Command Palette
Search for a command to run...
DeepSeek LLM:以长期主义扩展开源语言模型
DeepSeek LLM:以长期主义扩展开源语言模型
用 Ollama 和 Open WebUI 部署 DeepSeek R1
摘要
开源大型语言模型(LLM)的快速发展令人瞩目。然而,先前文献中描述的缩放定律得出了不同的结论,这为大规模扩展 LLM 蒙上了一层阴影。我们深入研究了缩放定律,并提出了独特的发现,这些发现有助于在两种广泛使用的开源配置(7B 和 67B)下扩展大规模模型。受缩放定律的指导,我们推出了 DeepSeek LLM 项目,该项目致力于以长期视角推动开源语言模型的发展。为了支持预训练阶段,我们开发了一个包含 2 万亿个 token 且仍在不断扩充的数据集。我们进一步对 DeepSeek LLM Base 模型进行了监督微调(SFT)和直接偏好优化(DPO),从而创建了 DeepSeek Chat 模型。我们的评估结果表明,DeepSeek LLM 67B 在一系列基准测试中超越了 LLaMA-2 70B,尤其是在代码、数学和推理领域表现尤为突出。此外,开放式评估显示,我们的 DeepSeek LLM 67B Chat 表现出优于 GPT-3.5 的性能。
一句话总结
DeepSeek 研究人员推出了开源的 DeepSeek LLM 系列(7B 和 67B),该系列利用缩放定律和包含 2 万亿 token 的语料库,在经过监督微调和直接偏好优化后,生成 DeepSeek Chat 模型。这些模型在代码、数学和推理基准测试中超越 LLaMA-2 70B,并在开放式评估中表现优于 GPT-3.5。
核心贡献
- 本研究建立了一个改进的缩放定律框架,使用每个 token 的非嵌入 FLOPs 替代传统的参数量,以优化模型架构与训练数据之间的算力分配。该框架提供了一种经验方法,用于预测接近最优的 batch size 和 learning rate,同时能够准确预测大规模模型的一般化损失。
- 分析表明,预训练数据质量直接决定了最优的算力分配,更高质量的数据证明将算力预算用于模型缩放而非数据扩展是合理的。这些见解指导了 DeepSeek LLM 变体在包含 2 万亿 token 英文和中文文本的持续扩展数据集上的从零训练。
- 本研究发布了 DeepSeek LLM 7B 和 67B 模型,其中较大版本通过监督微调和直接偏好优化进行微调,生成 DeepSeek Chat 系列。基准测试表明,DeepSeek LLM 67B 在代码、数学和推理任务上超越 LLaMA-2 70B,而经过对齐的 Chat 变体在开放式生成性能上优于 GPT-3.5。
引言
