Command Palette
Search for a command to run...
FlashMemory-DeepSeek-V4: فهرس البرق للسياق فائق الطول عبر انتباه متناثر ذو نظرة إلى الأمام
FlashMemory-DeepSeek-V4: فهرس البرق للسياق فائق الطول عبر انتباه متناثر ذو نظرة إلى الأمام
الملخص
تحافظ نماذج اللغات الكبيرة التقليدية على تحميل ذاكرة التخزين المؤقت الكاملة للـ KV أثناء عملية التوليد، مما يُسبب اختناقاً حاداً في ذاكرة وحدة معالجة الرسومات عند خدمة السياقات فائقة الطول. في هذا التقرير، نقترح الانتباه المتناثر الاستباقي (Lookahead Sparse Attention - LSA)، وهو نموذج استنتاجي مبتكر يعمل بمُؤشر ذاكرة عصبية مُصمم على أساس بنية DeepSeek-V4. وبدلاً من الانتباه بشكل سلبي إلى جميع الـ tokens التاريخية، يتنبأ LSA استباقياً بمتطلبات السياق المستقبلية، ويحتفظ فقط بقطع ذاكرة الـ KV الحرجة للاستعلام داخل ذاكرة وحدة معالجة الرسومات. ونظراً لأهميته، نُجسّد هذه البنية عبر استراتيجية تدريب منفصلة لا تعتمد على نموذج أساسي. ومن خلال صياغة المُؤشر كبنية مزدوجة التشفير قياسية، ندرّبه بشكل مستقل باستخدام أطر عمل تدريب الاسترجاع القياسية، دون الحاجة إلى تحميل النموذج الأساسي الضخم في ذاكرة وحدة معالجة الرسومات على الإطلاق. ونُثبت أن هذا النهج "الأقل هو أكثر" يعظم كفاءة الخدمة بشكل كبير، مع أدائه كمنقي فعال للضوضاء في الانتباه في المهام التي تعتمد على الذاكرة العالمية طويلة المدى. وعبر مجموعات التقييم الرئيسية للسياق الطويل (مثل LongBench-v2، وLongMemEval، وRULER)، يقوم FM-DS-V4 بضغط متوسط البصمة الفيزيائية لذاكرة التخزين المؤقت للـ KV إلى 13.5% فقط من الأساس المرجعي للسياق الكامل، مع الحفاظ باستمرار على دقة المهام اللاحقة أو رفعها طفيفاً (بهامش مطلق متوسط قدره +0.6%). ونظراً لأهميته البالغة، وعند المقاييس المتطرفة البالغة 500 ألف، يخفض FlashMemory الأعباء الإضافية الفيزيائية لذاكرة التخزين المؤقت للـ KV بأكثر من 90%، دون المساس بقدرات الاستدلال الأساسية للنموذج الأساسي.
One-sentence Summary
FlashMemory-DeepSeek-V4 implements Lookahead Sparse Attention via a decoupled dual-encoder indexer that proactively retains only query-critical KV chunks, compressing the physical cache footprint to 13.5% of the baseline and yielding a +0.6% average accuracy gain across 500K-token contexts on LongBench-v2, LongMemEval, and RULER without loading the backbone model during training.
Key Contributions
- The paper introduces Lookahead Sparse Attention (LSA), an inference paradigm that proactively predicts context demands and selectively retains only query-critical KV chunks to circumvent the linear GPU memory scaling bottleneck. This method upgrades conventional compressed sparse attention layers with a predictive indexing mechanism that periodically fetches essential historical tokens during decoding.
- A backbone-free decoupled training strategy is presented that formulates the neural memory indexer as a standalone dual-encoder architecture. This design enables independent optimization via standard retrieval frameworks without requiring the massive language model backbone to occupy GPU memory during training.
- Evaluations across LongBench-v2, LongMemEval, and RULER demonstrate that the approach compresses the physical KV cache footprint to 13.5% of the full-context baseline while improving average downstream accuracy by 0.6%. At 500K context lengths, the method suppresses memory overhead by over 90% without destabilizing the backbone's core reasoning capabilities.
Introduction
Extending large language models to ultra-long context windows is essential for complex reasoning and document analysis, yet GPU memory constraints remain a critical bottleneck due to the linear scaling of the key-value cache. Prior solutions that incorporate heavily compressed or linear attention layers only mitigate this memory explosion rather than resolving it, and they waste substantial compute by retaining inactive context that does not influence current token predictions. The authors leverage a predictive Lookahead Sparse Attention mechanism paired with a standalone dual-encoder memory indexer to solve this dilemma. This system periodically evaluates hidden states to proactively fetch only the most relevant sparse attention chunks into GPU memory, completely decoupling indexer training from full-model fine-tuning. By dynamically loading critical context while discarding inactive history, the approach reduces GPU memory consumption by up to 90 percent and improves accuracy across standard long-context benchmarks.
