Command Palette
Search for a command to run...
注意力机制和 Transformer
摘要
一句话总结
作者提出了个性化注意力机制(PersAM),这是一种基于 Transformer 的方法,通过编码跨模态关系,根据患者临床记录自适应地调整医学图像中的注意力区域,并使用千兆像素全切片图像在 842 名恶性淋巴瘤患者中评估了其识别亚型的效能。
核心贡献
- 个性化注意力机制(PersAM)利用 Transformer 架构编码千兆像素全切片图像与表格化临床记录之间的跨模态关系,实现基于患者特定因素的注意力区域动态调整。
- 该框架计算图像块与临床数据之间的双向注意力,生成适应个体患者记录的个性化诊断关注区域,有效模拟了专家病理学家基于先验知识的检查流程。
- 在 842 名恶性淋巴瘤患者队列中的应用证明了该方法利用全切片图像和临床记录识别亚型的有效性,同时生成的注意力图反映了患者特定的诊断优先级。
引言
数字病理学依赖于使用多实例学习分析海量全切片图像,以在无像素级标注的情况下检测肿瘤。尽管基于注意力的模型以及结合组织学与临床记录的多模态框架已提升了诊断准确率,但现有方法主要将患者数据作为辅助输入以优化性能指标。这些先前方法很少探讨特定临床因素如何主动重塑模型对图像区域的关注,导致临床可解释性方面存在空白。作者利用 Transformer 架构将组织学图像块与表格化患者记录相融合,实现了基于个体临床病史个性化图像关注的动态交叉注意力。该方法生成了可解释的注意力图,高度还原了专家病理学家在诊断过程中整合病历的方式,推动了诊断推理与临床透明度的发展。
数据集

-
数据集构成与来源