开源大语言模型的快速发展依赖于在模型规模和训练数据之间高效分配算力预算,以缩小与闭源系统的性能差距。然而,先前的缩放定律研究关于最优算力分配得出了相互矛盾的结论,且通常缺乏完整的超参数文档,导致如何可靠地将模型扩展至更高算力层级存在不确定性。为解决这些不一致之处,作者通过推导相对于算力预算的 batch size 和 learning rate 的经验幂律关系,并使用基于每个 token 非嵌入 FLOPs 的更精确指标替代参数量,重新校准了缩放定律。借助这些改进的缩放原则,他们在 2 万亿 token 的数据集上训练了 DeepSeek LLM 系列,并证明优化的超参数调度、准确的算力分配以及高质量数据共同使开源模型在核心推理、代码和对话基准测试中超越 LLaMA-2 70B 和 GPT-3.5。
数据集
-
数据集构成与来源: 作者通过整合 Common Crawl(涵盖 91 次转储)、两个版本的内部数据(早期和当前内部数据集)以及 OpenWebText2 构建了多语言训练语料库。收集策略参考了以往大规模语言模型项目的既定做法。
-
子集详情与过滤规则:
- Common Crawl: 处理涵盖 91 次转储,采用激进的跨转储去重策略,其去除的重复数据量是单次转储方法的四倍。
- 内部数据: 经过多次迭代优化循环。当前版本由于处理更为细致,质量高于早期版本。
- OpenWebText2: 作为质量最高的子集,受益于规模较小且经过严格筛选。
- 质量与多样性过滤: 使用稳健的语言学和语义标准评估文档,以最大化信息密度。重混合阶段调整混合比例以纠正数据不平衡,刻意增加代表性不足领域的比例。
-
数据使用与训练配置: 作者使用筛选后的语料库进行模型训练和缩放定律分析。他们迭代调整各来源比例,以衡量数据质量对算力分配的影响。分析表明,更高质量的数据提高了模型缩放指数,同时降低了数据缩放指数,表明算力预算应优先用于增加模型规模而非扩大数据量。
-
处理与分词详情: 流水线采用自定义的 Byte-level Byte-Pair Encoding (BBPE) 分词器。预分词阶段隔离换行符、标点符号和中文字符,以防止跨类别合并,而数字则被拆分为单个字符。基础词表包含约 24 GB 多语言文本上训练的 100,000 token,并增加了 15 个特殊 token。最终配置的词表大小设定为 102,400,以保持训练效率并为未来扩展预留空间。
方法
作者为 DeepSeek LLM 系列采用基于 transformer 的架构,紧密遵循 LLaMA (Touvron et al., 2023a,b) 的设计原则,使用 Pre-Norm 结构以及 RMSNorm (Zhang and Sennrich, 2019) 作为归一化函数。前馈网络 (FFN) 采用 SwiGLU (Shazeer, 2020) 作为激活函数,中间层维度设定为 38dmodel。位置编码采用 Rotary Embedding (Su et al., 2024),增强了模型捕捉序列关系的能力。为优化推理过程,67B 变体采用 Grouped-Query Attention (GQA) (Ainslie et al., 2023) 替代传统的 Multi-Head Attention (MHA),在保持性能的同时降低计算开销。