Dataset
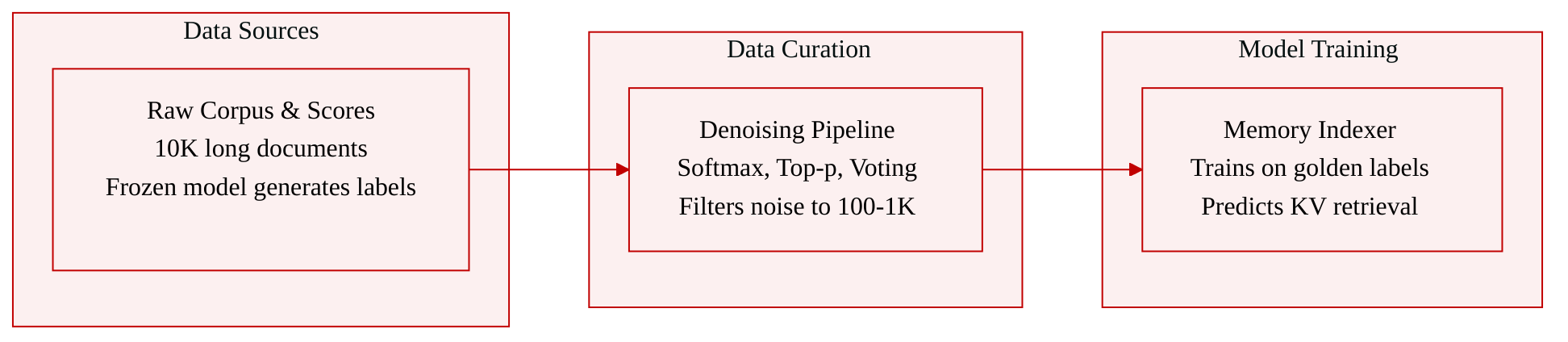
- Dataset Composition and Sources: The authors compile a training corpus of approximately 10,000 long documents with context lengths spanning 16K to 512K tokens. All ground-truth labels are generated offline using a frozen DeepSeek-V4-Flash backbone model.
- Key Details and Filtering Rules: To resolve severe noise inflation from rigid Top-k selectors, the authors apply a three-step denoising pipeline that reduces positive samples per token window from roughly 10,000 down to 100 to 1,000. The pipeline first normalizes raw indexer logit scores via Softmax, then dynamically retains high-confidence entries using a nucleus threshold of 0.6, and finally applies Cross-Layer Majority Voting across all 21 CSA layers. An entry qualifies as a golden positive sample only if it secures consensus from at least three layers.
- Training Usage and Processing: The filtered dataset trains the Memory Indexer to predict which historical compressed KV entries each decoding token must retrieve. The authors use the consensus-driven golden entries to form the positive ground-truth label set for every decoding step, replacing arbitrary fixed-count lookups with a density estimation approach that isolates the true contextual backbone. No explicit mixture ratios are specified, as the model trains on this unified denoised corpus.
- Metadata Construction and Windowing: Label metadata is built by extracting logit scores for every preceding compressed entry across all attention layers for each token in a fixed future temporal window τ. The system aggregates these cross-layer votes into token-level golden sets, then unions them across the entire lookahead window to establish the final positive label set. The pipeline natively handles variable context lengths without requiring explicit cropping strategies.
Method
The authors leverage the Lookahead Sparse Attention (LSA) paradigm to address the GPU memory bottleneck in ultra-long context serving by introducing a Neural Memory Indexer that operates in conjunction with the DeepSeek-V4 architecture. The core mechanism of LSA is designed to minimize modifications to the base model while enabling proactive selection of query-critical key-value (KV) chunks, thereby reducing the physical KV cache footprint. As shown in the figure below, the framework operates in a tiered manner during autoregressive decoding, where the Memory Indexer periodically triggers at fixed intervals τ (e.g., τ=64) to predict which historical KV entries are relevant for the upcoming decoding window.
