Command Palette
Search for a command to run...
乳腺癌风险预测
摘要
一句话总结
BioFusionNet 是一个用于 ER+ 乳腺癌生存风险分层的深度学习框架,它通过自监督提取器(DINO 和 MoCoV3)、变分自编码器以及共双交叉注意力机制整合组织病理学、遗传学和临床数据,采用加权 Cox 损失函数以解决生存数据不平衡问题,并实现了 0.77 的平均一致性指数和 0.84 的时间依赖受试者工作特征曲线下面积。
核心贡献
- 本文提出了 BioFusionNet,一种用于 ER+ 乳腺癌生存风险分层的深度学习框架,该框架整合了组织病理学切片、基因组谱和临床记录。其架构采用自监督 DINO 和 MoCoV3 提取器来捕捉详细的图像特征,并通过变分自编码器进行聚合以生成患者级表示。
- 共双交叉注意力机制结合组织病理学和遗传学特征,而前馈网络则整合临床数据以实现全面的多模态融合。训练过程采用自定义加权 Cox 损失函数,以有效解决生存数据集中固有的不平衡问题。
- 实证评估表明,该框架实现了 0.77 的平均一致性指数和 0.84 的时间依赖受试者工作特征曲线下面积。这些指标确立了其相较于现有最先进生存分析模型的卓越预测性能。
引言
准确的生存风险分层对于优化雌激素受体阳性乳腺癌的治疗路径至关重要,临床医生必须据此判断患者是否需要额外化疗,还是可以安全地仅依赖内分泌治疗。传统的预后模型主要依赖临床病理因素,经常忽略潜在的肿瘤生物学特征;而现有的深度学习方法难以调和结合组织病理学、基因组学和临床记录时固有的维度差异与异质性。为克服这些障碍,作者利用自监督特征提取和共双交叉注意力机制构建了 BioFusionNet,这是一个多模态生存预测框架,能够无缝整合多样化的数据源。此外,他们实现了加权 Cox 损失函数以校正生存数据集中的不平衡问题,最终提供更准确且可解释的风险评分系统,从而简化个性化治疗决策。
数据集

-
数据集构成与来源: 作者使用来自癌症基因组图谱乳腺癌浸润性癌(TCGA-BRCA)的多模态数据。全切片图像来源于 GDC 门户,而转录组和临床记录则从 cBioPortal 获取。该数据集结合了苏木精-伊红(H&E)染色的组织病理学切片、mRNA 表达谱以及标准化的患者记录。
