Command Palette
Search for a command to run...
NLP 中的提示式学习范式-第 1 部分
摘要
一句话总结
本文回顾了自然语言处理领域近期出现的范式转变现象,即预训练语言模型将某一任务重构为另一任务,以提升性能并将多样化任务统一至单一模型中。
核心贡献
- 本研究系统回顾了自然语言处理中的范式转变,将基于提示、基于匹配、MRC 和 Seq2Seq 框架归类为统一策略,这些策略将多样化任务重构为单一的建模流程。
- 对比分析表明,尚未被充分探索的范式在工程简洁性、可解释性和结构灵活性方面具有显著优势,同时通过自监督预训练或语言模型初始化实现具有竞争力的性能。
- 在结构化预测和信息提取任务上使用 T5 和 BART 进行的评估指出,数据饥渴现象和自回归推理延迟是关键瓶颈,从而引导未来研究转向非自回归和高效解码技术。
引言
在现代自然语言处理中,预训练语言模型的快速普及使研究人员能够将传统任务重构为替代性的建模框架。这种范式转变具有重要意义,因为它打破了对僵化、特定任务架构的依赖,为统一模型铺平了道路,这些模型能够提升数据效率、增强跨任务泛化能力,并简化商业部署。历史上,该领域依赖序列标注或分类等孤立范式,这些范式需要大量标注数据,在领域迁移方面表现不佳,且需要维护多个专用系统。作者系统梳理了核心自然语言处理任务中近期的范式转移情况,评估了掩码语言建模、匹配、机器阅读理解和序列到序列模型等框架的统一潜力,并对其架构权衡提供了结构化分析,以指导未来的研究方向。
数据集
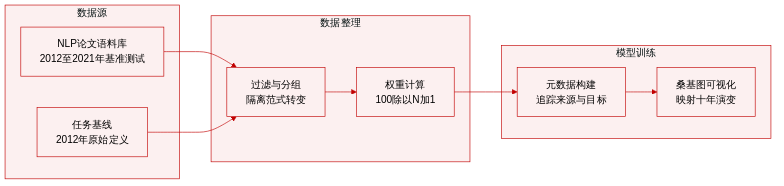
- 数据集构成与来源: 作者汇编了涵盖 2012 年至 2021 年已发表自然语言处理论文的文献计量语料库。该集合涵盖多个标准基准测试,并包含事件提取等额外常见任务。
- 子集详情与过滤规则: 每个自然语言处理任务都以其 2012 年初始版本确立的基线范式为锚点。作者过滤语料库,仅保留采用与该基线不同方法论方法的论文,然后根据这些条目的初始范式和当前范式进行分组。
- 用途与处理: 该数据集仅用于分析目的,而非模型训练或混合融合。作者对过滤后的条目进行处理,为每个范式分配初始值 100,并使用公式 100 除以 N 加 1 计算分支权重,其中 N 表示从该范式转移出去的任务总数。这些计算值驱动下游的可视化流程。