在宏观设计方面,DeepSeek LLM 系列展现出独特的缩放选择。7B 模型包含 30 层,而 67B 模型扩展至 95 层。这种基于深度的缩放策略优先增加模型深度而非加宽 FFN 中间层,与常见做法不同,旨在提升性能。模型架构的详细规格见表 2。
为确定最优缩放策略,作者推导了一种基于每个 token 非嵌入 FLOPs 的模型规模表示,记为 M。该指标计算了注意力操作的计算成本,但不包含与词表相关的计算,相较于非嵌入参数 N1 或总参数 N2 等常规度量,能更准确地近似模型规模。M 的公式定义如下:
6N1=72nlayerdmodel26N2=72nlayerdmodel2+6nvocabdmodelM=72nlayerdmodel2+12nlayerdmodellseq其中 nlayer 为层数,dmodel 为模型宽度,nvocab 为词表大小,lseq 为序列长度。表 3 对这些表示方法之间的差异进行了定量分析,突出了 6N1、6N2 与 M 之间的显著差异,尤其是在较小模型中。
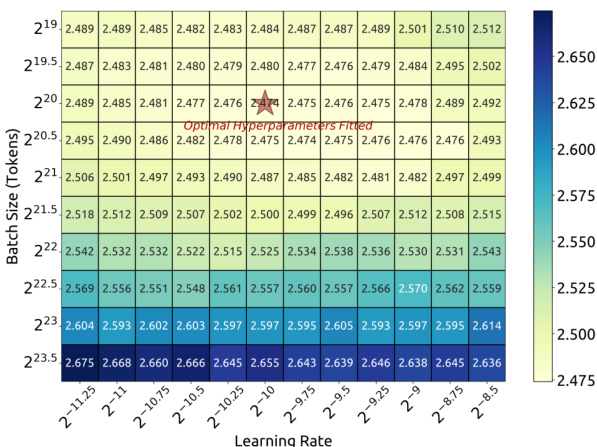
以 M 作为模型规模,目标是在固定算力预算 C=MD 下寻找能最小化一般化误差的最优模型规模 Mopt 和数据规模 Dopt。为实现此目标,采用 Chinchilla (Hoffmann et al., 2022) 中的 IsoFLOP 轮廓方法拟合缩放曲线。选择了八个算力预算,范围从 1e17 到 3e20,每个预算对应约十个模型/数据规模分配。超参数通过公式 (1) 确定,一般化误差在 1 亿 token 的验证集上进行评估。得到的最优缩放指数为:
Mopt=Mbase⋅Ca,Mbase=0.1715,a=0.5243Dopt=Dbase⋅Cb,Dbase=5.8316,b=0.4757图 4 展示了 IsoFLOP 曲线及拟合的最优模型/数据缩放曲线,显示了算力预算与验证集上 bits-per-byte 性能之间的关系。
图 5 所示的性能缩放曲线进一步验证了缩放预测的准确性。作者证明,小规模实验的结果可以可靠地预测算力预算高达 1000 倍的模型性能,为大规模模型训练提供了信心。