-
子集详情与筛选: 本研究使用了一个经过筛选的 249 例队列,包含 149 例 Luminal A 型和 100 例 Luminal B 型肿瘤。作者通过为每种亚型选择 83 例具有生存结局的病例以及约三倍数量的删失病例,保留了原始的事件分布。基因组数据从最初的 20,438 个基因筛选为 138 个在 Oncotype DX、Mammaprint 和 PAM50 等商业检测中使用的临床相关标记物。临床记录被精简为四个变量:肿瘤分级、肿瘤大小、患者年龄和淋巴结状态。
-
处理与裁剪策略: 专家病理学家使用 QuPath 手动标注肿瘤边界,排除坏死区域同时保留间质和肿瘤浸润淋巴细胞。标注区域被下采样至每像素 0.25 微米,并裁剪为 224x224 像素的切片,每张切片生成约 500 个不重叠的切片。应用了基于矢量的颜色标准化以统一染色差异。RNA 测序数据在 RSEM 处理之后直接使用,未进行额外标准化。临床变量被二值化以符合 Cox 比例风险模型分析的要求。
-
模型使用与工作流: 作者为该多模态预后建模准备了此整合数据集。尽管提供的文本未明确指定训练或验证集划分,但经过筛选的切片、基因特征谱和二值化临床特征已结构化,用于训练生存预测模型并评估亚型特异性结果。平衡的病例选择与靶向基因筛选确保数据直接支持本研究对 Luminal A 和 B 型乳腺癌预后的关注。
方法
作者利用一个两阶段深度学习框架 BioFusionNet,旨在整合组织病理学、基因组和临床数据,用于 ER+ 乳腺癌的生存风险分层。整体架构设计为先提取并融合图像特征,随后将其与遗传和临床数据整合,以生成全面的患者级风险评分。该框架分为不同的阶段,每个阶段处理多模态数据处理的具体方面。
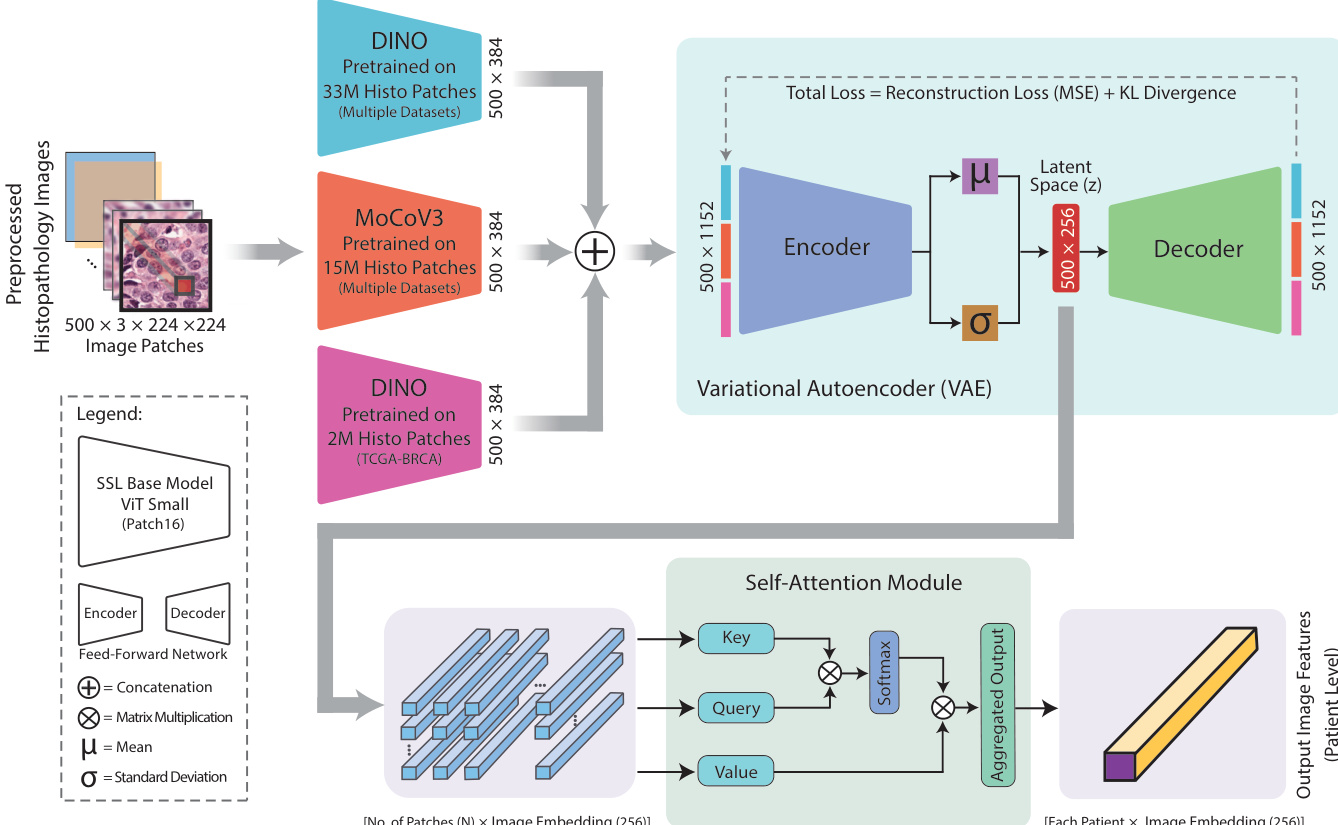