- 作者使用了一个由专家血液病理学家确认的 842 例恶性淋巴瘤病例的临床数据库。
- 每个病例将 H&E 染色组织标本的千兆像素全切片图像与结构化临床记录配对。
- 所有 WSI 均使用 Aperio GT 450 扫描仪在 40 倍放大倍率下(0.26 μm/像素)进行数字化,最大尺寸约为 100,000 x 100,000 像素。
-
各子集关键细节
- 队列包含 277 例弥漫大 B 细胞淋巴瘤(DLBCL)病例,其特征为广泛组织区域内的大肿瘤细胞;270 例滤泡性淋巴瘤(FL)病例,显示伴有肿瘤细胞的滤泡结构;以及 295 例反应性淋巴增生病例,呈现多样的非肿瘤细胞形态。
- 标注严格为病例级而非图像块级,这意味着亚型标签适用于整个 WSI 并传播至所有派生的图像块。
-
裁剪策略与元数据构建
- 作者从每个 WSI 中随机提取 224 x 224 像素的图像块,将 100 个图像块分组为一个 bag 以平衡计算负载与内存使用。
- 每个 WSI 最多采样 30 个 bag,每个 bag 继承原始病例标签。
- 包含 28 个变量的临床元数据被压缩为两个 512 维向量,分别代表患者人口统计学与访谈数据(18 个特征)和血液检测结果(10 个特征)。
- 图像块使用预训练的 ResNet50 主干网络后接一个具有 1024 个隐藏单元的两层神经网络,编码为 512 维特征向量。
-
数据使用与训练配置
- 数据集按 3:1:1 的比例划分为训练集、验证集和测试集,并通过五折交叉验证进行评估。
- 输入数据通过将图像块特征、临床向量以及三个 512 维的 class token 组合成 512 x 105 的矩阵,以适配 Transformer 格式。