- 元数据构建与可视化: 结构化元数据记录任务起源、目标范式和发表年份。完整的参考文献收录于表 2 中,聚合指标则用于生成桑基图,映射自然语言处理方法论长达十年的演变过程。此处理过程凸显了在预训练语言模型兴起后,传统框架(如 Class、SeqLab 和 Seq2ASeq)正逐渐向灵活方法(如 (M)LM、Matching、MRC 和 Seq2Seq)迁移的趋势。
方法
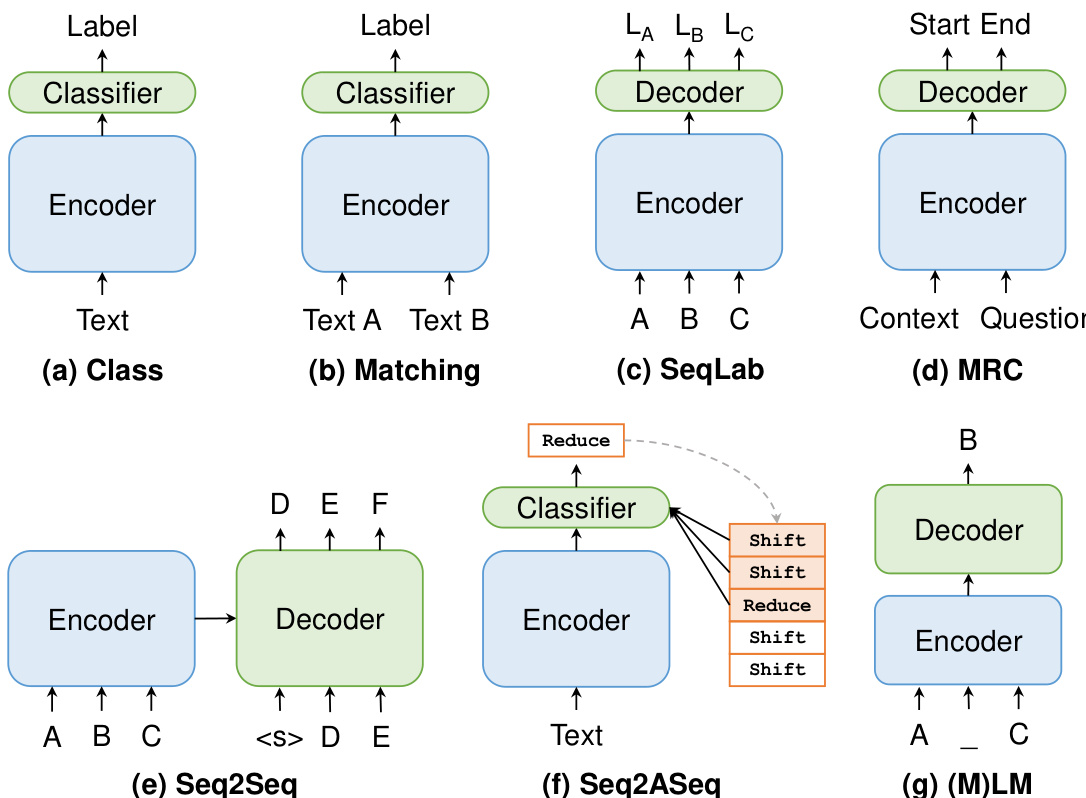
作者利用模块化框架分析和统一多种自然语言处理(NLP)范式,每种范式均由其独特的输入结构、建模方法和输出格式定义。这些范式的核心架构包含一个编码器,用于将输入文本处理为上下文表示,随后是一个解码器或分类器,用于生成最终输出。编码器通常为循环神经网络或基于 Transformer 的模型,而解码器或分类器则适配特定任务的需求。
在 Class 范式中,模型通过编码器处理单个文本输入,并将生成的表示传递给分类器以预测离散标签。该范式常用于情感分析和文本分类等任务。在 Matching 范式中,两个文本输入被分别编码,随后通过逐元素乘法或拼接等机制进行交互,接着由分类器预测输入之间的关系。该框架应用于自然语言推理和语义相似度等任务。
序列标注(SeqLab)范式涉及对 tokens 序列进行编码,并使用解码器预测序列中每个 token 的标签。该方法广泛应用于词性标注和命名实体识别等任务。解码器通常采用条件随机场(CRF)来建模相邻标签之间的依赖关系。机器阅读理解(MRC)范式将段落和问题作为输入,对它们进行联合编码,并预测段落中回答问题的文本跨度。这通常通过两个分类器来实现,分别预测答案跨度的起始和结束位置。
序列到动作序列(Seq2ASeq)范式专为结构化预测任务设计,其目标是生成一系列动作,将初始配置转换为期望的最终状态。这是通过基于当前配置迭代预测动作来实现的,当前配置可能包含栈和缓冲区等元素。模型对输入文本进行编码,并使用解码器输出动作序列,该序列可用于构建依存树等结构。
(M)LM 范式通过用包含未填充槽位的提示修改输入,将下游任务重构为掩码语言建模任务。预训练语言模型填充这些槽位,输出 tokens 通过 verbalizer 映射到任务标签。这种方法被称为基于提示的学习,它通过利用预训练模型的知识,无需大量特定任务的训练即可实现少样本和零样本学习。提示和 verbalizer 的选择至关重要,它们可以手动设计、从语料库中挖掘,或使用其他模型生成。