初始阶段专注于从组织病理学图像中提取丰富的形态学特征。该模型采用两种基于自监督视觉 Transformer(ViT)的架构 DINO 和 MoCoV3,并在大规模组织学数据集上进行预训练。DINO33M 在来自多个来源的 3300 万张多样化切片上进行训练,提供了对一般组织病理学模式的广泛理解;而 DINO2M 专门在 200 万张 TCGA-BRCA 切片上训练,能够捕捉乳腺癌特异性特征。MoCoV3 在 TCGA 和 PAIP 数据集的 1500 万张切片上进行预训练,通过动量对比增强了模型学习鲁棒表示的能力。这些模型中的每一个都处理 224×224×3 的图像切片,以生成 1×384 的特征向量。这些独立特征被拼接为单个 1times1152 向量 ftextcat(x),作为下一阶段特征整合的输入。
为了整合并精炼这些图像特征,采用变分自编码器(VAE)。VAE 的编码器将拼接后的特征向量 ftextcat(x) 映射到潜在空间,生成潜在表示的均值(mu)和标准差(sigma)。对于贡献 500 张切片的每位患者,这将生成一个大小为 500times256 的潜在空间矩阵。使用重参数化技巧对潜在变量 z 进行采样,z=mu+sigmacdotepsilon,其中 epsilonsimmathcalN(0,I),确保潜在空间被结构化为一个 500times256 的矩阵。VAE 的训练使用结合均方误差(MSE)用于重建精度和 Kullback-Leibler(KL)散度用于分布正则化的总损失函数,该函数鼓励潜在分布逼近标准正态分布。该过程有效融合了来自不同自监督模型的特征,增强了整体表示能力。
VAE 编码之后,自注意力模块将 500times256 的潜在切片级特征聚合为单个患者级表示。该模块计算键(K)、查询(Q)和值(V)向量的加权和,其中注意力分数由每个查询与键对之间的相关性决定。此过程使模型能够关注最相关的图像特征,同时将每个切片置于患者更广泛的组织病理学背景中进行上下文关联,从而生成全面的患者级嵌入。
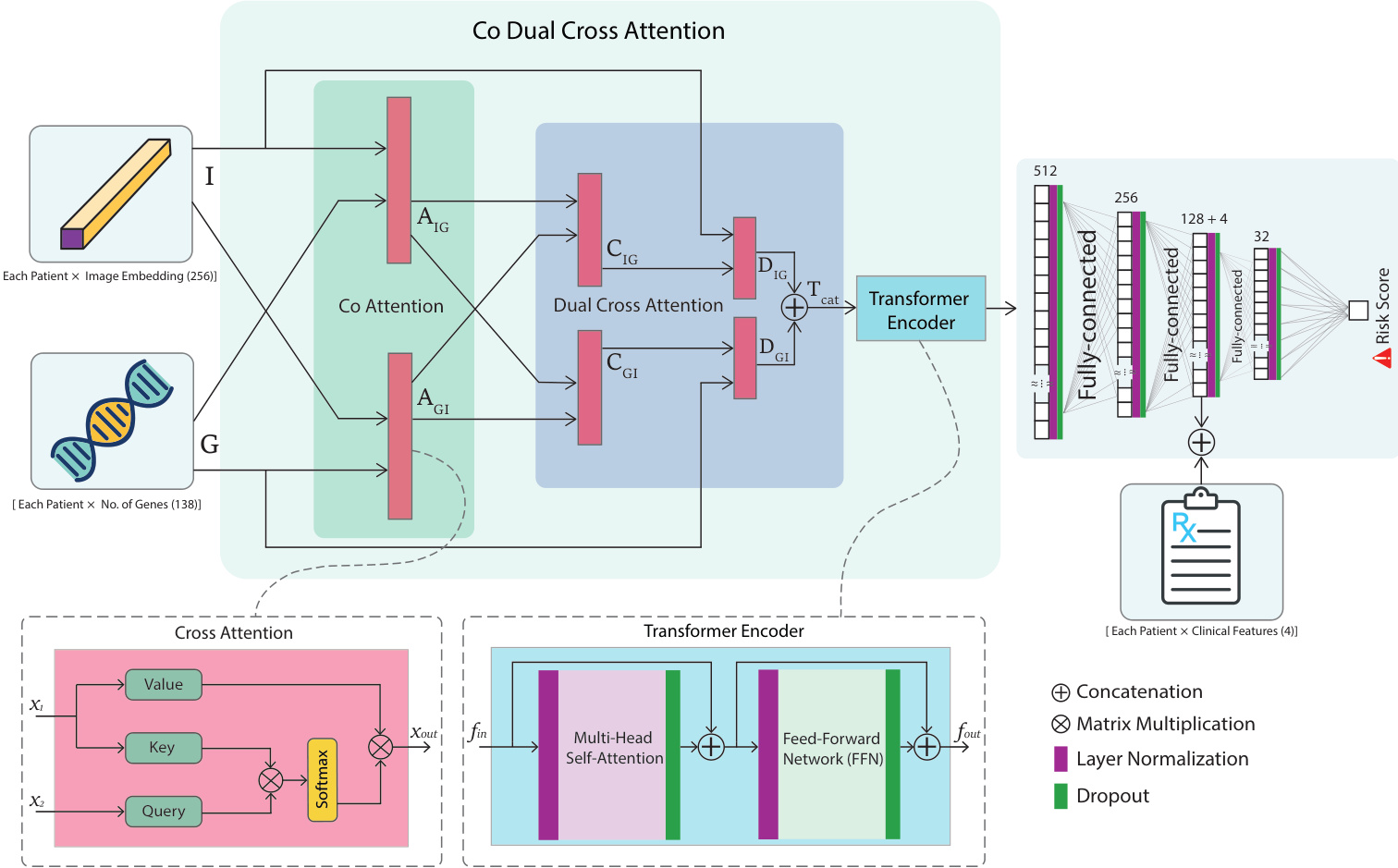
模型的第二阶段将患者级图像特征与遗传数据整合。采用共双交叉注意力机制来实现此融合。该机制首先应用共注意力,其中图像嵌入(I)和遗传特征(G)经过线性变换以生成查询(Q)、键(K)和值(V)向量。这生成双向注意力分数 AIG(图像到遗传)和 AGI(遗传到图像),它们通过 softmax 函数计算得出。