- 训练采用随机水平翻转和 90 度旋转增强、标签平滑(正确类别 0.95,错误类别 0.05),以及具有组件特定学习率的动量 SGD,共训练九个 epoch。
方法
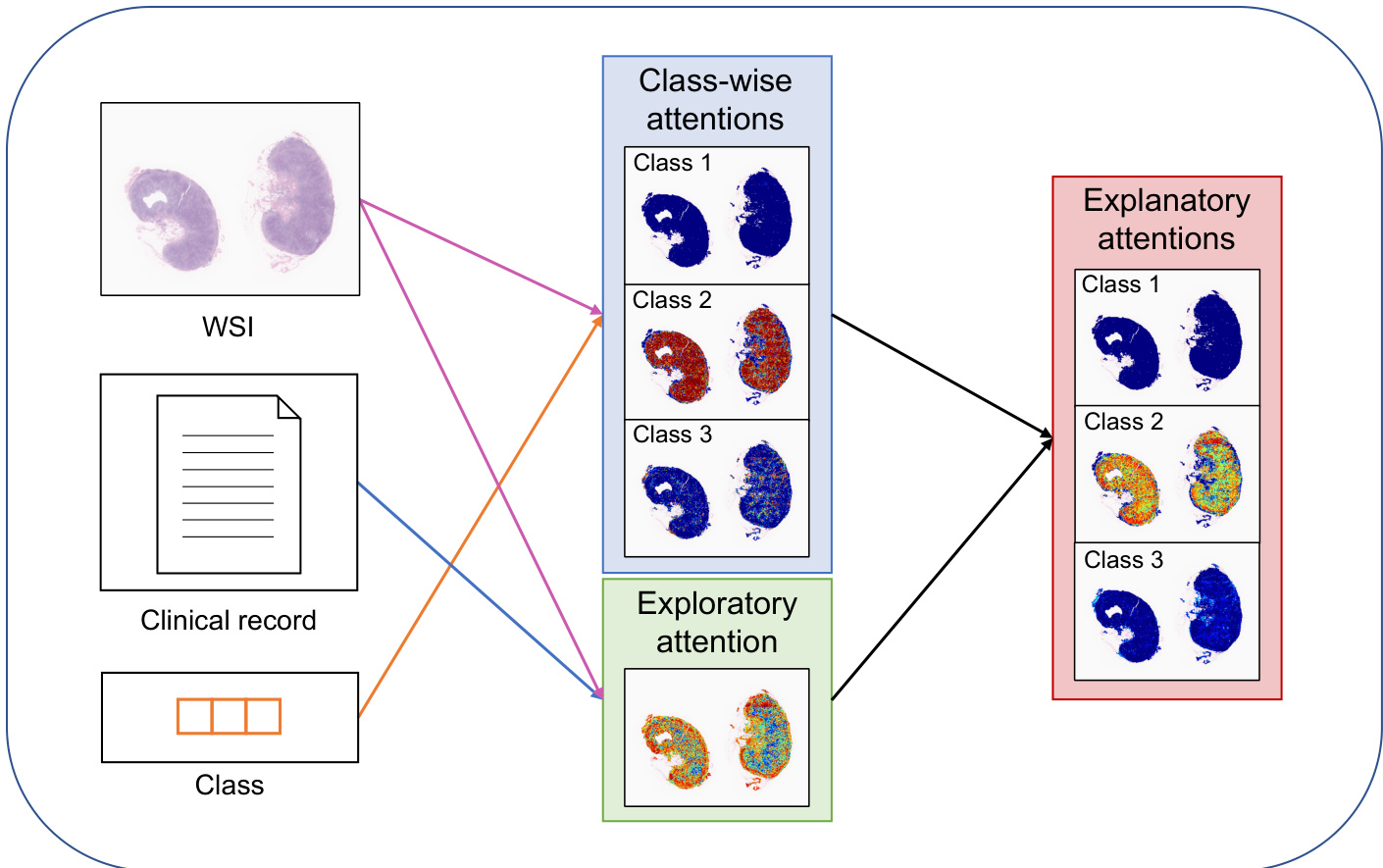
提出的 PersAM 框架旨在通过整合医学图像与临床记录来模拟人类病理学家的诊断过程,从而生成个性化注意力区域与亚型分类。整体架构包含三个主要组件:特征提取器、多模态编码器与多模态聚合器。这些组件协同工作以编码和处理多模态信息,使模型能够生成适应患者特定临床数据的探索性注意力图与解释性注意力图。
如图所示,模型的输入包含给定患者的全切片图像(WSI)与临床记录。WSI 被分解为一组图像块,每个图像块独立进行处理。 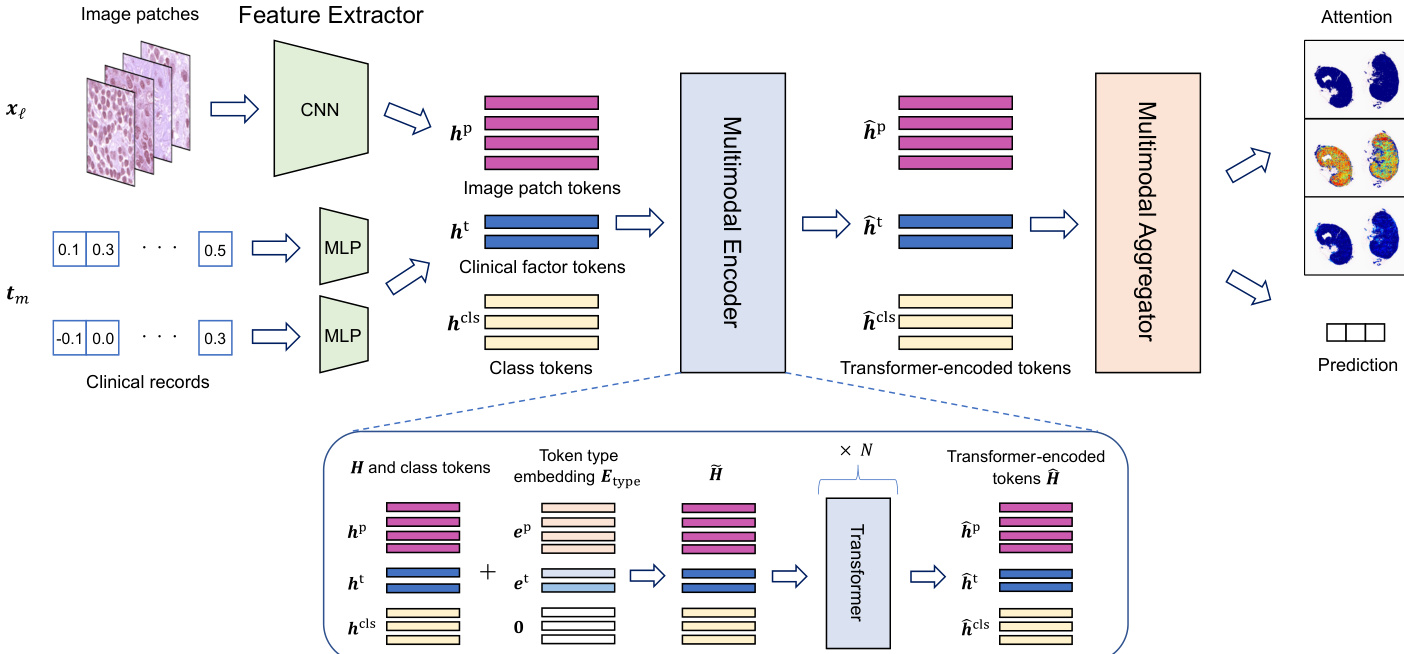
特征提取器组件为图像块和临床因素计算特征向量,为多模态整合做准备。对于图像块,卷积神经网络(CNN)将每个图像块 xℓ 映射为特征向量 hℓp∈RR。对于临床因素,多层感知机(MLP)将每个因素 tm 映射为特征向量 hmt∈RR,确保两种模态均在共同特征空间中表示。所得特征向量集合 H={hℓp}ℓ∈[L]∪{hmt}m∈[M] 构成多模态编码器的输入。
多模态编码器以 Transformer 实现,用于表征图像块、临床因素与类别信息之间的关系。该组件输入包含图像块 token {hℓp}ℓ∈[L]、临床因素 token {hmt}m∈[M] 以及类别 token {hccls}c∈[C] 的序列。为区分这些 token 类型,向每个 token 添加 token 类型嵌入 Etype,其中 Etype=[Lep,…,ep,e1t,…,eMt,C0,…,0]⊤,ep 与 {emt}m∈[M] 为可训练参数。Transformer 处理该增强输入以生成一组编码后的 token,H^={{h^ccls}c∈[C],{h^ℓp}ℓ∈[L],{h^mt}m∈[M]}。