对齐过程分为两个阶段。首先,对 7B 和 67B 模型应用监督微调 (SFT),使用约 150 万条英文和中文指令数据实例,涵盖有用性和无害性主题。有用数据包含 120 万条实例,分布为 31.2% 通用语言任务、46.6% 数学问题和 22.2% 编程练习,而安全数据包含 30 万条实例,涵盖敏感主题。由于观察到过拟合现象,7B 模型微调 4 个 epoch,67B 模型微调 2 个 epoch。7B 和 67B 模型的 learning rate 分别设为 1e−5 和 5e−6。在 SFT 期间,作者监控基准准确率和重复率,指出增加数学 SFT 数据可能导致较弱模型出现更高的重复率。为缓解此问题,采用两阶段微调和 DPO (Rafailov et al., 2023),两者均在未损害基准性能的情况下降低了重复率。
第二阶段应用直接偏好优化 (DPO) 以进一步提升模型。偏好数据基于有用性和无害性构建,使用涵盖创意写作、问答和指令遵循的多语言提示。响应由 DeepSeek Chat 模型生成作为候选。DPO 训练进行一个 epoch,learning rate 为 5e−6,batch size 为 512,并采用带 warmup 的余弦学习率调度器。结果表明,DPO 在几乎不影响标准基准性能的前提下,增强了开放式生成能力。
实验
评估设置涵盖公开的双语基准测试、开放式生成测试、预留的真实世界数据集以及专家筛选的安全评估,旨在系统验证不同规模的基础模型和 Chat 模型。这些实验证实,多步训练调度和超参数缩放定律具有鲁棒性和可预测性,而模型规模的扩大显著提升了推理、编码及对未见任务的泛化能力。对齐流程,包括分阶段监督微调和直接偏好优化,有效增强了指令遵循、对话质量及安全护栏,且未削弱核心知识。综合来看,研究结果证明所提出的流水线能够产出高度能力出众的双语语言模型,具备先进的逻辑推理能力和可靠的安全机制,可与顶级闭源系统相媲美。
作者展示了详细列出 7B 和 67B 两种模型规模的架构与训练参数的表格,突出了配置差异。结果表明,较大模型拥有更多层数、更大的模型维度以及更多的注意力头,同时伴随更长的上下文长度和更大的 batch size,而两种模型均在相同数量的 token 上训练。与 7B 模型相比,67B 模型在层数、模型维度和注意力头上显著更多。67B 模型在训练期间使用更长的上下文长度和更大的 batch size。两种模型均在相同数量的 token 上训练,表明训练规模保持一致。

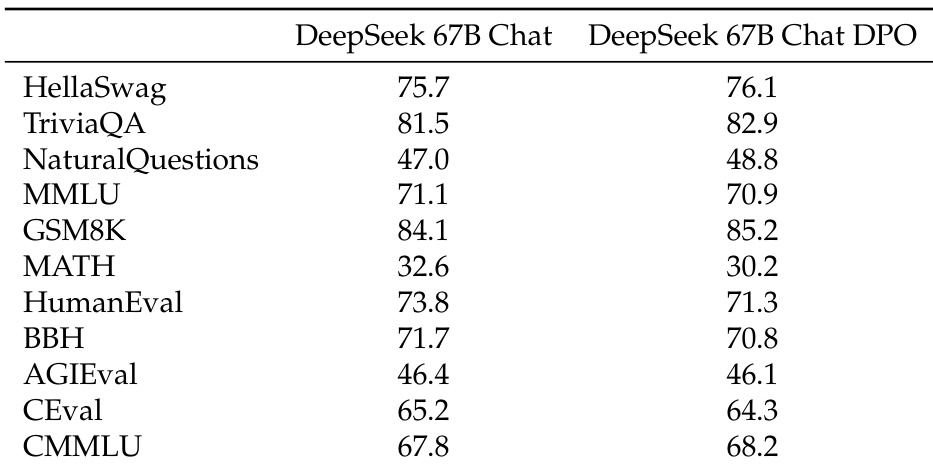
该表格对比了 DeepSeek 67B Chat 与 DeepSeek 67B Chat DPO 在各项基准测试中的表现,显示 DPO 阶段在多数任务中带来性能提升。结果表明,DPO 模型在大部分评估指标上优于基础模型,在数学和推理任务中提升显著,而部分语言理解任务的表现保持稳定或略有下降。DPO 阶段改善了大多数基准测试的性能,尤其在数学和推理任务中。模型在多个评估类别中均呈现稳定增长,DPO 版本得分高于基础模型。部分任务如 TriviaQA 和 HellaSwag 在 DPO 阶段后出现轻微性能下降,表明特定评估类型可能存在权衡。
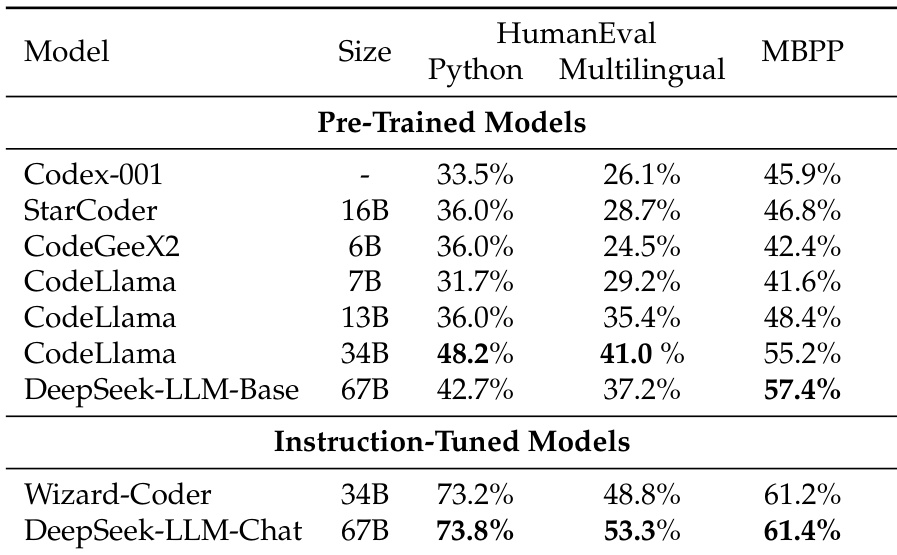