双交叉注意力模块分两个阶段进一步精炼此整合。在第一阶段,共注意力特征用于计算交叉注意力输出 CIG 和 CGI,通过整合来自另一模态的上下文相关信息来增强各自模态。在第二阶段,这些输出被重新应用于其原始特征,以生成精炼的表示 DIG 和 DGI。拼接后的输出 Ttextcat=DIGoplusDGI 随后被输入到 Transformer 编码器中。
由多个相同层组成的 Transformer 编码器进一步同化融合后的图像和遗传特征。每层包含多头自注意力机制和逐位置的全连接前馈网络(FFN)。多头自注意力使模型能够同时关注来自不同表示子空间的信息。FFN 应用两次线性变换,中间夹着 ReLU 激活函数。在每个子层周围应用残差连接和层归一化以促进训练。这种深度整合产生了表型和基因型信息的整体表示。
仅包含四个特征的临床数据在网络后期阶段进行整合,以确保其影响力不被更高维的图像和遗传特征所掩盖。这种“晚期融合”策略涉及将临床数据与 Transformer 编码器的输出进行拼接。该拼接后的特征向量随后由一系列全连接层处理,其中第三层专门整合临床信息。最后一层是线性输出层,用于预测连续的生存风险评分。
为了解决生存数据不平衡的挑战,作者提出了一种加权 Cox 损失函数。该损失函数通过引入样本权重来修改传统的 Cox 比例风险损失,以减轻对删失数据的偏差。损失的计算方法为按风险对样本排序,计算加权累积风险,然后计算对数似然,最终损失由总加权事件进行归一化。这确保模型对少数事件类别保持敏感,从而提高在不平衡数据集上的预测性能。模型分两个阶段进行训练:第一阶段使用 AdamW 优化 VAE,第二阶段使用 Adam 配合加权 Cox 损失优化整个风险预测流程。采用早停机制以防止过拟合。
实验
该评估框架通过交叉验证生存分析、对比基准、消融研究和可解释性评估,系统性地评估了 BioFusionNet,以验证其多模态整合能力。每项实验均证实,结合图像、遗传和临床数据相较于单模态或传统方法能显著提升风险预测能力,而所提出的加权 Cox 损失和注意力机制则持续提高模型精度。生存分析与风险建模进一步表明,模型的风险分层与实际患者结果高度一致,优于传统临床指标。最后,可解释性分析验证了该架构能够有效分离具有临床意义的组织特征并识别关键预测生物标志物,尽管计算强度较高,但仍确立了该系统作为肿瘤学领域高精度且透明工具的地位。