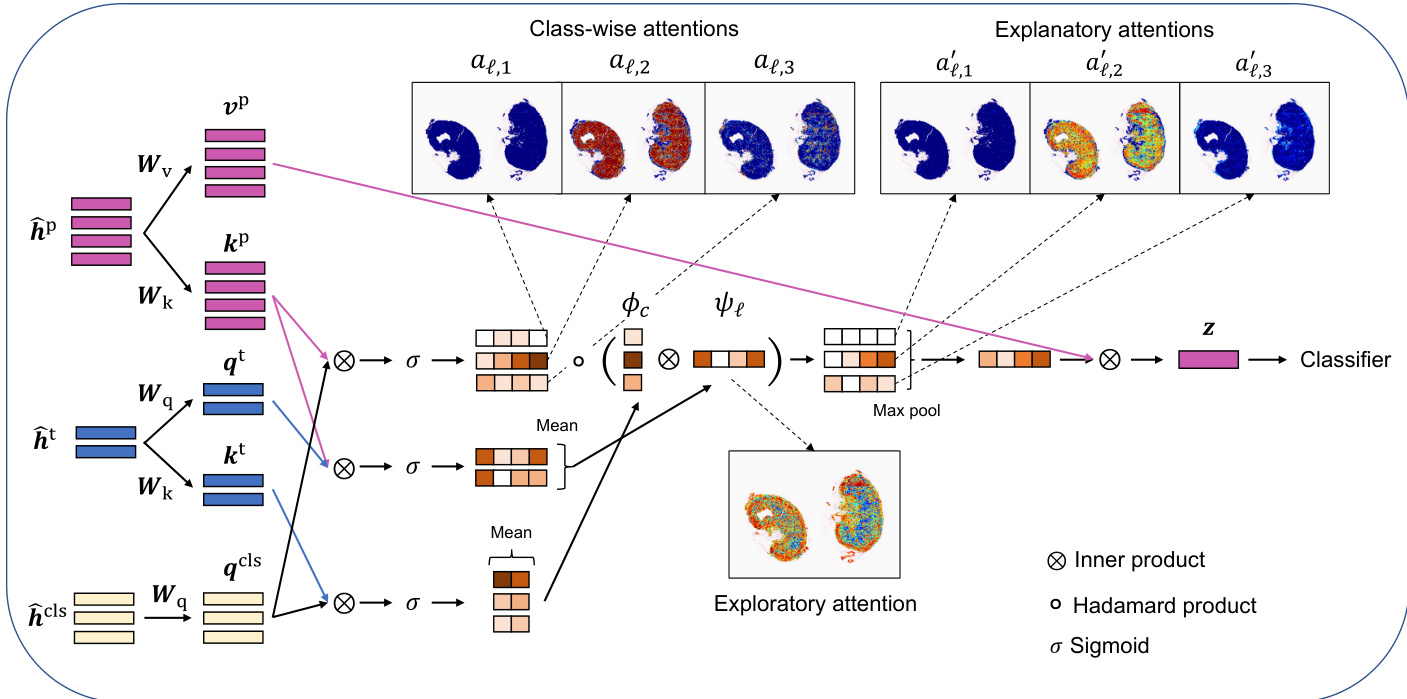
多模态聚合器处理 Transformer 编码后的 token,以计算探索性注意力与解释性注意力,并生成分类预测。它首先使用可训练权重矩阵 Wq,Wk,Wv∈RR×R 为类别 token、临床因素 token 和图像块 token 计算 query、key 和 value。每个图像块与每个类别 token 之间的相关性由各自 query 与 key 的内积确定,得到类别级注意力 aℓ,c=σ(qccls⊤kℓp),其中 σ(⋅) 为 sigmoid 函数。每个图像块与临床因素之间的相关性通过平均相关性 ψℓ=M1∑m∈[M]σ(qmt⊤kℓp) 来捕捉,这被定义为探索性注意力。每个类别与临床因素之间的相关性 ϕc=M1∑m∈[M]σ(qccls⊤kmt) 用于调节类别级注意力。随后,每个图像块与类别的解释性注意力计算为 aℓ,c′=aℓ,cϕcψℓ。
分类结果通过对加权了解释性注意力的图像块特征向量进行聚合获得。具体而言,计算聚合特征向量 z=∑ℓ∈[L]∑ρ=1Laρ′aℓ′vℓp,其中 aℓ′=max(aℓ,1′,…,aℓ,C′)。该向量随后输入神经网络分类器 gclf 以生成预测类别概率 Y^。模型使用组合损失函数进行端到端训练,该函数结合交叉熵损失与二元交叉熵损失,以适配问题的多实例学习(MIL)特性,即若 bag 内任一实例为正,则该 bag 视为正样本。
实验