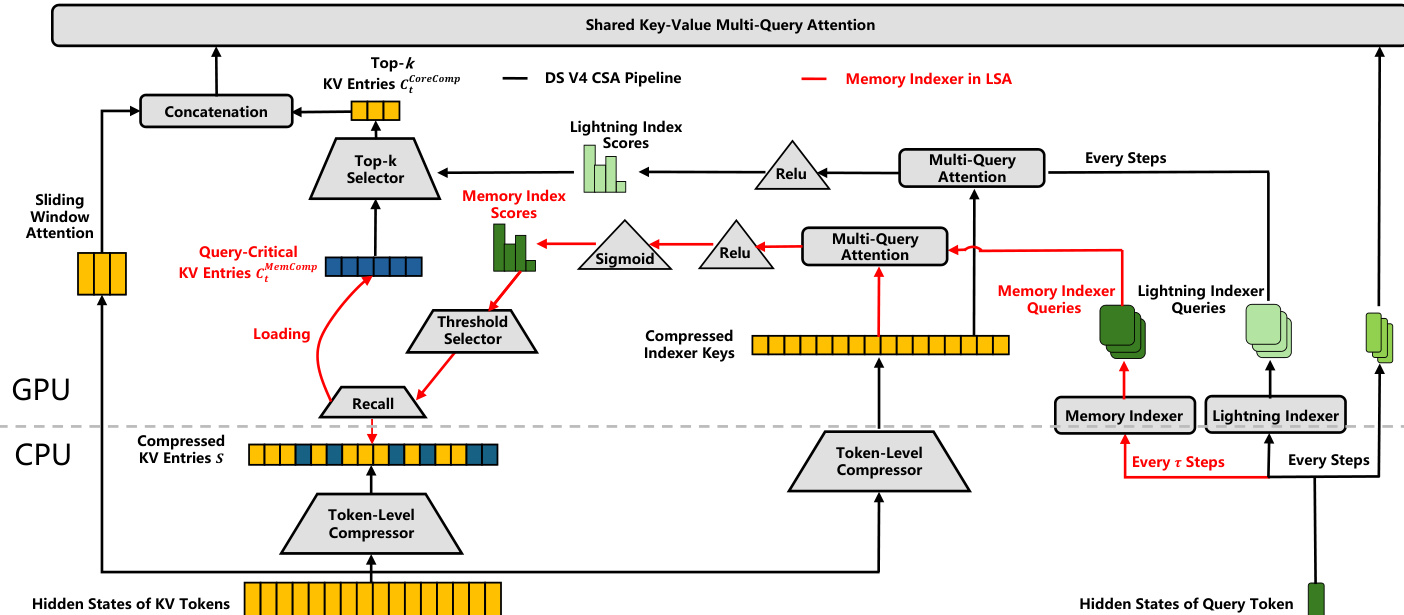
At each triggering step t, the current query token’s hidden state ht∈Rd is projected into low-rank indexer queries via a down-projection matrix WDQ and an up-projection matrix WIUQ, producing qtl across nhl indexer heads. Simultaneously, routing head weights wtl are computed using a learnable matrix Ww, which dynamically scales the importance of each indexer head. The lookahead index score It,s between query t and a preceding compressed KV entry s is computed as a head-fused gated matching score, with a Sigmoid activation applied to normalize the output into the (0,1) range. This Sigmoid activation is the only architectural departure from the native Lightning Indexer, aligning the scores with binary classification targets.
The Memory Indexer employs a threshold-based mechanism to recall a dynamic number of historical entries, fetching all compressed KV entries whose lookahead scores meet or exceed a classification threshold of 0.5. This subset, denoted CtMemComp, is loaded from the CPU Cold Pool into GPU memory. Once resident, the native Lightning Indexer performs token-level matching within this restricted subset to select the final fine-grained Top-k core compressed entries. These are concatenated with the non-offloadable sliding window KV cache, enabling the core attention computation to operate exclusively on a highly condensed active sequence footprint.
The Memory Indexer is trained independently of the backbone LLM using a decoupled, backbone-free strategy. The compressed indexer keys KsIComp of historical entries are pre-computed and frozen during training, reducing the optimization problem to training only the query encoder of a dual-encoder retrieval architecture. The trainable parameters consist solely of the projection matrices WDQ, WIUQ, and Ww, which are optimized via a standard Binary Cross-Entropy (BCE) loss over predicted lookahead scores. The training pipeline achieves complete physical isolation from the massive backbone model, as the full LLM is never loaded into GPU memory. This allows the indexer to be trained efficiently on a single H20 GPU within a single hour.
To optimize the architecture, the authors conduct a systematic exploration of the layer configuration. They find that placing Memory Indexers on shallow layers yields poor performance due to insufficient global context awareness, while an excessive number of layers degrades efficiency. Through extensive Pareto-frontier optimization, they determine that deploying independent indexers on three strategic intermediate layers—layers 10, 12, and 20—provides the optimal balance between performance and efficiency. During inference, the system aggregates predictions from these three layers using a union operation (OR-mode routing), ensuring that a KV entry is fetched if at least one indexer predicts It,s(l)≥0.5. This 3-layer consensus framework acts as a robust fallback protection boundary.
The final training strategy incorporates random initialization of the indexer’s projection matrices to avoid alignment bias, leverages the native low-rank query projection geometry of DeepSeek-V4 by increasing the internal projection dimension to r=2048, and employs Focal Loss to mitigate gradient dominance from easy negative samples. These design choices enable a lightweight, highly efficient training process that does not require end-to-end distillation or joint optimization with the backbone.