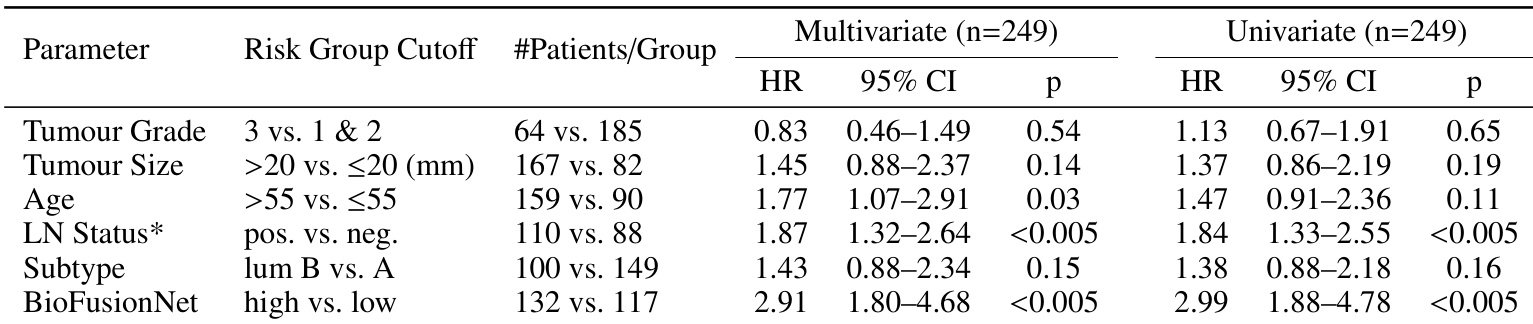
作者进行了风险建模分析,以评估 ER+ 乳腺癌患者中各种临床和预测因素与总生存期之间的关联。结果显示,BioFusionNet 预测的风险分组和淋巴结状态与生存结果显著相关,而其他因素如肿瘤分级和大小未显示显著关联。分析还强调,年龄和淋巴结状态等临床参数对模型的风险预测具有积极影响。
BioFusionNet 预测的风险分组和淋巴结状态与生存结果显著相关。在分析中,肿瘤分级和大小与生存未显示显著关联。年龄和淋巴结状态等临床参数对模型的风险预测产生了积极影响。
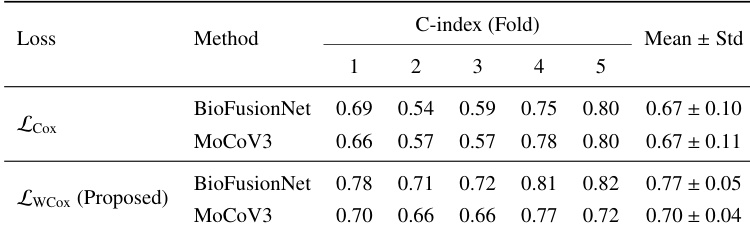
作者使用 C-index 在五个交叉验证折上比较了两种损失函数(传统 Cox 损失和所提出的加权 Cox 损失)在 BioFusionNet 和 MoCoV3 上的性能。结果显示,与传统 Cox 损失相比,所提出的加权 Cox 损失持续提升了两种方法的性能。这种提升在 BioFusionNet 中更为显著,该模型在使用所提出损失时实现了更高的平均 C-index 值。
与传统 Cox 损失相比,所提出的加权 Cox 损失持续提升了 BioFusionNet 和 MoCoV3 的 C-index 性能。在使用所提出的加权 Cox 损失时,BioFusionNet 实现了比 MoCoV3 更高的平均 C-index 值。在使用所提出损失函数时,BioFusionNet 的性能提升幅度大于 MoCoV3。
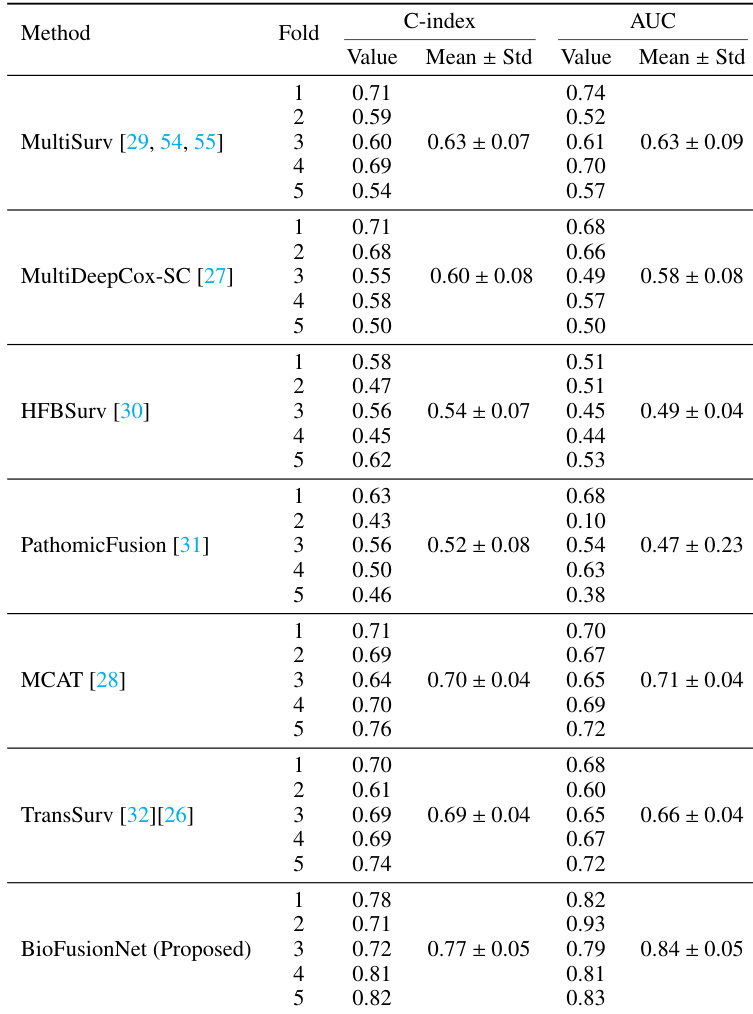
作者使用 C-index 和 AUC 指标将 BioFusionNet 的性能与几种最先进的方法进行了对比。结果显示,BioFusionNet 在这两项指标上均持续优于其他方法,并实现了最高的平均值。
