文本数据时的高效训练需求,以及对不同音频压缩参数的强大适应性。结果一致凸显了其优越的跨模态推理能力与对话质量,证明该架构有效平衡了语音处理准确性与自然交互能力。总体而言,研究结果确认 GLM-4-Voice 是一款高效且通用的语音模型,在声学任务与端到端对话生成方面均表现卓越。