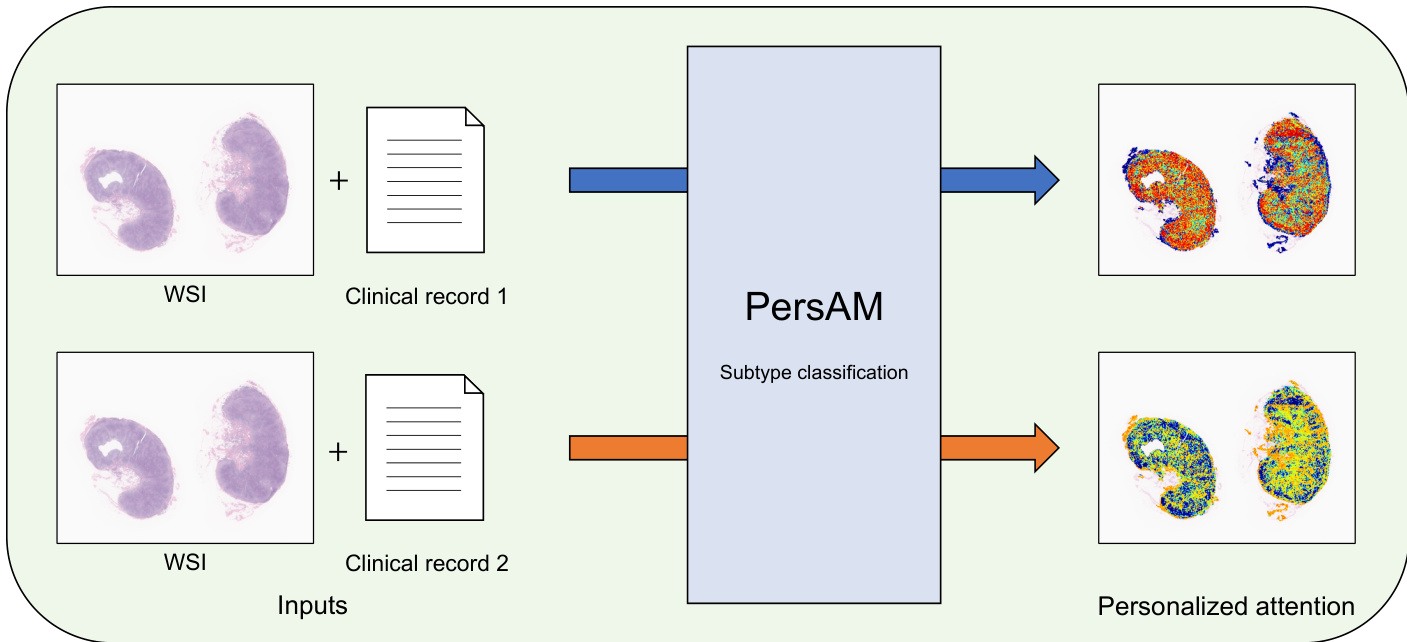
评估设置包含使用五折交叉验证的三分类亚型分类任务,并辅以注意力可视化实验,该实验处理具有不同真实与合成临床记录的相同全切片图像。这些实验验证了所提方法通过有效整合多模态特征实现了更优的诊断准确率,同时其个性化注意力机制能够动态适应临床上下文。定性分析表明,注意力转移主要在诊断模棱两可的病例中被触发,使得模型在仅凭视觉特征不足时能够优先关注相关的组织学区域。专家血液病理学家的审阅进一步证实,这些自适应行为与临床推理相一致,表明该模型通过模拟专家决策过程,能够可靠地区分典型病例与非典型病例。
{"summary": "作者在三分类任务中将所提方法与多种基线方法进行了比较,结果表明所提方法取得了最高的准确率。结果表明,通过多模态聚合器整合图像与临床特征,相比仅使用单一模态的方法,分类性能得到了提升。所提方法的注意力机制会根据输入的临床记录进行自适应调整,尤其是在组织学特征模糊的病例中。", "highlights": ["所提方法在所有基线方法中取得了最高的分类准确率。", "所提方法优于仅使用图像或临床数据的基线模型,表明多模态特征整合具有优势。", "注意力机制能够适应不同的临床输入,尤其是在组织特征模糊的病例中,与专家诊断推理相一致。"]
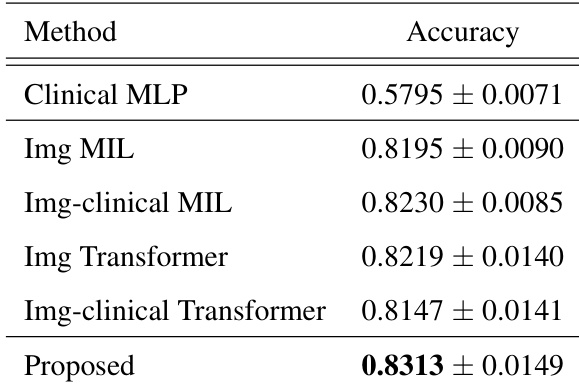
该评估在三分类任务中将所提框架与多种基线方法进行对比,以评估多模态整合与自适应注意力机制的有效性。结果表明,与单一模态方法相比,将组织学图像与临床记录相融合始终能产生更优的分类性能。此外,模型能够根据临床上下文动态调整关注焦点,以符合专家诊断推理的方式有效处理模糊的组织特征。