表格表明,与所有基线模型相比,BioFusionNet 展现出卓越的预测性能。与所有其他方法相比,BioFusionNet 实现了最高的平均 C-index 和 AUC 值。所提出的模型在所有评估折中均持续优于现有的多模态融合方法。与基线模型相比,BioFusionNet 在 C-index 和 AUC 指标上均展现出卓越的预测性能。
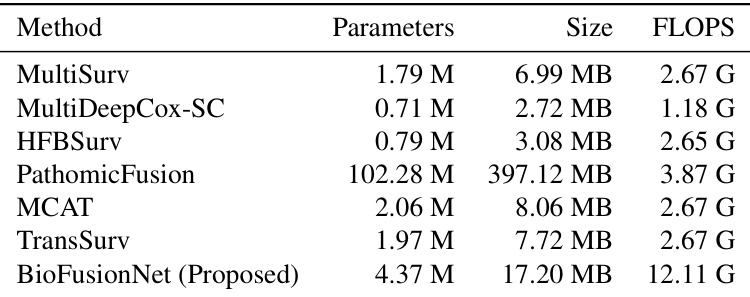
作者将 BioFusionNet 的计算属性与几种最先进的方法进行了比较,重点关注参数量、内存使用量和浮点运算次数。结果显示,BioFusionNet 在对比模型中需要最高的 FLOPS 数量,表明其计算需求更大,但同时也比某些替代方案更具内存效率。
与其他多模态融合方法相比,BioFusionNet 在 FLOPS 方面具有最高的计算成本。尽管计算需求较高,BioFusionNet 仍比 PathomicFusion 更具内存效率。与其他方法相比,所提出模型的参数量处于中等水平,表明其在复杂性与效率之间取得了平衡。
作者在不同模态配置下将 BioFusionNet 与其他模型的性能进行了比较,结果表明,结合图像、遗传和临床数据始终能产生比使用任何单一或双模态更高的预测性能。当整合所有三种数据类型时,该模型实现了最高的平均性能,优于传统方法和其他多模态融合方法。结果还表明,引入特定的注意力机制和加权损失函数进一步提升了预测精度。
与使用任何单一或双模态相比,BioFusionNet 在使用图像、遗传和临床数据共同作用时实现了最高性能。该模型优于 CoxPH 和 MLP 等传统方法以及其他多模态融合技术。引入高级注意力机制和加权损失函数提升了模型的预测精度。

实验评估了 BioFusionNet,这是一个多模态深度学习框架,旨在通过整合图像、遗传和临床数据来预测 ER+ 乳腺癌患者的总生存期。风险建模分析与模态整合测试证实,模型的风险分层与既定的临床预后因素高度一致,而同时使用所有三种数据类型则能产生最稳健的预测结果。对比基准测试表明,BioFusionNet 持续优于传统统计方法和最先进的融合技术,所提出的加权 Cox 损失和注意力机制进一步提升了其精度。最后,计算评估表明,尽管处理需求较高,该架构仍实现了卓越的内存效率,验证了其在复杂临床预测任务中的实际可行性。