该表格对比了各类预训练与指令微调模型在代码相关任务上的表现,显示 DeepSeek-LLM-Base 和 DeepSeek-LLM-Chat 取得了具有竞争力的结果,尤其在多语言和 MBPP 基准测试中。指令微调模型在大多数类别中表现优于其他模型,表明微调对代码生成任务的有效性。与其他指令微调模型相比,DeepSeek-LLM-Chat 在所有评估任务中均取得最高分。DeepSeek-LLM-Base 在多语言和 MBPP 基准测试中表现强劲,超越多个特定代码模型。指令微调模型通常得分高于预训练模型,突显了微调对代码生成任务的益处。
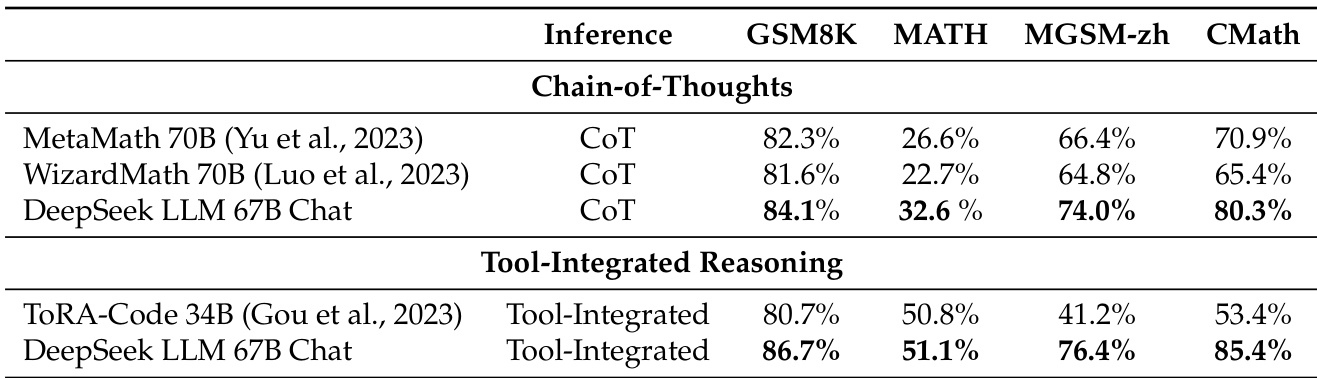
该表格对比了不同模型在数学相关任务上使用两种推理方法的表现:思维链 (Chain-of-Thoughts) 与工具集成推理 (Tool-Integrated Reasoning)。DeepSeek LLM 67B Chat 在两种方法中均取得高分,在多项基准测试中超越其他模型,尤其在工具集成推理方面,相较于 ToRA-Code 34B 展现出显著改进。结果表明,DeepSeek LLM 67B Chat 具备与最先进模型相竞争的实力,尤其在通过工具集成处理数学问题时。在 GSM8K 和 MATH 基准测试的思维链任务中,DeepSeek LLM 67B Chat 超越 MetaMath 70B 和 WizardMath 70B。在 MGSZ-zh 和 CMath 的工具集成推理任务中,DeepSeek LLM 67B Chat 取得最高分,超越 ToRA-Code 34B。该模型在两种推理方法中均表现出强劲性能,且在工具集成推理方面相较于其他模型提升显著。
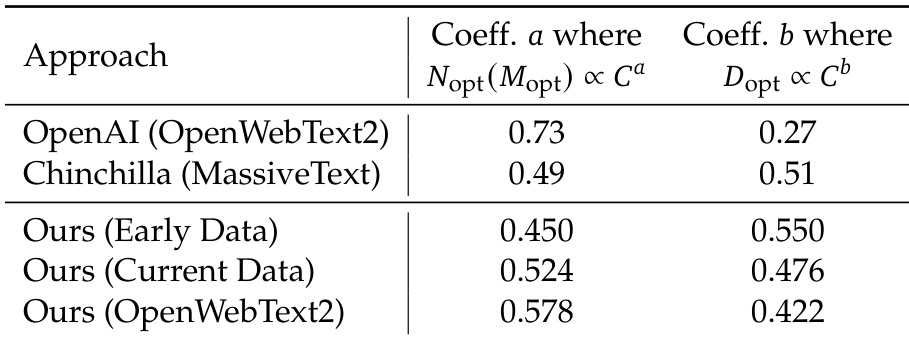
作者将模型的缩放行为与现有方法进行了对比,显示其当前数据方法与基于 OpenWebText2 的方法在相对于算力预算的最优模型规模和数据分配上表现出不同的缩放系数。结果表明,与 OpenAI 的方法相比,其当前数据方法导致模型规模缩放的系数更高,而数据分配缩放的系数更低。作者当前数据方法的最优模型规模缩放系数高于 OpenAI 的方法。作者当前数据方法的最优数据分配缩放系数低于 OpenAI 的方法。基于 OpenWebText2 的方法在数据分配上显示出比当前数据方法更高的缩放系数。
实验评估了架构缩放、对齐微调、代码生成、数学推理及数据分配策略,以验证模型在多元领域的性能。扩展至更大参数规模并应用直接偏好优化显著增强了推理与对齐能力,而指令微调则专门验证了针对多语言代码任务的目标微调有效性。该架构在标准及工具增强数学推理方面相较于现有系统展现出更优的熟练度。最后,训练数据策略揭示了独特的缩放行为,在算力分配上优先于模型规模而非数据量,共同证实了一条高效的大语言模型开发路径。