Experiment
The evaluation benchmarks the FlashMemory paradigm against structural variants and heuristic controls to validate its dynamic retrieval mechanism across diverse long-context scenarios. Primary results demonstrate that selective indexing significantly reduces memory overhead while improving performance by acting as an attention denoiser, whereas static baselines fail to preserve coherence under constrained resources. Subsequent experiments reveal that the indexer accumulates marginal false-positive retrievals in strictly context-independent tasks, struggles with benchmarks requiring dense global memory dependencies, and experiences retrieval degradation beyond twice its training sequence length due to positional embedding limitations. Collectively, these findings confirm the paradigm's effectiveness as a sparse attention filter while identifying architectural boundaries in cross-interaction depth, joint optimization, and length generalization that require future refinement.
The authors evaluate the FlashMemory paradigm against baseline models on context-independent tasks, focusing on memory efficiency and performance. Results show that the proposed FM-DS-V4 model maintains competitive accuracy while significantly reducing GPU memory usage compared to the DS-V4-Flash baseline, particularly under no-context conditions. However, the model's memory footprint increases with longer contexts despite low retrieval ratios, indicating inefficiencies in handling irrelevant historical chunks. FM-DS-V4 achieves near-baseline accuracy with substantially lower GPU memory usage on context-independent tasks. Memory consumption increases with context length despite low retrieval ratios, suggesting inefficiencies in filtering irrelevant chunks. The model maintains performance under no-context conditions but fails to achieve a constant memory overhead due to marginal false-positive retrievals.

The authors evaluate the FlashMemory paradigm against several structural variants, focusing on performance and memory efficiency across long-context benchmarks. Results show that the proposed method achieves significant memory reduction while maintaining or improving performance, particularly in ultra-long context settings, though it exhibits limitations in context-independent and dense memory scenarios. The model's performance degrades when the context length exceeds its trained capacity, indicating a generalization ceiling. The FlashMemory paradigm achieves substantial memory reduction while outperforming the baseline in long-context tasks. The model's performance collapses on dense memory tasks and fails to maintain constant memory overhead in context-independent scenarios. The model's generalization is limited to twice its training context length, beyond which accuracy degrades sharply.
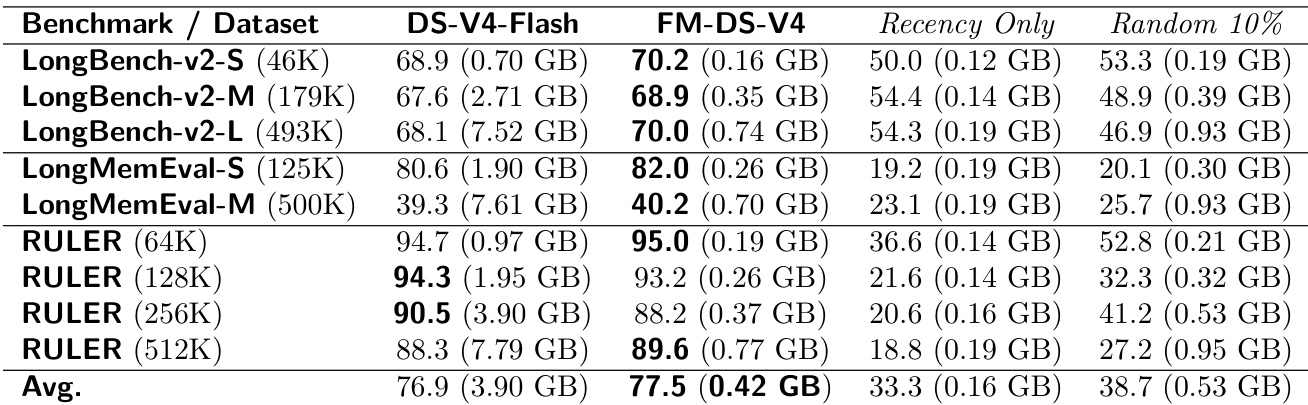
The authors evaluate the FlashMemory paradigm against baseline models and structural variants across context-independent tasks and long-context benchmarks to assess memory efficiency and performance trade-offs. The approach demonstrates substantial memory savings while maintaining or enhancing accuracy in extended context scenarios, though it struggles to maintain constant memory overhead due to inefficiencies in filtering irrelevant historical chunks. Additionally, performance deteriorates on dense memory tasks, and generalization is constrained to approximately twice the training context length, beyond which accuracy declines sharply. Overall, the paradigm proves highly effective for long-context applications but faces notable limitations in context-independent and dense retrieval settings.